 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Prosocial Ranking Challenge: Reducing Polarization on Social Media without Sacrificing Engagement
Mar 20, 2026We report the first direct comparisons of multiple alternative social media algorithms on multiple platforms on outcomes of societal interest. We used a browser extension to modify which posts were shown to desktop social media users, randomly assigning 9,386 users to a control group or one of five alternative ranking algorithms which simultaneously altered content across three platforms for six months during the US 2024 presidential election. This reduced our preregistered index of affective polarization by an average of 0.03 standard deviations (p < 0.05), including a 1.5 degree decrease in differences between the 100 point inparty and outparty feeling thermometers. We saw reductions in active use time for Facebook (-0.37 min/day) and Reddit (-0.2 min/day), but an increase of 0.32 min/day (p < 0.01) for X/Twitter. We saw an increase in reports of negative social media experiences but found no effects on well-being, news knowledge, outgroup empathy, perceptions of and support for partisan violence. This implies that bridging content can improve some societal outcomes without necessarily conflicting with the engagement-driven business model of social media.
Question the Questions: Auditing Representation in Online Deliberative Processes
Nov 06, 2025A central feature of many deliberative processes, such as citizens' assemblies and deliberative polls, is the opportunity for participants to engage directly with experts. While participants are typically invited to propose questions for expert panels, only a limited number can be selected due to time constraints. This raises the challenge of how to choose a small set of questions that best represent the interests of all participants. We introduce an auditing framework for measuring the level of representation provided by a slate of questions, based on the social choice concept known as justified representation (JR). We present the first algorithms for auditing JR in the general utility setting, with our most efficient algorithm achieving a runtime of $O(mn\log n)$, where $n$ is the number of participants and $m$ is the number of proposed questions. We apply our auditing methods to historical deliberations, comparing the representativeness of (a) the actual questions posed to the expert panel (chosen by a moderator), (b) participants' questions chosen via integer linear programming, (c) summary questions generated by large language models (LLMs). Our results highlight both the promise and current limitations of LLMs in supporting deliberative processes. By integrating our methods into an online deliberation platform that has been used for over hundreds of deliberations across more than 50 countries, we make it easy for practitioners to audit and improve representation in future deliberations.
What's In My Human Feedback? Learning Interpretable Descriptions of Preference Data
Oct 30, 2025Human feedback can alter language models in unpredictable and undesirable ways, as practitioners lack a clear understanding of what feedback data encodes. While prior work studies preferences over certain attributes (e.g., length or sycophancy), automatically extracting relevant features without pre-specifying hypotheses remains challenging. We introduce What's In My Human Feedback? (WIMHF), a method to explain feedback data using sparse autoencoders. WIMHF characterizes both (1) the preferences a dataset is capable of measuring and (2) the preferences that the annotators actually express. Across 7 datasets, WIMHF identifies a small number of human-interpretable features that account for the majority of the preference prediction signal achieved by black-box models. These features reveal a wide diversity in what humans prefer, and the role of dataset-level context: for example, users on Reddit prefer informality and jokes, while annotators in HH-RLHF and PRISM disprefer them. WIMHF also surfaces potentially unsafe preferences, such as that LMArena users tend to vote against refusals, often in favor of toxic content. The learned features enable effective data curation: re-labeling the harmful examples in Arena yields large safety gains (+37%) with no cost to general performance. They also allow fine-grained personalization: on the Community Alignment dataset, we learn annotator-specific weights over subjective features that improve preference prediction. WIMHF provides a human-centered analysis method for practitioners to better understand and use preference data.
CTRL-Rec: Controlling Recommender Systems With Natural Language
Oct 14, 2025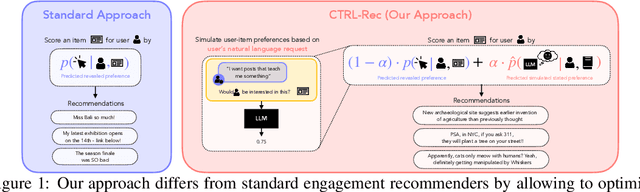



When users are dissatisfied with recommendations from a recommender system, they often lack fine-grained controls for changing them. Large language models (LLMs) offer a solution by allowing users to guide their recommendations through natural language requests (e.g., "I want to see respectful posts with a different perspective than mine"). We propose a method, CTRL-Rec, that allows for natural language control of traditional recommender systems in real-time with computational efficiency. Specifically, at training time, we use an LLM to simulate whether users would approve of items based on their language requests, and we train embedding models that approximate such simulated judgments. We then integrate these user-request-based predictions into the standard weighting of signals that traditional recommender systems optimize. At deployment time, we require only a single LLM embedding computation per user request, allowing for real-time control of recommendations. In experiments with the MovieLens dataset, our method consistently allows for fine-grained control across a diversity of requests. In a study with 19 Letterboxd users, we find that CTRL-Rec was positively received by users and significantly enhanced users' sense of control and satisfaction with recommendations compared to traditional controls.
