 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Face Recognition Bias via Group Adaptive Classifier
Jun 13, 2020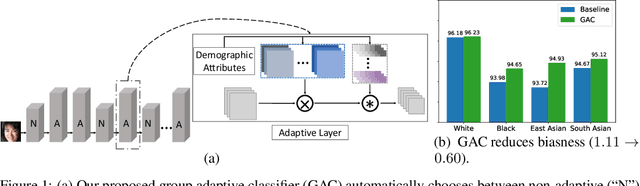
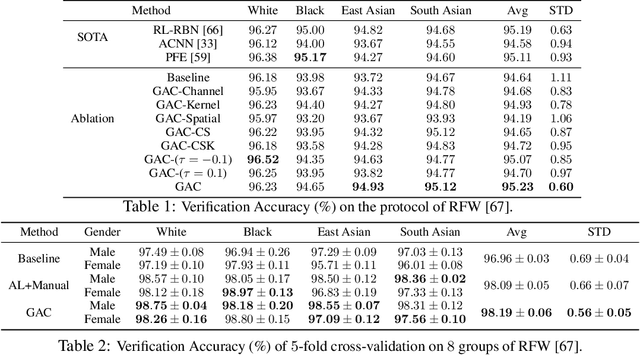
Face recognition is known to exhibit bias - subjects in certain demographic group can be better recognized than other groups. This work aims to learn a fair face representation, where faces of every group could be equally well-represented. Our proposed group adaptive classifier, GAC, learns to mitigate bias by using adaptive convolution kernels and attention mechanisms on faces based on their demographic attributes. The adaptive module comprises kernel masks and channel-wise attention maps for each demographic group so as to activate different facial regions for identification, leading to more discriminative features pertinent to their demographics. We also introduce an automated adaptation strategy which determines whether to apply adaptation to a certain layer by iteratively computing the dissimilarity among demographic-adaptive parameters, thereby increasing the efficiency of the adaptation learning. Experiments on benchmark face datasets (RFW, LFW, IJB-A, and IJB-C) show that our framework is able to mitigate face recognition bias on various demographic groups as well as maintain the competitive performance.
DebFace: De-biasing Face Recognition
Nov 19, 2019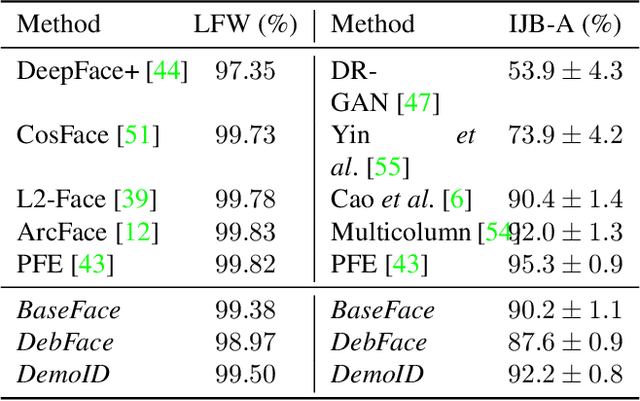
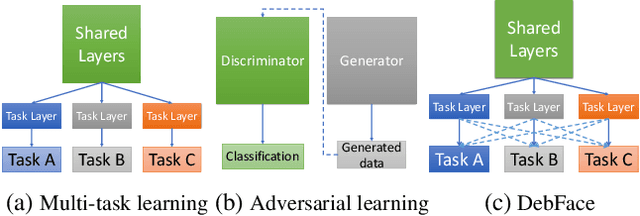
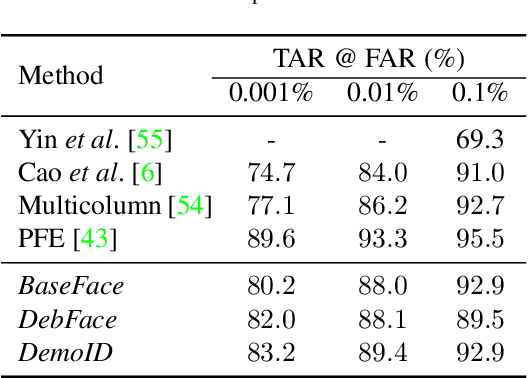
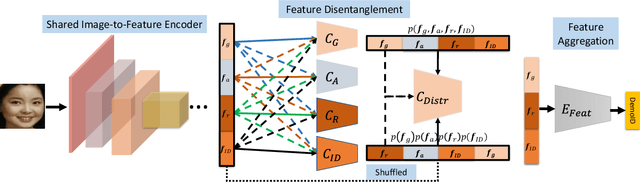
We address the problem of bias in automated face recognition algorithms, where errors are consistently lower on certain cohorts belonging to specific demographic groups. We present a novel de-biasing adversarial network that learns to extract disentangled feature representations for both unbiased face recognition and demographics estimation. The proposed network consists of one identity classifier and three demographic classifiers (for gender, age, and race) that are trained to distinguish identity and demographic attributes, respectively. Adversarial learning is adopted to minimize correlation among feature factors so as to abate bias influence from other factors. We also design a new scheme to combine demographics with identity features to strengthen robustness of face representation in different demographic groups. The experimental results show that our approach is able to reduce bias in face recognition as well as demographics estimation while achieving state-of-the-art performance.
