 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Cut Segmentation Methods Revisited with a Quantum Algorithm
Dec 07, 2018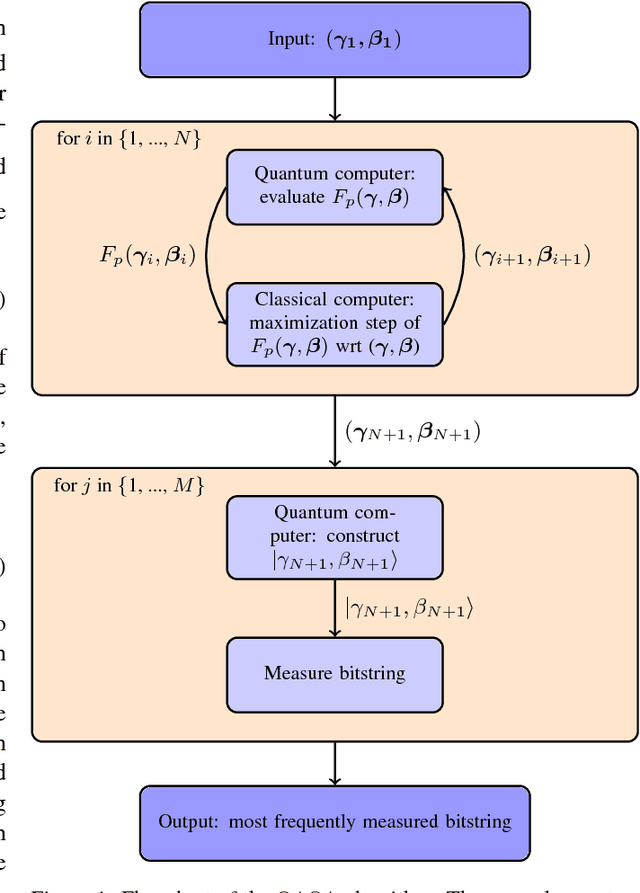
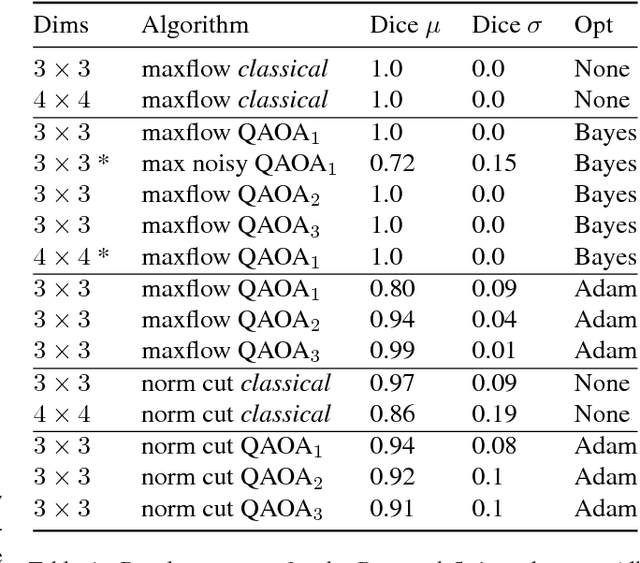
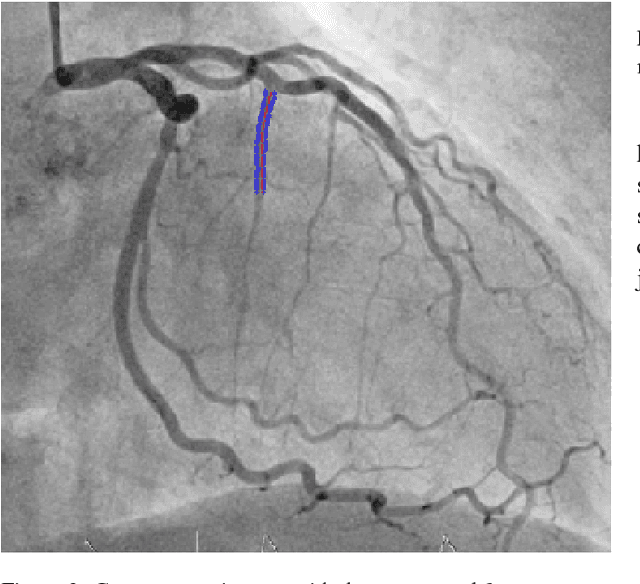
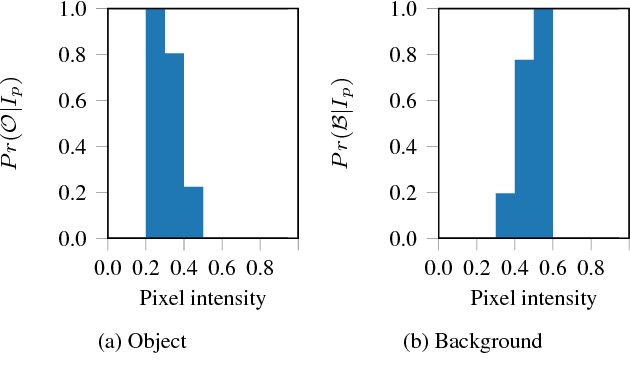
The design and performance of computer vision algorithms are greatly influenced by the hardware on which they are implemented. CPUs, multi-core CPUs, FPGAs and GPUs have inspired new algorithms and enabled existing ideas to be realized. This is notably the case with GPUs, which has significantly changed the landscape of computer vision research through deep learning. As the end of Moores law approaches, researchers and hardware manufacturers are exploring alternative hardware computing paradigms. Quantum computers are a very promising alternative and offer polynomial or even exponential speed-ups over conventional computing for some problems. This paper presents a novel approach to image segmentation that uses new quantum computing hardware. Segmentation is formulated as a graph cut problem that can be mapped to the quantum approximation optimization algorithm (QAOA). This algorithm can be implemented on current and near-term quantum computers. Encouraging results are presented on artificial and medical imaging data. This represents an important, practical step towards leveraging quantum computers for computer vision.
