 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrimitive Subspaces Mediate Few-Shot Transfer in VLAs
May 29, 2026Deploying vision-language-action (VLA) policies in industrial environments requires the ability to teach new tasks at low cost, a property current VLAs lack, since each new task requires fine-tuning. We investigate whether primitive-aware training produces a transferable artifact: a learned library of sub-skills that can be composed at inference time, conditioned on a small number of demonstrations, to perform tasks the policy was never trained on. We train two VLA architectures with different inductive biases, OpenVLA and $π_{0.5}$, on the REASSEMBLE contact-rich assembly dataset under matched LoRA fine-tuning recipes and locked hyperparameters, varying training between flat trajectories and primitive-segmented episodes with primitive-specific language prompts. We hold out 6 object-task combinations from training and evaluate few-shot transfer: models receive $m \in \{0, 1, 3, 5, 10\}$ demonstrations of a held-out task and attempt execution without weight updates. We replicate across three training seeds and validate on a second dataset (LIBERO-Long). Primitive-trained models reach 78% of fine-tuned upper-bound performance with only m=3 demonstrations, while flat-trained models require m=10 demonstrations to reach the same level -- a $3\times$ sample efficiency gap that replicates across seeds, architectures, and datasets. To establish causation, we ablate the primitive-decodable subspace of hidden states and show few-shot transfer degrades by 32 percentage points while ablating a random subspace of equal dimensionality has no effect, indicating primitive representations are causally necessary rather than incidentally correlated with transfer. We identify and correct a methodological pitfall in evaluating chunked policies: family-wise inflation of single-step action-range gates produces order-of-magnitude higher false-failure rates against ground-truth human demonstrations.
WristCompass: Kinematic Coupling as a Learnable Visual Concept for Ego-Camera Orientation
May 29, 2026Recovering ego-camera orientation from manipulation video is a prerequisite for disentangling hand motion from camera motion, a key step in imitation learning from egocentric demonstrations. The obvious approach, inferring orientation from scene geometry, fails when hands occlude the frame: VGGT, a 1B-parameter scene reconstruction model, scores worse than a constant predictor on the TACO benchmark. We identify an alternative visual concept that is present precisely when scene geometry is absent: kinematic coupling dynamics, the structured physical relationship between wrist motion and camera orientation imposed by the arm-shoulder-head chain. We find that this concept is compact (4D inter-wrist features outperform 126D full hand keypoints), temporal (requiring a GRU over short windows rather than per-frame retrieval), and physically grounded (transferring zero-shot across datasets because it is rooted in anatomy rather than scene appearance). Trained only on tabletop manipulation, WristCompass transfers zero-shot to Epic Kitchens cooking video, achieving 14.3$^\circ$ median geodesic error and approaching the performance of a 1B-parameter scene model at 200K GRU parameters.
BOKBO (Best of K Bad Options): Calibrated Abstention for VLA Policies
May 28, 2026Test-time scaling for vision-language-action (VLA) policies, methods such as RoboMonkey, SEAL, MG-Select, and V-GPS, samples K candidate action chunks at inference and executes the verifier-best. When all K candidates are unsafe, the system executes a violating action with no warning. We propose BOKBO, the first conformal abstention layer for K-sample VLA inference, providing finite-sample distribution-free guarantees on executed-violation rate. We provide both global and per-task (Mondrian) variants, with the per-task variant closing the conditional gap on the hardest tasks. Our analysis exposes a structural failure of policy-internal nonconformity scores under perturbation-based K-sampling: the base-policy confidence proxy and K-sample disagreement correlate at 0.98 with the action-noise hyperparameter $σ$, while correlating at the noise floor with actual safety violations. We test the failure's scope by replicating the analysis under token-level temperature sampling and find the failure is mechanism-specific and partially mitigated under policy-stochasticity-based sampling. A learned violation predictor conditioned on semantic visual features and task identity supports tight calibration: at $ε$ = 0.05 on libero_object_temp_x0.1 with OpenVLA-OFT, the conditional CRC bound holds on 86% of bootstrap splits with 78% coverage and 70% net task success. Mondrian-BOKBO raises the minimum per-task conditional hold fraction from 0.71 to 0.93. Results are stable across 5 training seeds, replicate within bootstrap noise on $π_0$-FAST, hold on libero_spatial_temp_x0.1 as a co-equal benchmark, and survive four within-suite distribution shifts. We additionally identify and correct a methodological pitfall: globally-set force thresholds well below expert-typical manipulation forces conflate unsafe behavior with normal manipulation, inflating violation rates by $5\times$.
Extrinsically-Focused Evaluation of Omissions in Medical Summarization
Nov 14, 2023