Choosing the Right Weights: Balancing Value, Strategy, and Noise in Recommender Systems
May 27, 2023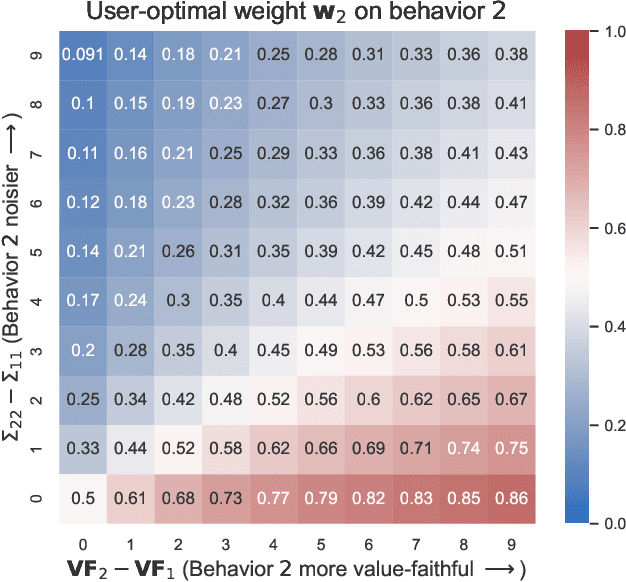

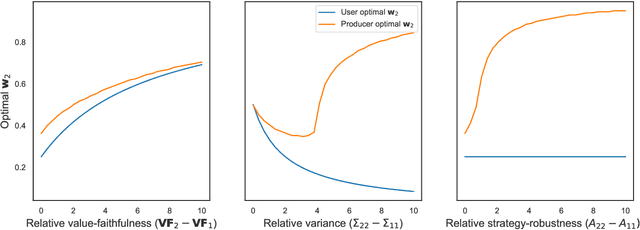
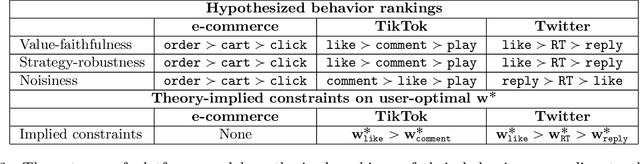
Many recommender systems are based on optimizing a linear weighting of different user behaviors, such as clicks, likes, shares, etc. Though the choice of weights can have a significant impact, there is little formal study or guidance on how to choose them. We analyze the optimal choice of weights from the perspectives of both users and content producers who strategically respond to the weights. We consider three aspects of user behavior: value-faithfulness (how well a behavior indicates whether the user values the content), strategy-robustness (how hard it is for producers to manipulate the behavior), and noisiness (how much estimation error there is in predicting the behavior). Our theoretical results show that for users, upweighting more value-faithful and less noisy behaviors leads to higher utility, while for producers, upweighting more value-faithful and strategy-robust behaviors leads to higher welfare (and the impact of noise is non-monotonic). Finally, we discuss how our results can help system designers select weights in practice.
Causal Inference Struggles with Agency on Online Platforms
Jul 19, 2021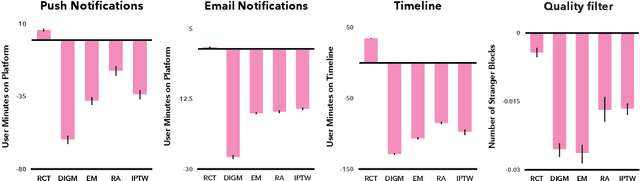

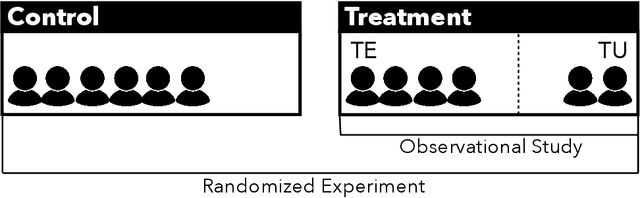
Online platforms regularly conduct randomized experiments to understand how changes to the platform causally affect various outcomes of interest. However, experimentation on online platforms has been criticized for having, among other issues, a lack of meaningful oversight and user consent. As platforms give users greater agency, it becomes possible to conduct observational studies in which users self-select into the treatment of interest as an alternative to experiments in which the platform controls whether the user receives treatment or not. In this paper, we conduct four large-scale within-study comparisons on Twitter aimed at assessing the effectiveness of observational studies derived from user self-selection on online platforms. In a within-study comparison, treatment effects from an observational study are assessed based on how effectively they replicate results from a randomized experiment with the same target population. We test the naive difference in group means estimator, exact matching, regression adjustment, and inverse probability of treatment weighting while controlling for plausible confounding variables. In all cases, all observational estimates perform poorly at recovering the ground-truth estimate from the analogous randomized experiments. In all cases except one, the observational estimates have the opposite sign of the randomized estimate. Our results suggest that observational studies derived from user self-selection are a poor alternative to randomized experimentation on online platforms. In discussing our results, we postulate "Catch-22"s that suggest that the success of causal inference in these settings may be at odds with the original motivations for providing users with greater agency.