Adversarial quantum circuit learning for pure state approximation
Oct 11, 2018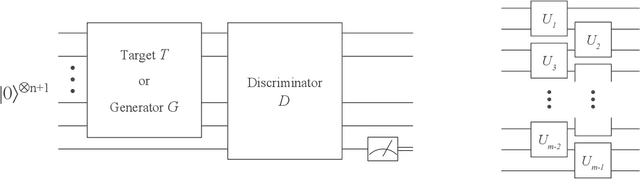
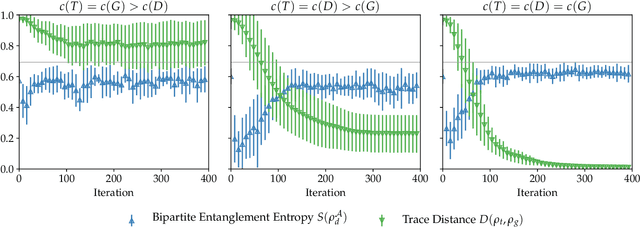
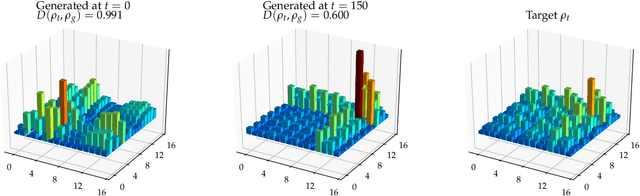
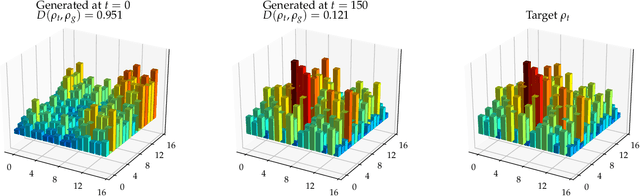
Adversarial learning is one of the most successful approaches to modelling high-dimensional probability distributions from data. The quantum computing community has recently begun to generalise this idea and to look for potential applications. In this work, we derive an adversarial algorithm for the problem of approximating an unknown quantum pure state. Although this could be done on universal quantum computers, the adversarial formulation enables us to execute the algorithm on near-term quantum computers. Two parametrized circuits are optimized in tandem: One tries to approximate the target state, the other tries to distinguish between target and approximated state. Supported by numerical simulations, we show that resilient backpropagation algorithms perform remarkably well in optimizing the two circuits. We use the bipartite entanglement entropy to design an efficient heuristic for the stopping criterion. Our approach may find application in quantum state tomography.