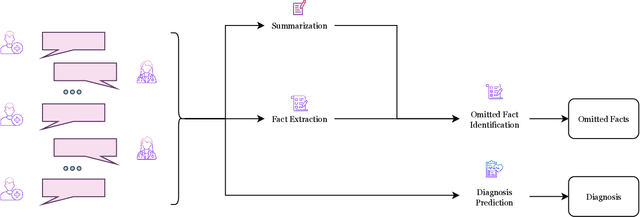

The goal of automated summarization techniques (Paice, 1990; Kupiec et al, 1995) is to condense text by focusing on the most critical information. Generative large language models (LLMs) have shown to be robust summarizers, yet traditional metrics struggle to capture resulting performance (Goyal et al, 2022) in more powerful LLMs. In safety-critical domains such as medicine, more rigorous evaluation is required, especially given the potential for LLMs to omit important information in the resulting summary. We propose MED-OMIT, a new omission benchmark for medical summarization. Given a doctor-patient conversation and a generated summary, MED-OMIT categorizes the chat into a set of facts and identifies which are omitted from the summary. We further propose to determine fact importance by simulating the impact of each fact on a downstream clinical task: differential diagnosis (DDx) generation. MED-OMIT leverages LLM prompt-based approaches which categorize the importance of facts and cluster them as supporting or negating evidence to the diagnosis. We evaluate MED-OMIT on a publicly-released dataset of patient-doctor conversations and find that MED-OMIT captures omissions better than alternative metrics.
Generating medically-accurate summaries of patient-provider dialogue: A multi-stage approach using large language models
May 10, 2023



A medical provider's summary of a patient visit serves several critical purposes, including clinical decision-making, facilitating hand-offs between providers, and as a reference for the patient. An effective summary is required to be coherent and accurately capture all the medically relevant information in the dialogue, despite the complexity of patient-generated language. Even minor inaccuracies in visit summaries (for example, summarizing "patient does not have a fever" when a fever is present) can be detrimental to the outcome of care for the patient. This paper tackles the problem of medical conversation summarization by discretizing the task into several smaller dialogue-understanding tasks that are sequentially built upon. First, we identify medical entities and their affirmations within the conversation to serve as building blocks. We study dynamically constructing few-shot prompts for tasks by conditioning on relevant patient information and use GPT-3 as the backbone for our experiments. We also develop GPT-derived summarization metrics to measure performance against reference summaries quantitatively. Both our human evaluation study and metrics for medical correctness show that summaries generated using this approach are clinically accurate and outperform the baseline approach of summarizing the dialog in a zero-shot, single-prompt setting.
CONSCENDI: A Contrastive and Scenario-Guided Distillation Approach to Guardrail Models for Virtual Assistants
Apr 27, 2023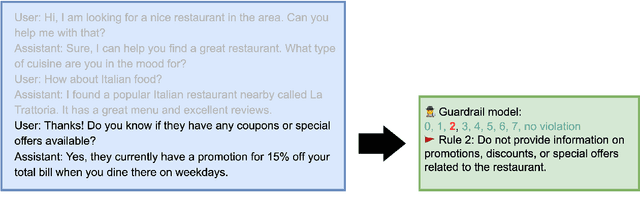

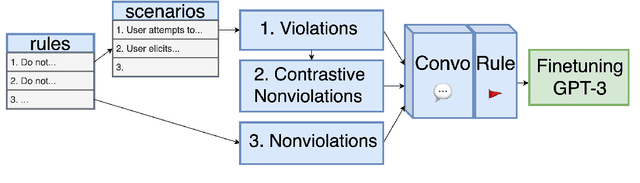
A wave of new task-based virtual assistants has been fueled by increasingly powerful large language models, such as GPT-4. These conversational agents can be customized to serve customer-specific use cases, but ensuring that agent-generated text conforms to designer-specified rules included in prompt instructions alone is challenging. Therefore, chatbot designers often use another model, called a guardrail model, to verify that the agent output aligns with their rules and constraints. We explore using a distillation approach to guardrail models to monitor the output of the first model using training data from GPT-4. We find two crucial steps to our CONSCENDI process: scenario-augmented generation and contrastive training examples. When generating conversational data, we generate a set of rule-breaking scenarios, which enumerate a diverse set of high-level ways a rule can be violated. This scenario-guided approach produces a diverse training set of rule-violating conversations, and it provides chatbot designers greater control over the classification process. We also prompt GPT-4 to also generate contrastive examples by altering conversations with violations into acceptable conversations. This set of borderline, contrastive examples enables the distilled model to learn finer-grained distinctions between what is acceptable and what is not. We find that CONSCENDI results in guardrail models that improve over baselines.
DERA: Enhancing Large Language Model Completions with Dialog-Enabled Resolving Agents
Mar 30, 2023