Recurrent Embedding Aggregation Network for Video Face Recognition
Apr 26, 2019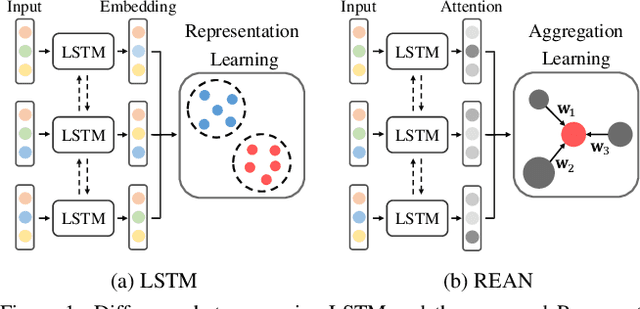
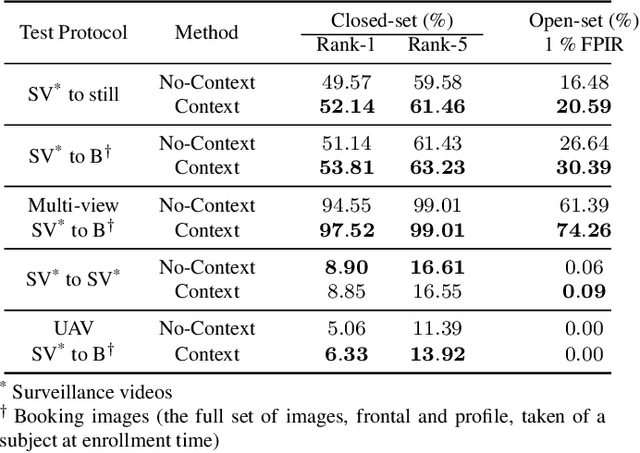

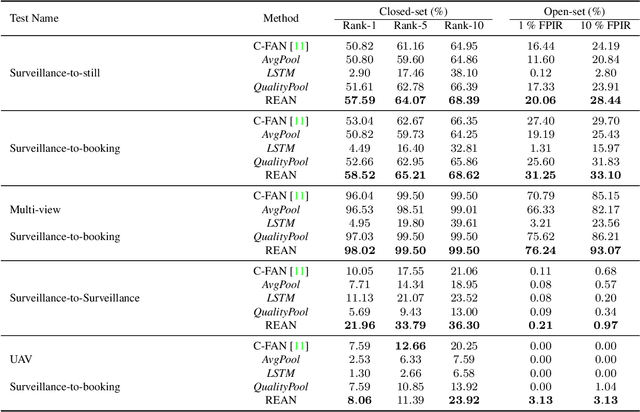
Recurrent networks have been successful in analyzing temporal data and have been widely used for video analysis. However, for video face recognition, where the base CNNs trained on large-scale data already provide discriminative features, using Long Short-Term Memory (LSTM), a popular recurrent network, for feature learning could lead to overfitting and degrade the performance instead. We propose a Recurrent Embedding Aggregation Network (REAN) for set to set face recognition. Compared with LSTM, REAN is robust against overfitting because it only learns how to aggregate the pre-trained embeddings rather than learning representations from scratch. Compared with quality-aware aggregation methods, REAN can take advantage of the context information to circumvent the noise introduced by redundant video frames. Empirical results on three public domain video face recognition datasets, IJB-S, YTF, and PaSC show that the proposed REAN significantly outperforms naive CNN-LSTM structure and quality-aware aggregation methods.