Approximating Hamiltonian dynamics with the Nyström method
Sep 17, 2018Simulating the time-evolution of quantum mechanical systems is BQP-hard and expected to be one of the foremost applications of quantum computers. We consider the approximation of Hamiltonian dynamics using subsampling methods from randomized numerical linear algebra. We propose conditions for the efficient approximation of state vectors evolving under a given Hamiltonian. As an immediate application, we show that sample based quantum simulation, a type of evolution where the Hamiltonian is a density matrix, can be efficiently classically simulated under specific structural conditions. Our main technical contribution is a randomized algorithm for approximating Hermitian matrix exponentials. The proof leverages the Nystr\"om method to obtain low-rank approximations of the Hamiltonian. We envisage that techniques from randomized linear algebra will bring further insights into the power of quantum computation.
Learning hard quantum distributions with variational autoencoders
Jul 02, 2018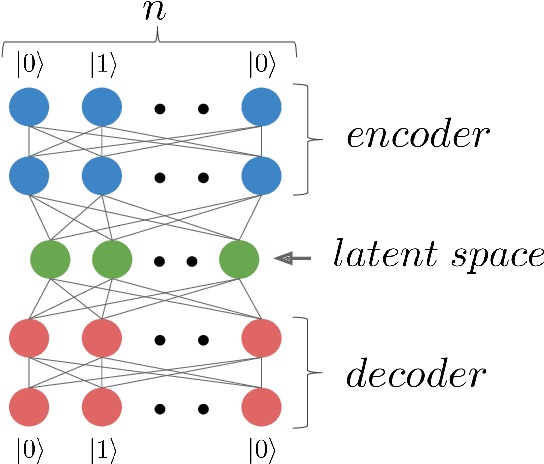
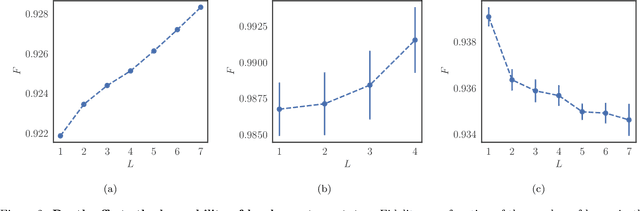
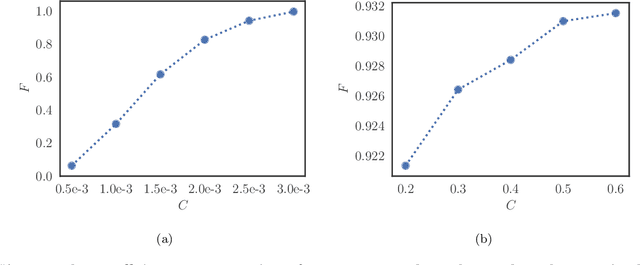
Studying general quantum many-body systems is one of the major challenges in modern physics because it requires an amount of computational resources that scales exponentially with the size of the system.Simulating the evolution of a state, or even storing its description, rapidly becomes intractable for exact classical algorithms. Recently, machine learning techniques, in the form of restricted Boltzmann machines, have been proposed as a way to efficiently represent certain quantum states with applications in state tomography and ground state estimation. Here, we introduce a new representation of states based on variational autoencoders. Variational autoencoders are a type of generative model in the form of a neural network. We probe the power of this representation by encoding probability distributions associated with states from different classes. Our simulations show that deep networks give a better representation for states that are hard to sample from, while providing no benefit for random states. This suggests that the probability distributions associated to hard quantum states might have a compositional structure that can be exploited by layered neural networks. Specifically, we consider the learnability of a class of quantum states introduced by Fefferman and Umans. Such states are provably hard to sample for classical computers, but not for quantum ones, under plausible computational complexity assumptions. The good level of compression achieved for hard states suggests these methods can be suitable for characterising states of the size expected in first generation quantum hardware.
