 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVolSplat4D: Efficient Volume-based Gaussian Splatting for 4D Urban Scene Synthesis
Jan 22, 2026Novel view synthesis (NVS) of static and dynamic urban scenes is essential for autonomous driving simulation, yet existing methods often struggle to balance reconstruction time with quality. While state-of-the-art neural radiance fields and 3D Gaussian Splatting approaches achieve photorealism, they often rely on time-consuming per-scene optimization. Conversely, emerging feed-forward methods frequently adopt per-pixel Gaussian representations, which lead to 3D inconsistencies when aggregating multi-view predictions in complex, dynamic environments. We propose EvolSplat4D, a feed-forward framework that moves beyond existing per-pixel paradigms by unifying volume-based and pixel-based Gaussian prediction across three specialized branches. For close-range static regions, we predict consistent geometry of 3D Gaussians over multiple frames directly from a 3D feature volume, complemented by a semantically-enhanced image-based rendering module for predicting their appearance. For dynamic actors, we utilize object-centric canonical spaces and a motion-adjusted rendering module to aggregate temporal features, ensuring stable 4D reconstruction despite noisy motion priors. Far-Field scenery is handled by an efficient per-pixel Gaussian branch to ensure full-scene coverage. Experimental results on the KITTI-360, KITTI, Waymo, and PandaSet datasets show that EvolSplat4D reconstructs both static and dynamic environments with superior accuracy and consistency, outperforming both per-scene optimization and state-of-the-art feed-forward baselines.
CloudBrain-NMR: An Intelligent Cloud Computing Platform for NMR Spectroscopy Processing, Reconstruction and Analysis
Sep 12, 2023
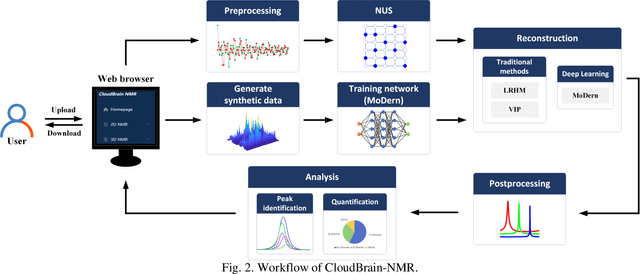


Nuclear Magnetic Resonance (NMR) spectroscopy has served as a powerful analytical tool for studying molecular structure and dynamics in chemistry and biology. However, the processing of raw data acquired from NMR spectrometers and subsequent quantitative analysis involves various specialized tools, which necessitates comprehensive knowledge in programming and NMR. Particularly, the emerging deep learning tools is hard to be widely used in NMR due to the sophisticated setup of computation. Thus, NMR processing is not an easy task for chemist and biologists. In this work, we present CloudBrain-NMR, an intelligent online cloud computing platform designed for NMR data reading, processing, reconstruction, and quantitative analysis. The platform is conveniently accessed through a web browser, eliminating the need for any program installation on the user side. CloudBrain-NMR uses parallel computing with graphics processing units and central processing units, resulting in significantly shortened computation time. Furthermore, it incorporates state-of-the-art deep learning-based algorithms offering comprehensive functionalities that allow users to complete the entire processing procedure without relying on additional software. This platform has empowered NMR applications with advanced artificial intelligence processing. CloudBrain-NMR is openly accessible for free usage at https://csrc.xmu.edu.cn/CloudBrain.html
Video Super-Resolution with Long-Term Self-Exemplars
Jun 24, 2021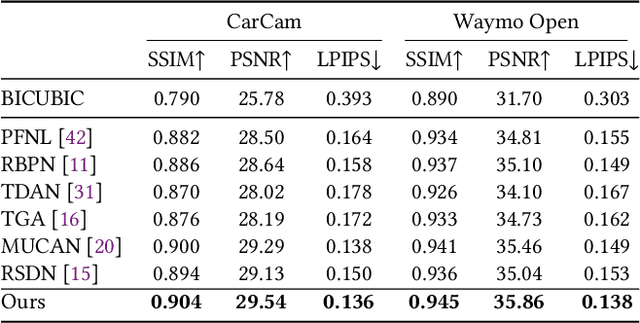
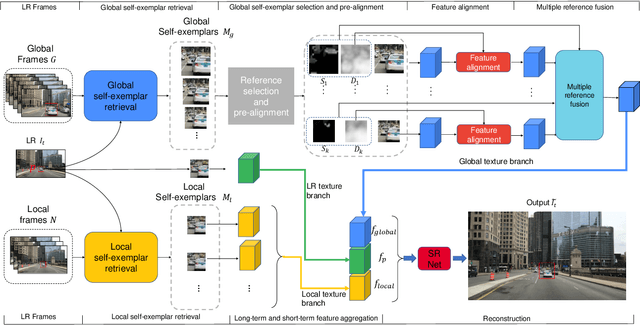
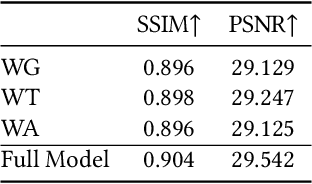