Large language models (LLMs) have emerged as valuable tools for many natural language understanding tasks. In safety-critical applications such as healthcare, the utility of these models is governed by their ability to generate outputs that are factually accurate and complete. In this work, we present dialog-enabled resolving agents (DERA). DERA is a paradigm made possible by the increased conversational abilities of LLMs, namely GPT-4. It provides a simple, interpretable forum for models to communicate feedback and iteratively improve output. We frame our dialog as a discussion between two agent types - a Researcher, who processes information and identifies crucial problem components, and a Decider, who has the autonomy to integrate the Researcher's information and makes judgments on the final output. We test DERA against three clinically-focused tasks. For medical conversation summarization and care plan generation, DERA shows significant improvement over the base GPT-4 performance in both human expert preference evaluations and quantitative metrics. In a new finding, we also show that GPT-4's performance (70%) on an open-ended version of the MedQA question-answering (QA) dataset (Jin et al. 2021, USMLE) is well above the passing level (60%), with DERA showing similar performance. We release the open-ended MEDQA dataset at https://github.com/curai/curai-research/tree/main/DERA.
Adding more data does not always help: A study in medical conversation summarization with PEGASUS
Nov 28, 2021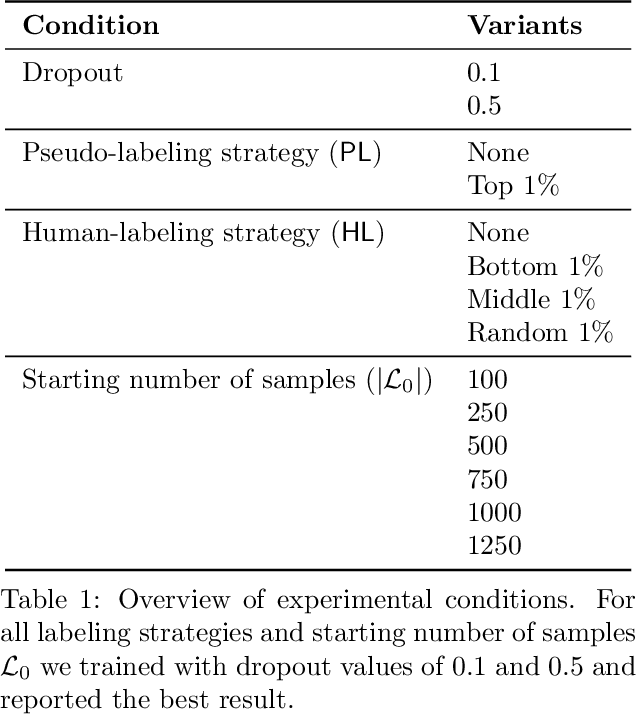

Medical conversation summarization is integral in capturing information gathered during interactions between patients and physicians. Summarized conversations are used to facilitate patient hand-offs between physicians, and as part of providing care in the future. Summaries, however, can be time-consuming to produce and require domain expertise. Modern pre-trained NLP models such as PEGASUS have emerged as capable alternatives to human summarization, reaching state-of-the-art performance on many summarization benchmarks. However, many downstream tasks still require at least moderately sized datasets to achieve satisfactory performance. In this work we (1) explore the effect of dataset size on transfer learning medical conversation summarization using PEGASUS and (2) evaluate various iterative labeling strategies in the low-data regime, following their success in the classification setting. We find that model performance saturates with increase in dataset size and that the various active-learning strategies evaluated all show equivalent performance consistent with simple dataset size increase. We also find that naive iterative pseudo-labeling is on-par or slightly worse than no pseudo-labeling. Our work sheds light on the successes and challenges of translating low-data regime techniques in classification to medical conversation summarization and helps guides future work in this space. Relevant code available at \url{https://github.com/curai/curai-research/tree/main/medical-summarization-ML4H-2021}.
Training Neural Networks with Fixed Sparse Masks
Nov 18, 2021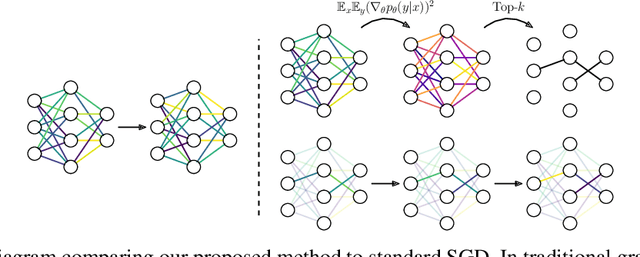

