 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Face Recognition: Component-wise Feature Aggregation Network (C-FAN)
Paper and Code
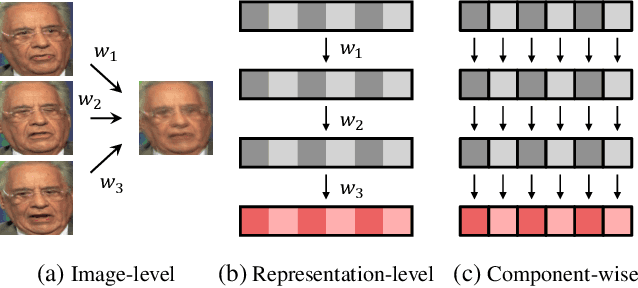
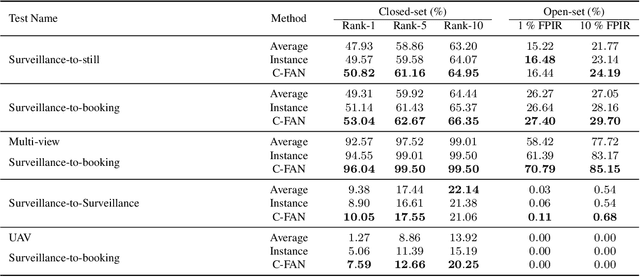

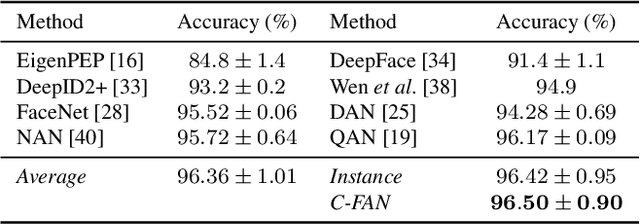
We propose a new approach to video face recognition. Our component-wise feature aggregation network (C-FAN) accepts a set of face images of a subject as an input, and outputs a single feature vector as the face representation of the set for the recognition task. The whole network is trained in two steps: (i) train a base CNN for still image face recognition; (ii) add an aggregation module to the base network to learn the quality value for each feature component, which adaptively aggregates deep feature vectors into a single vector to represent the face in a video. C-FAN automatically learns to retain salient face features with high quality scores while suppressing features with low quality scores. The experimental results on three benchmark datasets, YouTube Faces, IJB-A, and IJB-S show that the proposed C-FAN network is capable of generating a compact feature vector with 512 dimensions for a video sequence by efficiently aggregating feature vectors of all the video frames to achieve state of the art performance.