 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealMix: Towards Realistic Semi-Supervised Deep Learning Algorithms
Dec 18, 2019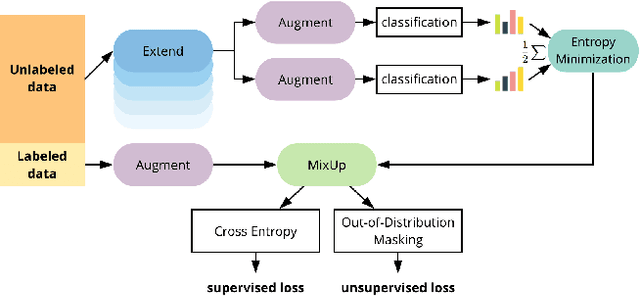
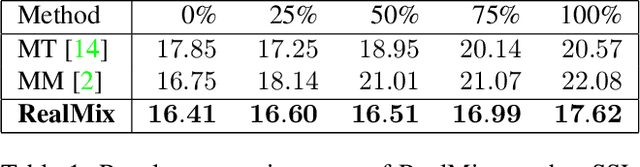
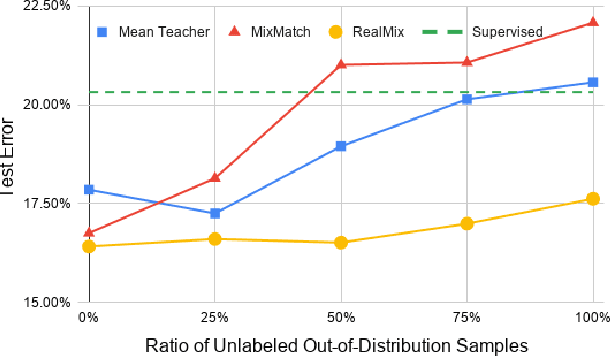

Semi-Supervised Learning (SSL) algorithms have shown great potential in training regimes when access to labeled data is scarce but access to unlabeled data is plentiful. However, our experiments illustrate several shortcomings that prior SSL algorithms suffer from. In particular, poor performance when unlabeled and labeled data distributions differ. To address these observations, we develop RealMix, which achieves state-of-the-art results on standard benchmark datasets across different labeled and unlabeled set sizes while overcoming the aforementioned challenges. Notably, RealMix achieves an error rate of 9.79% on CIFAR10 with 250 labels and is the only SSL method tested able to surpass baseline performance when there is significant mismatch in the labeled and unlabeled data distributions. RealMix demonstrates how SSL can be used in real world situations with limited access to both data and compute and guides further research in SSL with practical applicability in mind.