 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe-Dock: Towards Flexible and Realistic Molecular Docking with Diffusion Bridge
Feb 21, 2024Accurate prediction of protein-ligand binding structures, a task known as molecular docking is crucial for drug design but remains challenging. While deep learning has shown promise, existing methods often depend on holo-protein structures (docked, and not accessible in realistic tasks) or neglect pocket sidechain conformations, leading to limited practical utility and unrealistic conformation predictions. To fill these gaps, we introduce an under-explored task, named flexible docking to predict poses of ligand and pocket sidechains simultaneously and introduce Re-Dock, a novel diffusion bridge generative model extended to geometric manifolds. Specifically, we propose energy-to-geometry mapping inspired by the Newton-Euler equation to co-model the binding energy and conformations for reflecting the energy-constrained docking generative process. Comprehensive experiments on designed benchmark datasets including apo-dock and cross-dock demonstrate our model's superior effectiveness and efficiency over current methods.
Architecture-Agnostic Masked Image Modeling -- From ViT back to CNN
Jun 01, 2022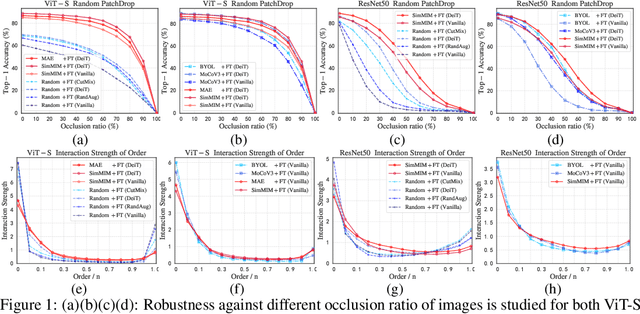
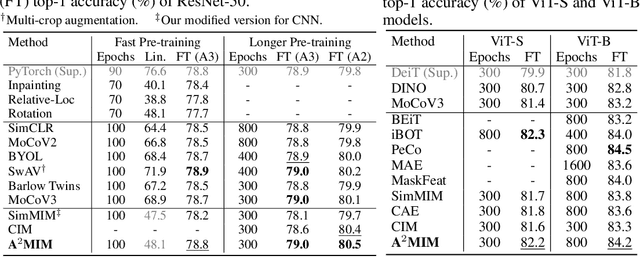

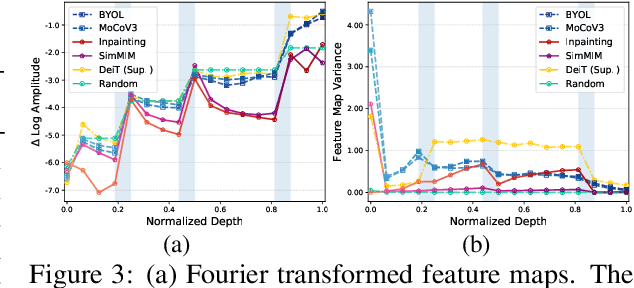
Masked image modeling (MIM), an emerging self-supervised pre-training method, has shown impressive success across numerous downstream vision tasks with Vision transformers (ViT). Its underlying idea is simple: a portion of the input image is randomly masked out and then reconstructed via the pre-text task. However, why MIM works well is not well explained, and previous studies insist that MIM primarily works for the Transformer family but is incompatible with CNNs. In this paper, we first study interactions among patches to understand what knowledge is learned and how it is acquired via the MIM task. We observe that MIM essentially teaches the model to learn better middle-level interactions among patches and extract more generalized features. Based on this fact, we propose an Architecture-Agnostic Masked Image Modeling framework (A$^2$MIM), which is compatible with not only Transformers but also CNNs in a unified way. Extensive experiments on popular benchmarks show that our A$^2$MIM learns better representations and endows the backbone model with the stronger capability to transfer to various downstream tasks for both Transformers and CNNs.