* v2: 9 pages, 3 figures, journal version with major edits with respect to v1 (rewriting of section "hard and easy quantum states", extended discussion on comparison with tensor networks)
Universal discriminative quantum neural networks
May 22, 2018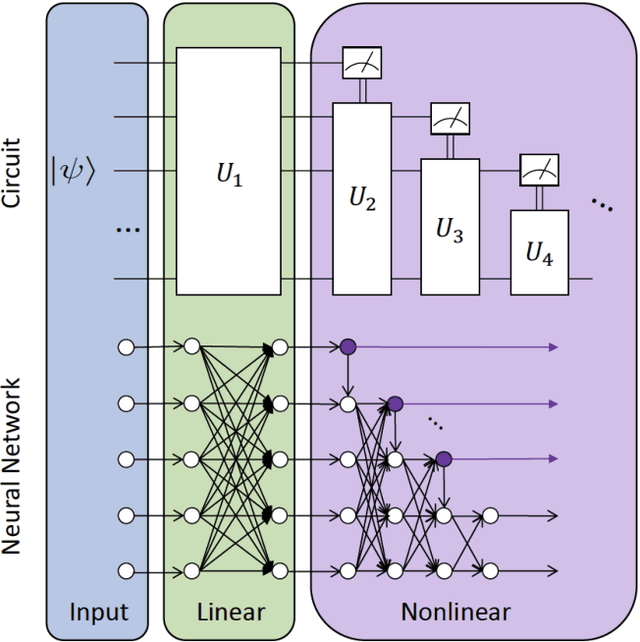
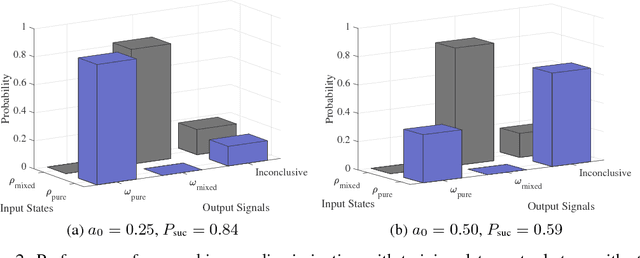
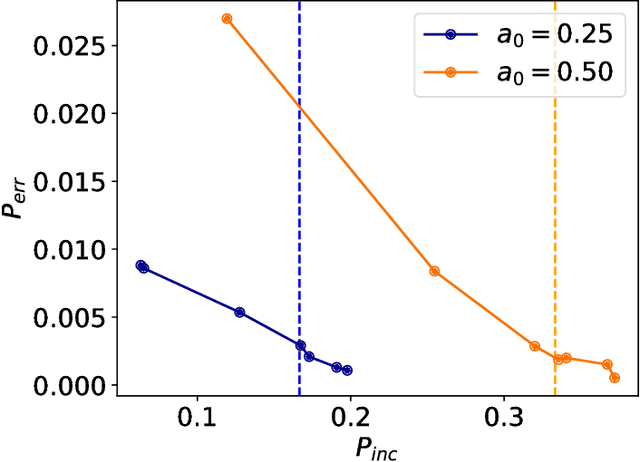
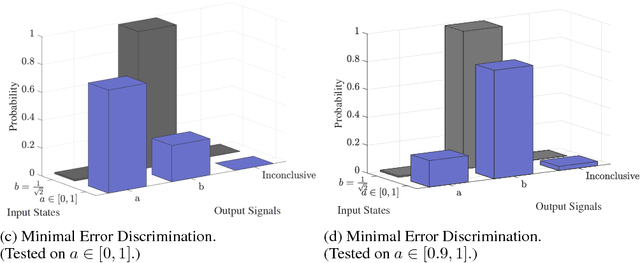
Quantum mechanics fundamentally forbids deterministic discrimination of quantum states and processes. However, the ability to optimally distinguish various classes of quantum data is an important primitive in quantum information science. In this work, we train near-term quantum circuits to classify data represented by non-orthogonal quantum probability distributions using the Adam stochastic optimization algorithm. This is achieved by iterative interactions of a classical device with a quantum processor to discover the parameters of an unknown non-unitary quantum circuit. This circuit learns to simulates the unknown structure of a generalized quantum measurement, or Positive-Operator-Value-Measure (POVM), that is required to optimally distinguish possible distributions of quantum inputs. Notably we use universal circuit topologies, with a theoretically motivated circuit design, which guarantees that our circuits can in principle learn to perform arbitrary input-output mappings. Our numerical simulations show that shallow quantum circuits could be trained to discriminate among various pure and mixed quantum states exhibiting a trade-off between minimizing erroneous and inconclusive outcomes with comparable performance to theoretically optimal POVMs. We train the circuit on different classes of quantum data and evaluate the generalization error on unseen mixed quantum states. This generalization power hence distinguishes our work from standard circuit optimization and provides an example of quantum machine learning for a task that has inherently no classical analogue.
