 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Neural Networks with Fixed Sparse Masks
Paper and Code
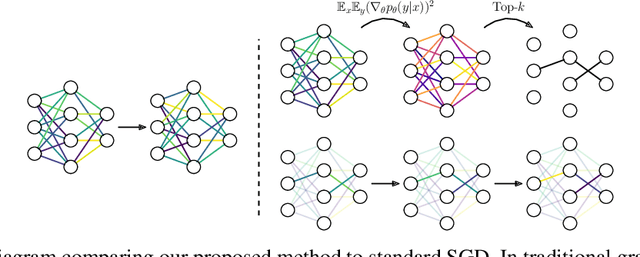

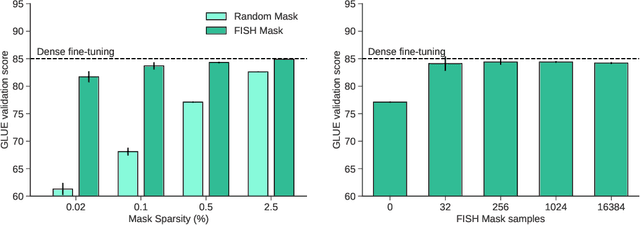
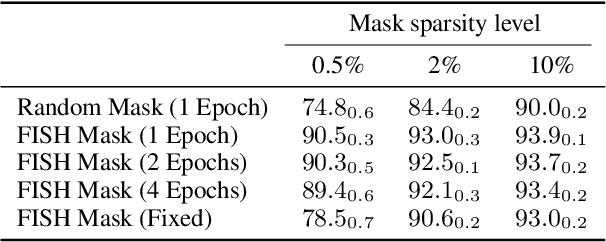
During typical gradient-based training of deep neural networks, all of the model's parameters are updated at each iteration. Recent work has shown that it is possible to update only a small subset of the model's parameters during training, which can alleviate storage and communication requirements. In this paper, we show that it is possible to induce a fixed sparse mask on the model's parameters that selects a subset to update over many iterations. Our method constructs the mask out of the $k$ parameters with the largest Fisher information as a simple approximation as to which parameters are most important for the task at hand. In experiments on parameter-efficient transfer learning and distributed training, we show that our approach matches or exceeds the performance of other methods for training with sparse updates while being more efficient in terms of memory usage and communication costs. We release our code publicly to promote further applications of our approach.