 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Inference Struggles with Agency on Online Platforms
Paper and Code
Jul 19, 2021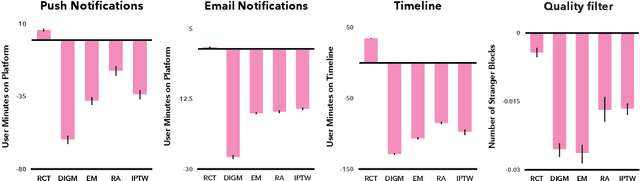

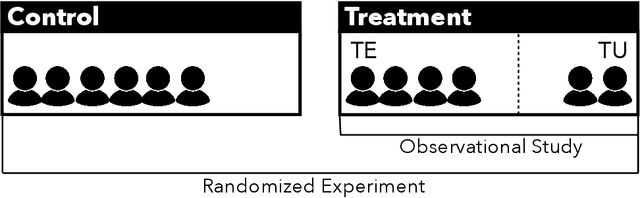
Online platforms regularly conduct randomized experiments to understand how changes to the platform causally affect various outcomes of interest. However, experimentation on online platforms has been criticized for having, among other issues, a lack of meaningful oversight and user consent. As platforms give users greater agency, it becomes possible to conduct observational studies in which users self-select into the treatment of interest as an alternative to experiments in which the platform controls whether the user receives treatment or not. In this paper, we conduct four large-scale within-study comparisons on Twitter aimed at assessing the effectiveness of observational studies derived from user self-selection on online platforms. In a within-study comparison, treatment effects from an observational study are assessed based on how effectively they replicate results from a randomized experiment with the same target population. We test the naive difference in group means estimator, exact matching, regression adjustment, and inverse probability of treatment weighting while controlling for plausible confounding variables. In all cases, all observational estimates perform poorly at recovering the ground-truth estimate from the analogous randomized experiments. In all cases except one, the observational estimates have the opposite sign of the randomized estimate. Our results suggest that observational studies derived from user self-selection are a poor alternative to randomized experimentation on online platforms. In discussing our results, we postulate "Catch-22"s that suggest that the success of causal inference in these settings may be at odds with the original motivations for providing users with greater agency.