An Empirical Study: Extensive Deep Temporal Point Process
Oct 25, 2021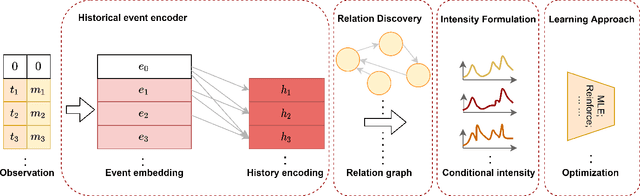
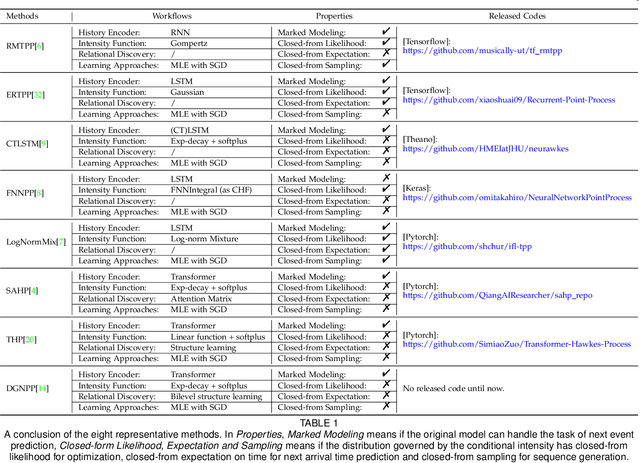
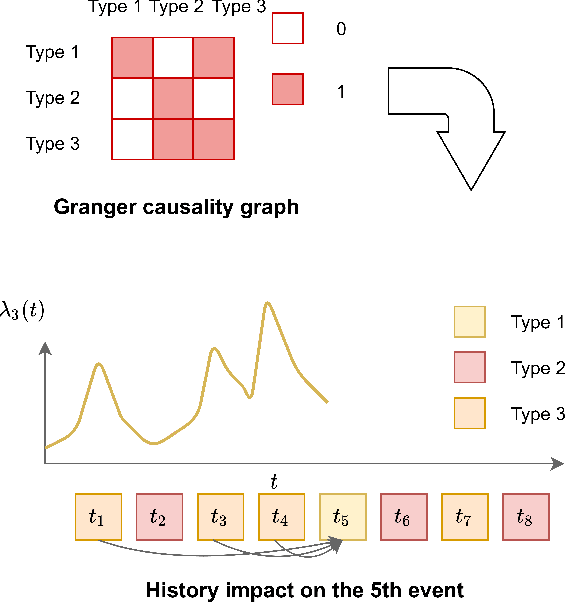
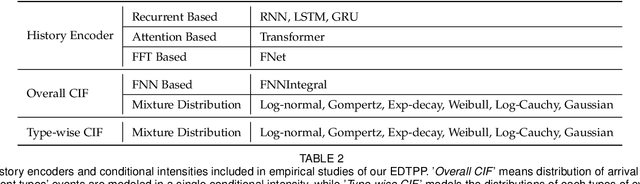
Temporal point process as the stochastic process on continuous domain of time is commonly used to model the asynchronous event sequence featuring with occurrence timestamps. Thanks to the strong expressivity of deep neural networks, they are emerging as a promising choice for capturing the patterns in asynchronous sequences, in the context of temporal point process. In this paper, we first review recent research emphasis and difficulties in modeling asynchronous event sequences with deep temporal point process, which can be concluded into four fields: encoding of history sequence, formulation of conditional intensity function, relational discovery of events and learning approaches for optimization. We introduce most of recently proposed models by dismantling them into the four parts, and conduct experiments by remodularizing the first three parts with the same learning strategy for a fair empirical evaluation. Besides, we extend the history encoders and conditional intensity function family, and propose a Granger causality discovery framework for exploiting the relations among multi-types of events. Because the Granger causality can be represented by the Granger causality graph, discrete graph structure learning in the framework of Variational Inference is employed to reveal latent structures of the graph. Further experiments show that the proposed framework with latent graph discovery can both capture the relations and achieve an improved fitting and predicting performance.
