 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Embedding Aggregation Network for Video Face Recognition
Apr 26, 2019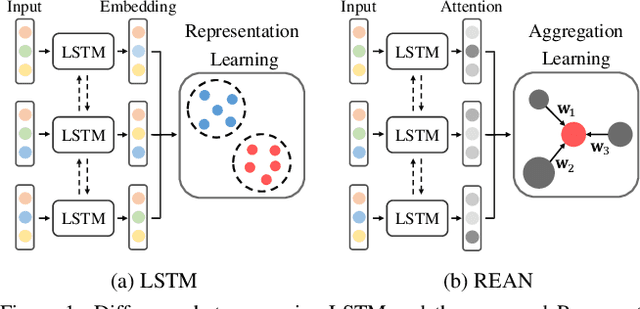
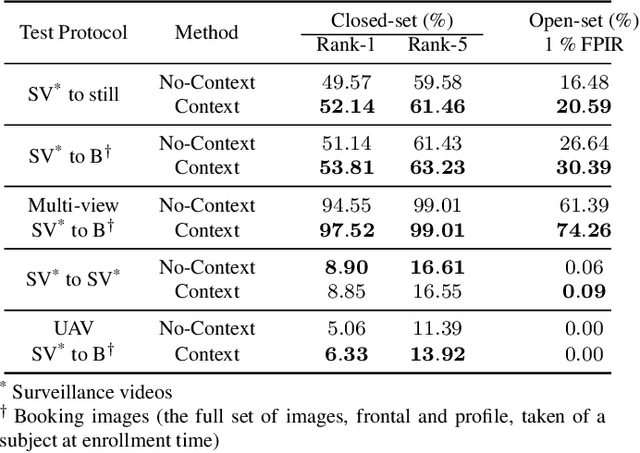

Recurrent networks have been successful in analyzing temporal data and have been widely used for video analysis. However, for video face recognition, where the base CNNs trained on large-scale data already provide discriminative features, using Long Short-Term Memory (LSTM), a popular recurrent network, for feature learning could lead to overfitting and degrade the performance instead. We propose a Recurrent Embedding Aggregation Network (REAN) for set to set face recognition. Compared with LSTM, REAN is robust against overfitting because it only learns how to aggregate the pre-trained embeddings rather than learning representations from scratch. Compared with quality-aware aggregation methods, REAN can take advantage of the context information to circumvent the noise introduced by redundant video frames. Empirical results on three public domain video face recognition datasets, IJB-S, YTF, and PaSC show that the proposed REAN significantly outperforms naive CNN-LSTM structure and quality-aware aggregation methods.
Probabilistic Face Embeddings
Apr 25, 2019
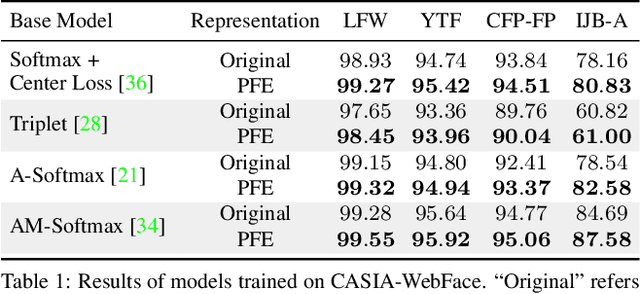


Embedding methods have achieved success in face recognition by comparing facial features in a latent semantic space. However, in a fully unconstrained face setting, the features learned by the embedding model could be ambiguous or may not even be present in the input face, leading to noisy representations. We propose Probabilistic Face Embeddings (PFEs), which represent each face image as a Gaussian distribution in the latent space. The mean of the distribution estimates the most likely feature values while the variance shows the uncertainty in the feature values. Probabilistic solutions can then be naturally derived for matching and fusing PFEs using the uncertainty information. Empirical evaluation on different baseline models, training datasets and benchmarks show that the proposed method can improve the face recognition performance of deterministic embeddings by converting them into PFEs. The uncertainties estimated by PFEs also serve as good indicators of the potential matching accuracy, which are important for a risk-controlled recognition system.
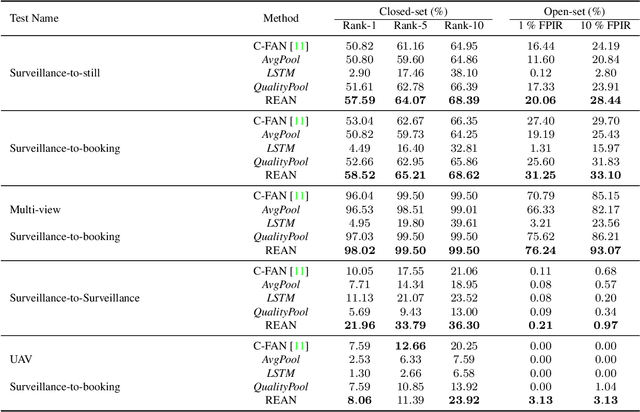
Video Face Recognition: Component-wise Feature Aggregation Network (C-FAN)
Feb 21, 2019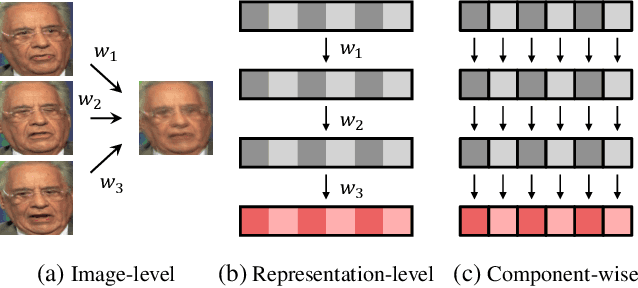
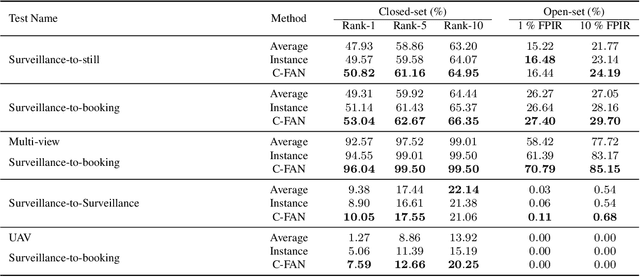

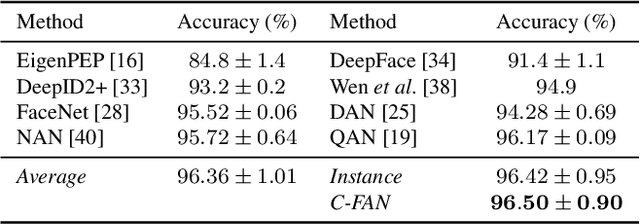
We propose a new approach to video face recognition. Our component-wise feature aggregation network (C-FAN) accepts a set of face images of a subject as an input, and outputs a single feature vector as the face representation of the set for the recognition task. The whole network is trained in two steps: (i) train a base CNN for still image face recognition; (ii) add an aggregation module to the base network to learn the quality value for each feature component, which adaptively aggregates deep feature vectors into a single vector to represent the face in a video. C-FAN automatically learns to retain salient face features with high quality scores while suppressing features with low quality scores. The experimental results on three benchmark datasets, YouTube Faces, IJB-A, and IJB-S show that the proposed C-FAN network is capable of generating a compact feature vector with 512 dimensions for a video sequence by efficiently aggregating feature vectors of all the video frames to achieve state of the art performance.