Video Face Recognition: Component-wise Feature Aggregation Network (C-FAN)
Feb 21, 2019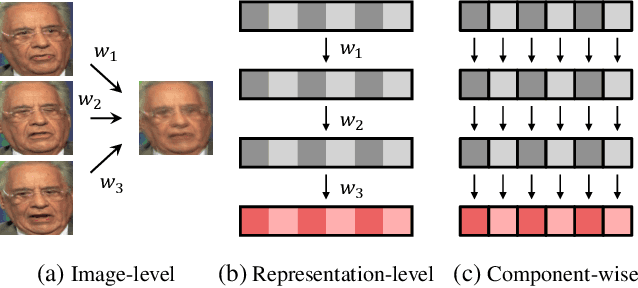
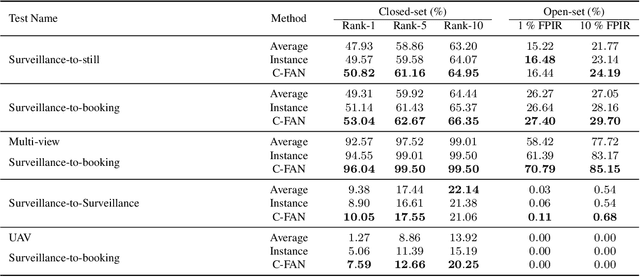

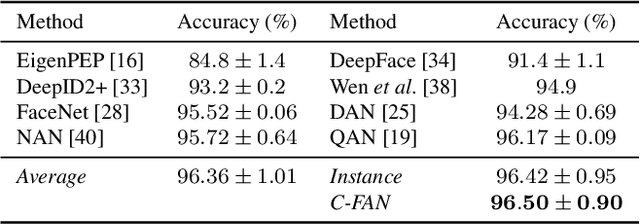
We propose a new approach to video face recognition. Our component-wise feature aggregation network (C-FAN) accepts a set of face images of a subject as an input, and outputs a single feature vector as the face representation of the set for the recognition task. The whole network is trained in two steps: (i) train a base CNN for still image face recognition; (ii) add an aggregation module to the base network to learn the quality value for each feature component, which adaptively aggregates deep feature vectors into a single vector to represent the face in a video. C-FAN automatically learns to retain salient face features with high quality scores while suppressing features with low quality scores. The experimental results on three benchmark datasets, YouTube Faces, IJB-A, and IJB-S show that the proposed C-FAN network is capable of generating a compact feature vector with 512 dimensions for a video sequence by efficiently aggregating feature vectors of all the video frames to achieve state of the art performance.
Face Recognition: Primates in the Wild
Apr 24, 2018
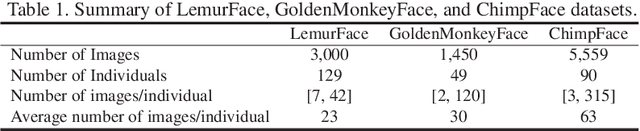


We present a new method of primate face recognition, and evaluate this method on several endangered primates, including golden monkeys, lemurs, and chimpanzees. The three datasets contain a total of 11,637 images of 280 individual primates from 14 species. Primate face recognition performance is evaluated using two existing state-of-the-art open-source systems, (i) FaceNet and (ii) SphereFace, (iii) a lemur face recognition system from literature, and (iv) our new convolutional neural network (CNN) architecture called PrimNet. Three recognition scenarios are considered: verification (1:1 comparison), and both open-set and closed-set identification (1:N search). We demonstrate that PrimNet outperforms all of the other systems in all three scenarios for all primate species tested. Finally, we implement an Android application of this recognition system to assist primate researchers and conservationists in the wild for individual recognition of primates.