GraphMixup: Improving Class-Imbalanced Node Classification on Graphs by Self-supervised Context Prediction
Jun 21, 2021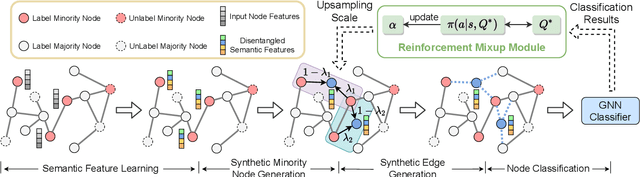

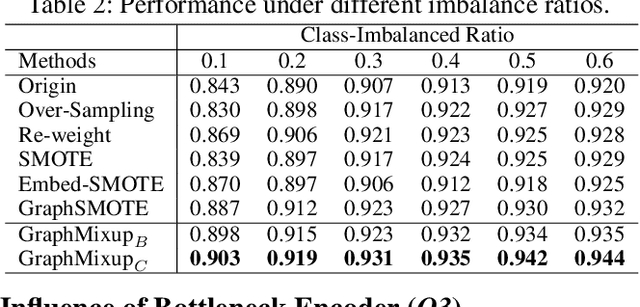
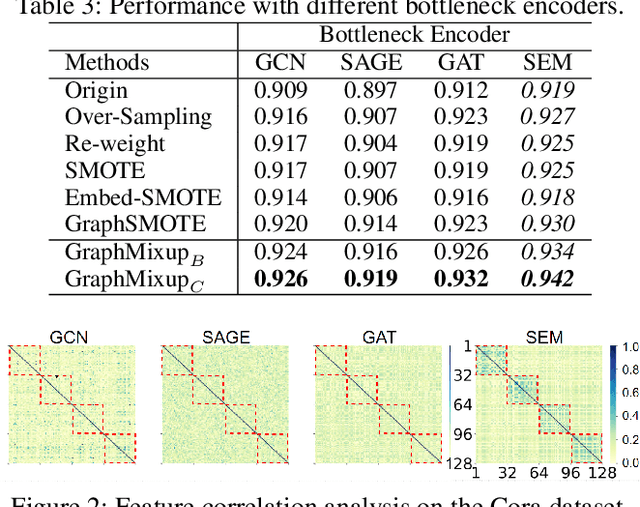
Recent years have witnessed great success in handling node classification tasks with Graph Neural Networks (GNNs). However, most existing GNNs are based on the assumption that node samples for different classes are balanced, while for many real-world graphs, there exists the problem of class imbalance, i.e., some classes may have much fewer samples than others. In this case, directly training a GNN classifier with raw data would under-represent samples from those minority classes and result in sub-optimal performance. This paper presents GraphMixup, a novel mixup-based framework for improving class-imbalanced node classification on graphs. However, directly performing mixup in the input space or embedding space may produce out-of-domain samples due to the extreme sparsity of minority classes; hence we construct semantic relation spaces that allows the Feature Mixup to be performed at the semantic level. Moreover, we apply two context-based self-supervised techniques to capture both local and global information in the graph structure and then propose Edge Mixup specifically for graph data. Finally, we develop a \emph{Reinforcement Mixup} mechanism to adaptively determine how many samples are to be generated by mixup for those minority classes. Extensive experiments on three real-world datasets show that GraphMixup yields truly encouraging results for class-imbalanced node classification tasks.
Self-supervised on Graphs: Contrastive, Generative,or Predictive
May 24, 2021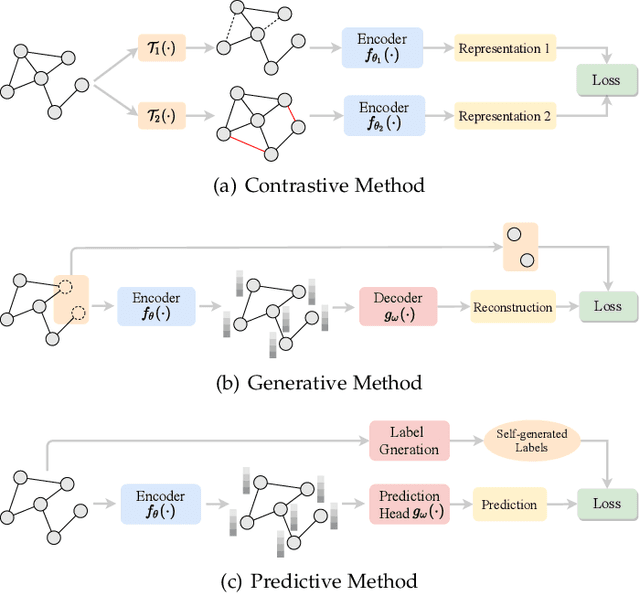

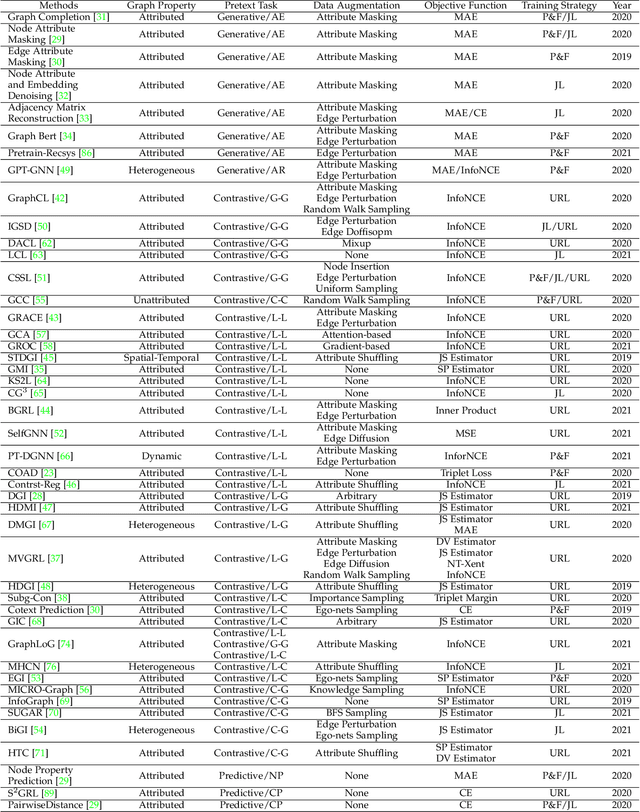
