 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCONSCENDI: A Contrastive and Scenario-Guided Distillation Approach to Guardrail Models for Virtual Assistants
Paper and Code
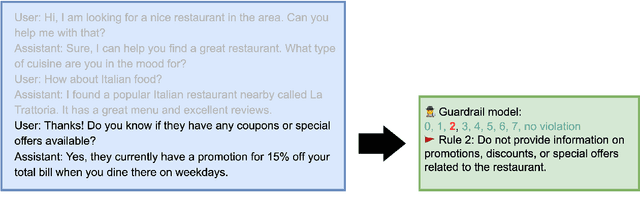

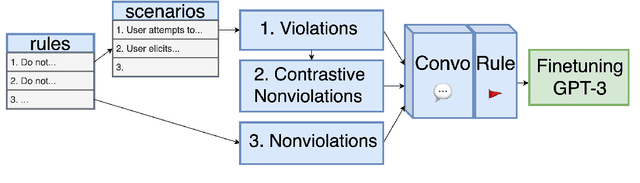
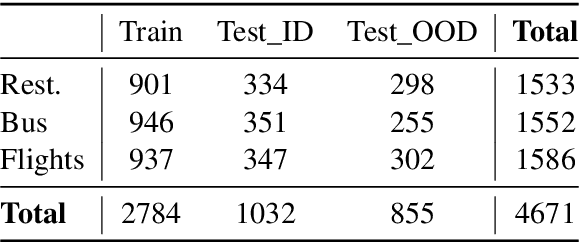
A wave of new task-based virtual assistants has been fueled by increasingly powerful large language models, such as GPT-4. These conversational agents can be customized to serve customer-specific use cases, but ensuring that agent-generated text conforms to designer-specified rules included in prompt instructions alone is challenging. Therefore, chatbot designers often use another model, called a guardrail model, to verify that the agent output aligns with their rules and constraints. We explore using a distillation approach to guardrail models to monitor the output of the first model using training data from GPT-4. We find two crucial steps to our CONSCENDI process: scenario-augmented generation and contrastive training examples. When generating conversational data, we generate a set of rule-breaking scenarios, which enumerate a diverse set of high-level ways a rule can be violated. This scenario-guided approach produces a diverse training set of rule-violating conversations, and it provides chatbot designers greater control over the classification process. We also prompt GPT-4 to also generate contrastive examples by altering conversations with violations into acceptable conversations. This set of borderline, contrastive examples enables the distilled model to learn finer-grained distinctions between what is acceptable and what is not. We find that CONSCENDI results in guardrail models that improve over baselines.