 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtrinsically-Focused Evaluation of Omissions in Medical Summarization
Nov 14, 2023

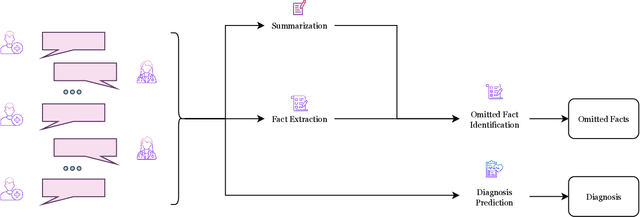

The goal of automated summarization techniques (Paice, 1990; Kupiec et al, 1995) is to condense text by focusing on the most critical information. Generative large language models (LLMs) have shown to be robust summarizers, yet traditional metrics struggle to capture resulting performance (Goyal et al, 2022) in more powerful LLMs. In safety-critical domains such as medicine, more rigorous evaluation is required, especially given the potential for LLMs to omit important information in the resulting summary. We propose MED-OMIT, a new omission benchmark for medical summarization. Given a doctor-patient conversation and a generated summary, MED-OMIT categorizes the chat into a set of facts and identifies which are omitted from the summary. We further propose to determine fact importance by simulating the impact of each fact on a downstream clinical task: differential diagnosis (DDx) generation. MED-OMIT leverages LLM prompt-based approaches which categorize the importance of facts and cluster them as supporting or negating evidence to the diagnosis. We evaluate MED-OMIT on a publicly-released dataset of patient-doctor conversations and find that MED-OMIT captures omissions better than alternative metrics.
DERA: Enhancing Large Language Model Completions with Dialog-Enabled Resolving Agents
Mar 30, 2023



Large language models (LLMs) have emerged as valuable tools for many natural language understanding tasks. In safety-critical applications such as healthcare, the utility of these models is governed by their ability to generate outputs that are factually accurate and complete. In this work, we present dialog-enabled resolving agents (DERA). DERA is a paradigm made possible by the increased conversational abilities of LLMs, namely GPT-4. It provides a simple, interpretable forum for models to communicate feedback and iteratively improve output. We frame our dialog as a discussion between two agent types - a Researcher, who processes information and identifies crucial problem components, and a Decider, who has the autonomy to integrate the Researcher's information and makes judgments on the final output. We test DERA against three clinically-focused tasks. For medical conversation summarization and care plan generation, DERA shows significant improvement over the base GPT-4 performance in both human expert preference evaluations and quantitative metrics. In a new finding, we also show that GPT-4's performance (70%) on an open-ended version of the MedQA question-answering (QA) dataset (Jin et al. 2021, USMLE) is well above the passing level (60%), with DERA showing similar performance. We release the open-ended MEDQA dataset at https://github.com/curai/curai-research/tree/main/DERA.