Deep learning on graphs has recently achieved remarkable success on a variety of tasks while such success relies heavily on the massive and carefully labeled data. However, precise annotations are generally very expensive and time-consuming. To address this problem, self-supervised learning (SSL) is emerging as a new paradigm for extracting informative knowledge through well-designed pretext tasks without relying on manual labels. In this survey, we extend the concept of SSL, which first emerged in the fields of computer vision and natural language processing, to present a timely and comprehensive review of the existing SSL techniques for graph data. Specifically, we divide existing graph SSL methods into three categories: contrastive, generative, and predictive. More importantly, unlike many other surveys that only provide a high-level description of published research, we present an additional mathematical summary of the existing works in a unified framework. Furthermore, to facilitate methodological development and empirical comparisons, we also summarize the commonly used datasets, evaluation metrics, downstream tasks, and open-source implementations of various algorithms. Finally, we discuss the technical challenges and potential future directions for improving graph self-supervised learning.
Conditional Local Filters with Explainers for Spatio-Temporal Forecasting
Jan 04, 2021
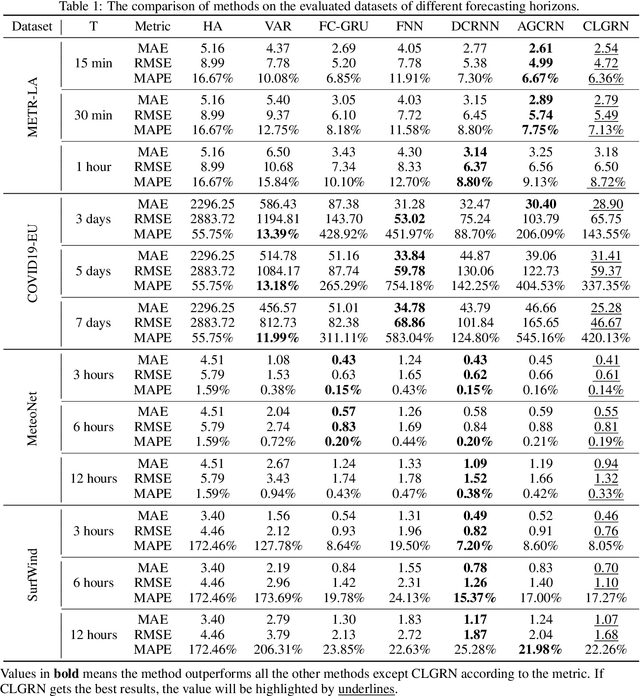
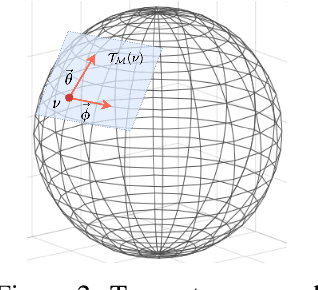

Spatio-temporal prediction is challenging attributing to the high nonlinearity in temporal dynamics as well as complex dependency and location-characterized pattern in spatial domains, especially in fields like geophysics, traffic flow, etc. In this work, a novel graph-based directed convolution is proposed to capture the spatial dependency. To model the variable local pattern, we propose conditional local filters for convolution on the directed graph, parameterized by the functions on local representation of coordinate based on tangent space. The filter is embedded in a Recurrent Neural Network (RNN) architecture for modeling the temporal dynamics with an explainer established for interpretability of different time intervals' pattern. The methods are evaluated on real-world datasets including road network traffic flow, earth surface temperature \& wind flows and disease spread datasets, achieving the state-of-the-art performance with improvements.