From Optimizing Engagement to Measuring Value
Aug 21, 2020
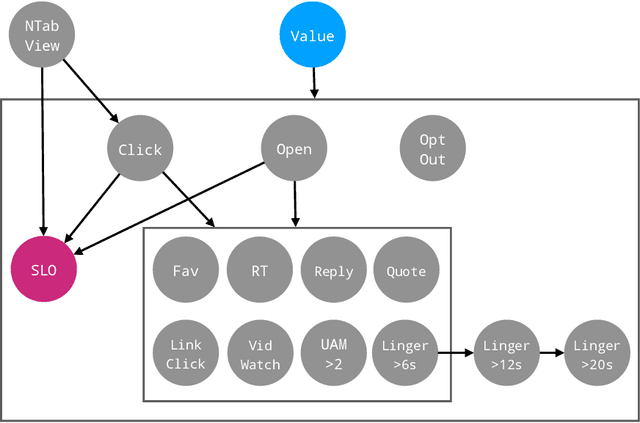
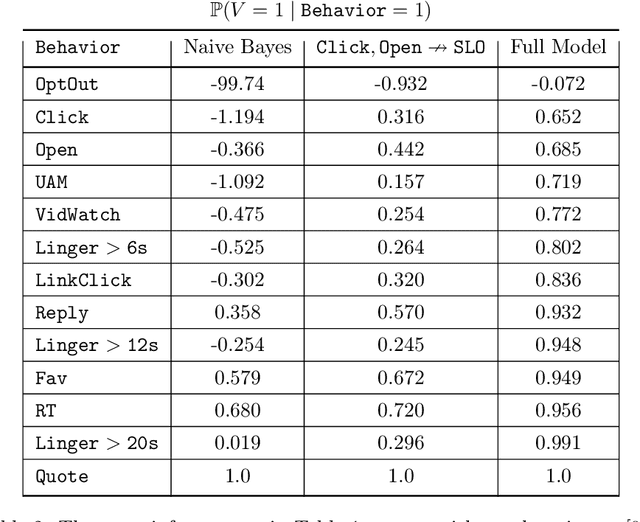
Most recommendation engines today are based on predicting user engagement, e.g. predicting whether a user will click on an item or not. However, there is potentially a large gap between engagement signals and a desired notion of "value" that is worth optimizing for. We use the framework of measurement theory to (a) confront the designer with a normative question about what the designer values, (b) provide a general latent variable model approach that can be used to operationalize the target construct and directly optimize for it, and (c) guide the designer in evaluating and revising their operationalization. We implement our approach on the Twitter platform on millions of users. In line with established approaches to assessing the validity of measurements, we perform a qualitative evaluation of how well our model captures a desired notion of "value".
Reward-rational (implicit) choice: A unifying formalism for reward learning
Feb 12, 2020
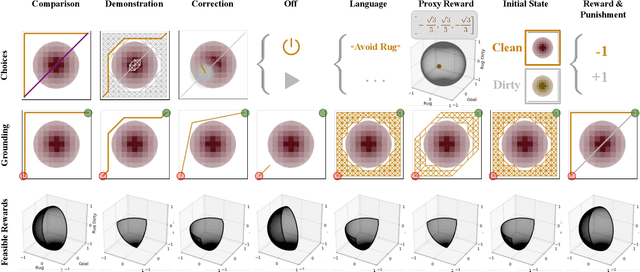

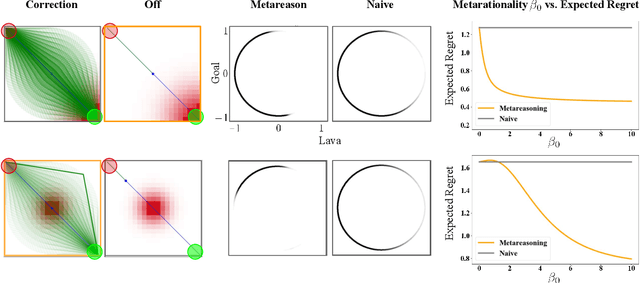
It is often difficult to hand-specify what the correct reward function is for a task, so researchers have instead aimed to learn reward functions from human behavior or feedback. The types of behavior interpreted as evidence of the reward function have expanded greatly in recent years. We've gone from demonstrations, to comparisons, to reading into the information leaked when the human is pushing the robot away or turning it off. And surely, there is more to come. How will a robot make sense of all these diverse types of behavior? Our key insight is that different types of behavior can be interpreted in a single unifying formalism - as a reward-rational choice that the human is making, often implicitly. The formalism offers both a unifying lens with which to view past work, as well as a recipe for interpreting new sources of information that are yet to be uncovered. We provide two examples to showcase this: interpreting a new feedback type, and reading into how the choice of feedback itself leaks information about the reward.