Compact Neural Networks based on the Multiscale Entanglement Renormalization Ansatz
Apr 03, 2018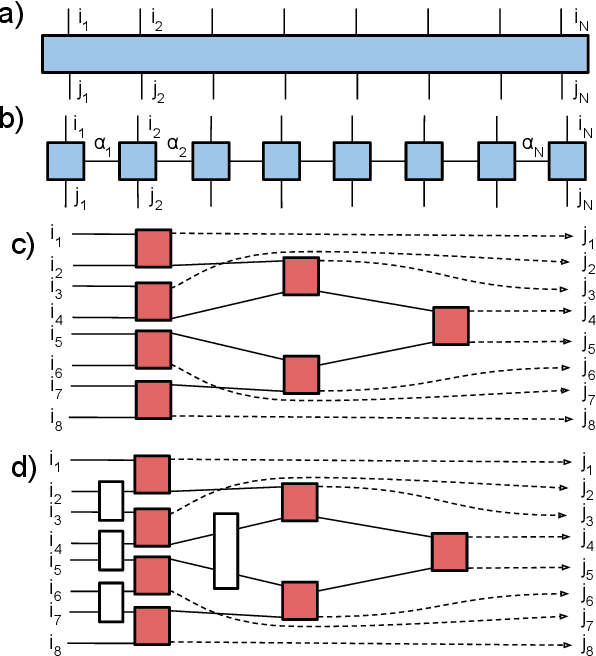
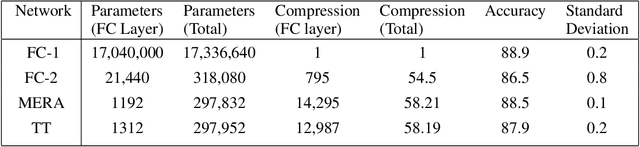
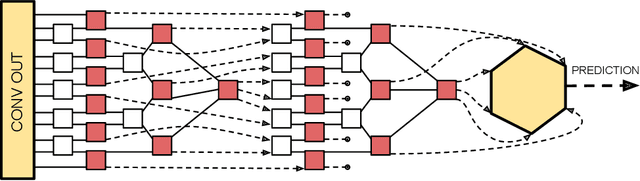
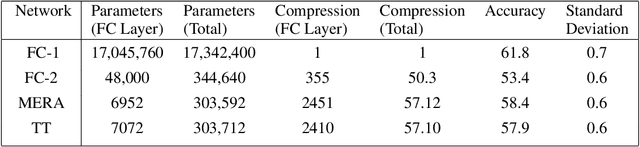
This paper demonstrates a method for tensorizing neural networks based upon an efficient way of approximating scale invariant quantum states, the Multi-scale Entanglement Renormalization Ansatz (MERA). We employ MERA as a replacement for the fully connected layers in a convolutional neural network and test this implementation on the CIFAR-10 and CIFAR-100 datasets. The proposed method outperforms factorization using tensor trains, providing greater compression for the same level of accuracy and greater accuracy for the same level of compression. We demonstrate MERA layers with 14000 times fewer parameters and a reduction in accuracy of less than 1% compared to the equivalent fully connected layers, scaling like O(N).
Learning DNFs under product distributions via μ-biased quantum Fourier sampling
Mar 06, 2018We show that DNF formulae can be quantum PAC-learned in polynomial time under product distributions using a quantum example oracle. The best classical algorithm (without access to membership queries) runs in superpolynomial time. Our result extends the work by Bshouty and Jackson (1998) that proved that DNF formulae are efficiently learnable under the uniform distribution using a quantum example oracle. Our proof is based on a new quantum algorithm that efficiently samples the coefficients of a {\mu}-biased Fourier transform.
Quantum machine learning: a classical perspective
Feb 13, 2018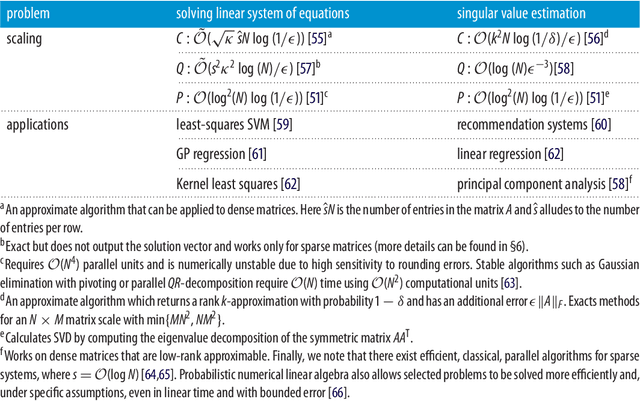
Recently, increased computational power and data availability, as well as algorithmic advances, have led machine learning techniques to impressive results in regression, classification, data-generation and reinforcement learning tasks. Despite these successes, the proximity to the physical limits of chip fabrication alongside the increasing size of datasets are motivating a growing number of researchers to explore the possibility of harnessing the power of quantum computation to speed-up classical machine learning algorithms. Here we review the literature in quantum machine learning and discuss perspectives for a mixed readership of classical machine learning and quantum computation experts. Particular emphasis will be placed on clarifying the limitations of quantum algorithms, how they compare with their best classical counterparts and why quantum resources are expected to provide advantages for learning problems. Learning in the presence of noise and certain computationally hard problems in machine learning are identified as promising directions for the field. Practical questions, like how to upload classical data into quantum form, will also be addressed.