On the Intrinsic Dimensionality of Face Representation
Mar 26, 2018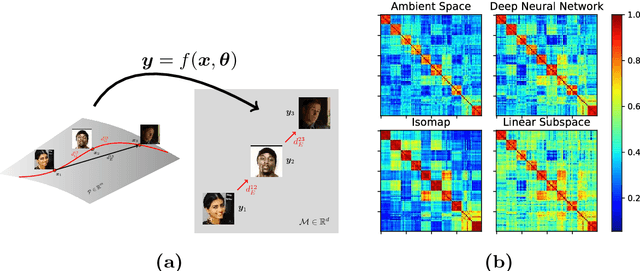
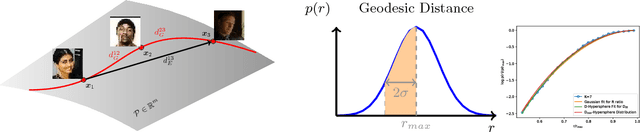
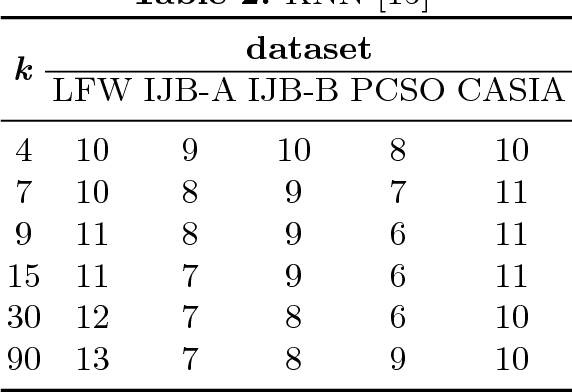
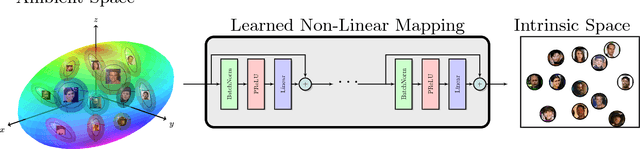
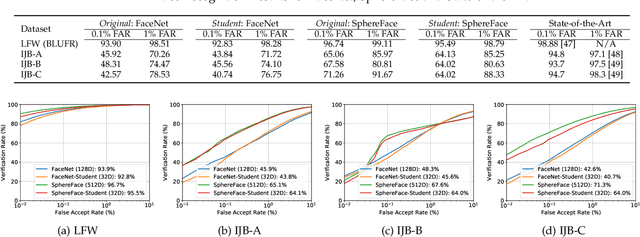
The two underlying factors that determine the efficacy of face representations are, the embedding function to represent a face image and the dimensionality of the representation, e.g. the number of features. While the design of the embedding function has been well studied, relatively little is known about the compactness of such representations. For instance, what is the minimal number of degrees of freedom or intrinsic dimensionality of a given face representation? Can we find a mapping from the ambient representation to this minimal intrinsic space that retains it's full utility? This paper addresses both of these questions. Given a face representation, (1) we leverage intrinsic geodesic distances induced by a neighborhood graph to empirically estimate it's intrinsic dimensionality, (2) develop a neural network based non-linear mapping that transforms the ambient representation to the minimal intrinsic space of that dimensionality, and (3) validate the veracity of the mapping through face matching in the intrinsic space. Experiments on benchmark face datasets (LFW, IJB-A, IJB-B, PCSO and CASIA) indicate that, (1) the intrinsic dimensionality of deep neural network representation is significantly lower than the dimensionality of the ambient features. For instance, Facenet's 128-d representation has an intrinsic dimensionality in the range of 9-12, and (2) the neural network based mapping is able to provide face representations of significantly lower dimensionality while being as discriminative (TAR @ 0.1% FAR of 84.67%, 90.40% at 10 and 20 dimensions, respectively vs 95.50% at 128 ambient dimension on the LFW dataset) as the corresponding ambient representation.
On the Capacity of Face Representation
Feb 15, 2018

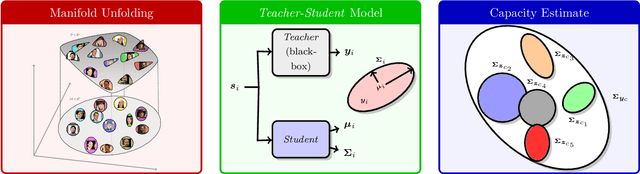
Face recognition is a widely used technology with numerous large-scale applications, such as surveillance, social media and law enforcement. There has been tremendous progress in face recognition accuracy over the past few decades, much of which can be attributed to deep learning-based approaches during the last five years. Indeed, automated face recognition systems are now believed to surpass human performance in some scenarios. Despite this progress, a crucial question still remains unanswered: given a face representation, how many identities can it resolve? In other words, what is the capacity of the face representation? A scientific basis for estimating the capacity of a given face representation will not only benefit the evaluation and comparison of different face representations but will also establish an upper bound on the scalability of an automatic face recognition system. We cast the face capacity estimation problem under the information theoretic framework of capacity of a Gaussian noise channel. By explicitly accounting for two sources of representational noise: epistemic uncertainty and aleatoric variability, our approach is able to estimate the capacity of any given face representation. To demonstrate the efficacy of our approach, we estimate the capacity of a 128-dimensional DNN based face representation, FaceNet, and that of the classical Eigenfaces representation of the same dimensionality. Our experiments on unconstrained faces indicate that, (a) our proposed model yields a capacity upper bound of 5.8x$10^{8}$ for FaceNet and 1x$10^{0}$ for Eigenfaces at a false acceptance rate (FAR) of 1%, (b) the face representation capacity reduces drastically as you lower the desired FAR (for FaceNet; the capacity at FAR of 0.1% and 0.001% is 2.4x$10^{6}$ and 7.0x$10^{2}$, respectively), and (c) the empirical performance of FaceNet is significantly below the theoretical limit.