Value-laden Disciplinary Shifts in Machine Learning
Dec 03, 2019
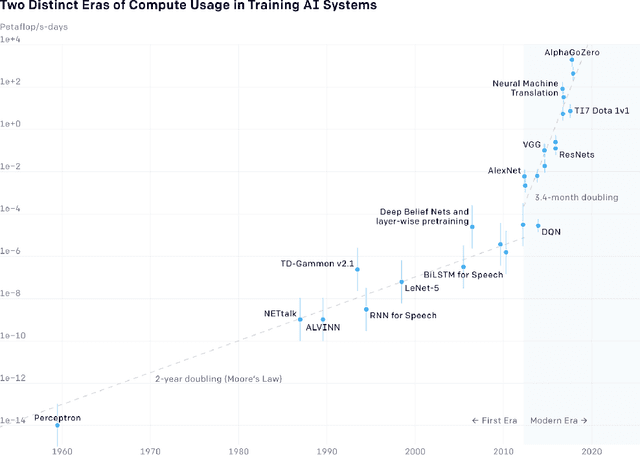
As machine learning models are increasingly used for high-stakes decision making, scholars have sought to intervene to ensure that such models do not encode undesirable social and political values. However, little attention thus far has been given to how values influence the machine learning discipline as a whole. How do values influence what the discipline focuses on and the way it develops? If undesirable values are at play at the level of the discipline, then intervening on particular models will not suffice to address the problem. Instead, interventions at the disciplinary-level are required. This paper analyzes the discipline of machine learning through the lens of philosophy of science. We develop a conceptual framework to evaluate the process through which types of machine learning models (e.g. neural networks, support vector machines, graphical models) become predominant. The rise and fall of model-types is often framed as objective progress. However, such disciplinary shifts are more nuanced. First, we argue that the rise of a model-type is self-reinforcing--it influences the way model-types are evaluated. For example, the rise of deep learning was entangled with a greater focus on evaluations in compute-rich and data-rich environments. Second, the way model-types are evaluated encodes loaded social and political values. For example, a greater focus on evaluations in compute-rich and data-rich environments encodes values about centralization of power, privacy, and environmental concerns.
Strategic Adaptation to Classifiers: A Causal Perspective
Nov 01, 2019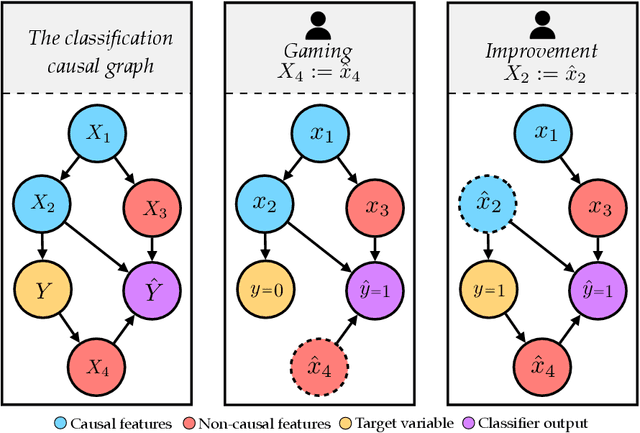
Consequential decision-making incentivizes individuals to adapt their behavior to the specifics of the decision rule. A long line of work has therefore sought to understand and anticipate adaptation, both to prevent strategic individuals from "gaming" the decision rule and to explicitly motivate individuals to improve. In this work, we frame the problem of adaptation as performing interventions in a causal graph. With this causal perspective, we make several contributions. First, we articulate a formal distinction between gaming and improvement. Second, we formalize strategic classification in a new way that recognizes that the individual may improve, rather than only game. In this setting, we show that it is beneficial for the decision-maker to incentivize improvement. Third, we give a reduction from causal inference to designing incentivizes for improvement. This shows that designing good incentives, while desirable, is at least as hard as causal inference.