* v3 33 pages; typos corrected and references added
Experimental learning of quantum states
Nov 30, 2017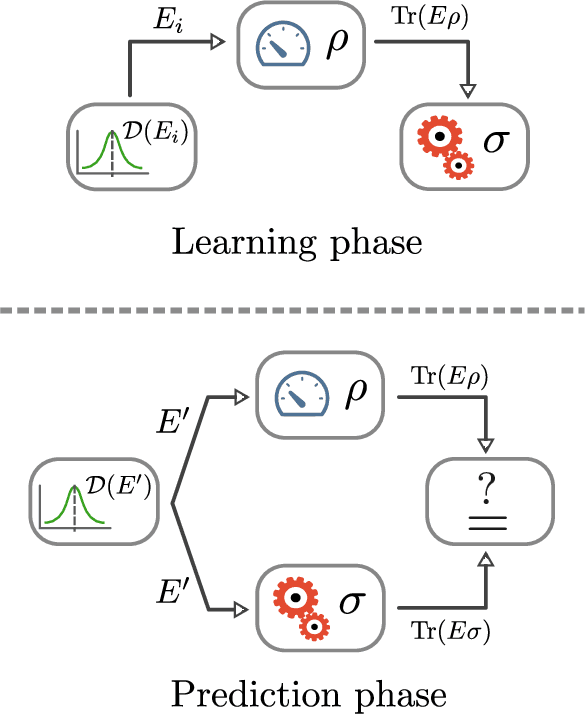
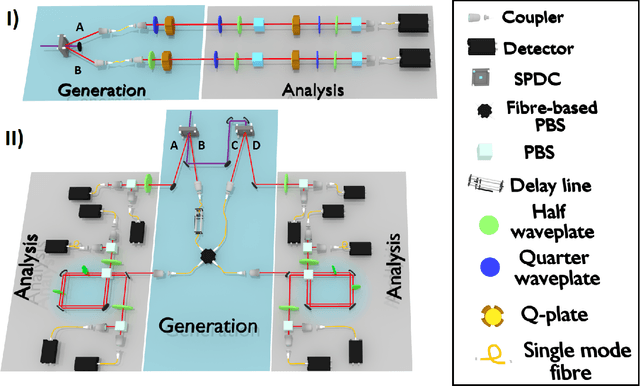
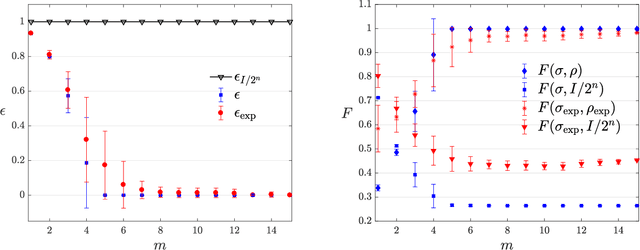
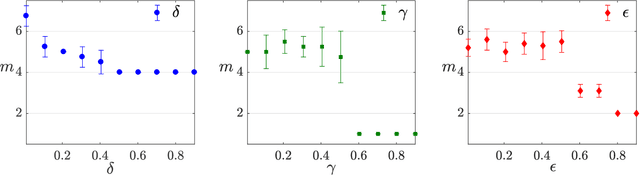
The number of parameters describing a quantum state is well known to grow exponentially with the number of particles. This scaling clearly limits our ability to do tomography to systems with no more than a few qubits and has been used to argue against the universal validity of quantum mechanics itself. However, from a computational learning theory perspective, it can be shown that, in a probabilistic setting, quantum states can be approximately learned using only a linear number of measurements. Here we experimentally demonstrate this linear scaling in optical systems with up to 6 qubits. Our results highlight the power of computational learning theory to investigate quantum information, provide the first experimental demonstration that quantum states can be "probably approximately learned" with access to a number of copies of the state that scales linearly with the number of qubits, and pave the way to probing quantum states at new, larger scales.