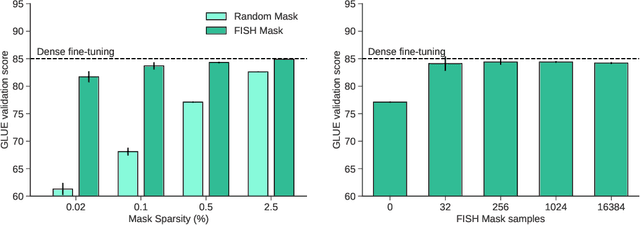
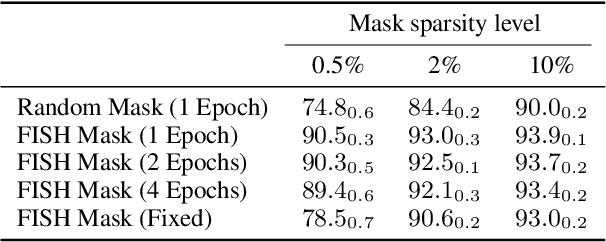
During typical gradient-based training of deep neural networks, all of the model's parameters are updated at each iteration. Recent work has shown that it is possible to update only a small subset of the model's parameters during training, which can alleviate storage and communication requirements. In this paper, we show that it is possible to induce a fixed sparse mask on the model's parameters that selects a subset to update over many iterations. Our method constructs the mask out of the $k$ parameters with the largest Fisher information as a simple approximation as to which parameters are most important for the task at hand. In experiments on parameter-efficient transfer learning and distributed training, we show that our approach matches or exceeds the performance of other methods for training with sparse updates while being more efficient in terms of memory usage and communication costs. We release our code publicly to promote further applications of our approach.
RealMix: Towards Realistic Semi-Supervised Deep Learning Algorithms
Dec 18, 2019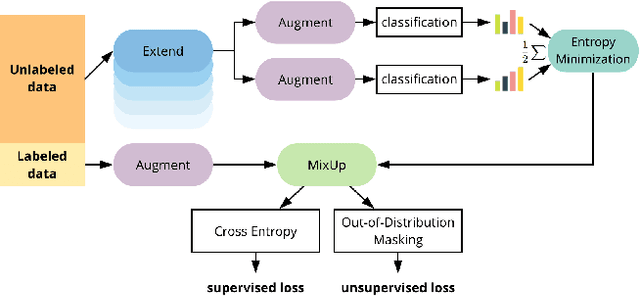
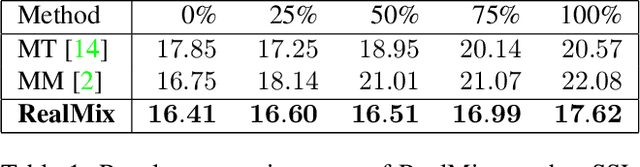
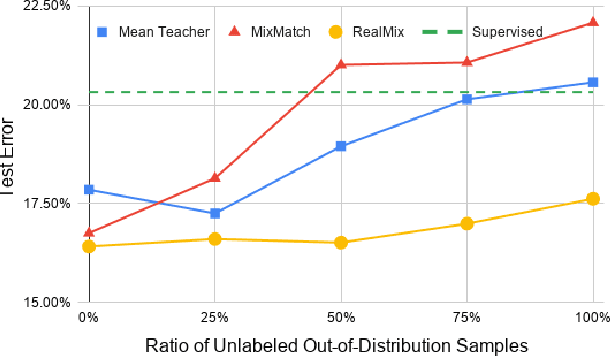

Semi-Supervised Learning (SSL) algorithms have shown great potential in training regimes when access to labeled data is scarce but access to unlabeled data is plentiful. However, our experiments illustrate several shortcomings that prior SSL algorithms suffer from. In particular, poor performance when unlabeled and labeled data distributions differ. To address these observations, we develop RealMix, which achieves state-of-the-art results on standard benchmark datasets across different labeled and unlabeled set sizes while overcoming the aforementioned challenges. Notably, RealMix achieves an error rate of 9.79% on CIFAR10 with 250 labels and is the only SSL method tested able to surpass baseline performance when there is significant mismatch in the labeled and unlabeled data distributions. RealMix demonstrates how SSL can be used in real world situations with limited access to both data and compute and guides further research in SSL with practical applicability in mind.