Existing video super-resolution methods often utilize a few neighboring frames to generate a higher-resolution image for each frame. However, the redundant information between distant frames has not been fully exploited in these methods: corresponding patches of the same instance appear across distant frames at different scales. Based on this observation, we propose a video super-resolution method with long-term cross-scale aggregation that leverages similar patches (self-exemplars) across distant frames. Our model also consists of a multi-reference alignment module to fuse the features derived from similar patches: we fuse the features of distant references to perform high-quality super-resolution. We also propose a novel and practical training strategy for referenced-based super-resolution. To evaluate the performance of our proposed method, we conduct extensive experiments on our collected CarCam dataset and the Waymo Open dataset, and the results demonstrate our method outperforms state-of-the-art methods. Our source code will be publicly available.
Maximum-Margin Structured Learning with Deep Networks for 3D Human Pose Estimation
Aug 27, 2015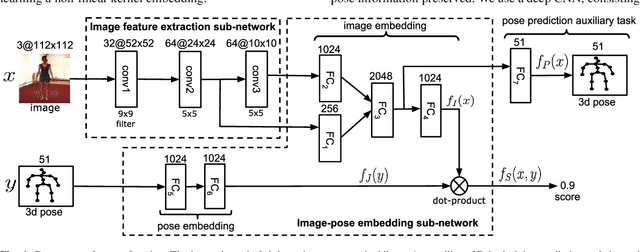


This paper focuses on structured-output learning using deep neural networks for 3D human pose estimation from monocular images. Our network takes an image and 3D pose as inputs and outputs a score value, which is high when the image-pose pair matches and low otherwise. The network structure consists of a convolutional neural network for image feature extraction, followed by two sub-networks for transforming the image features and pose into a joint embedding. The score function is then the dot-product between the image and pose embeddings. The image-pose embedding and score function are jointly trained using a maximum-margin cost function. Our proposed framework can be interpreted as a special form of structured support vector machines where the joint feature space is discriminatively learned using deep neural networks. We test our framework on the Human3.6m dataset and obtain state-of-the-art results compared to other recent methods. Finally, we present visualizations of the image-pose embedding space, demonstrating the network has learned a high-level embedding of body-orientation and pose-configuration.
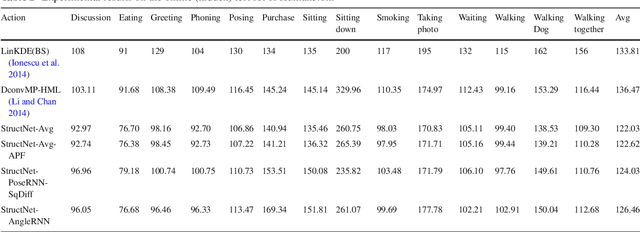
Heterogeneous Multi-task Learning for Human Pose Estimation with Deep Convolutional Neural Network
Jun 13, 2014
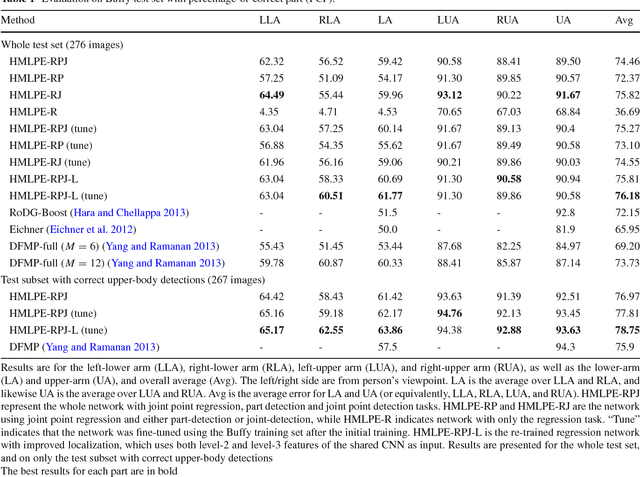
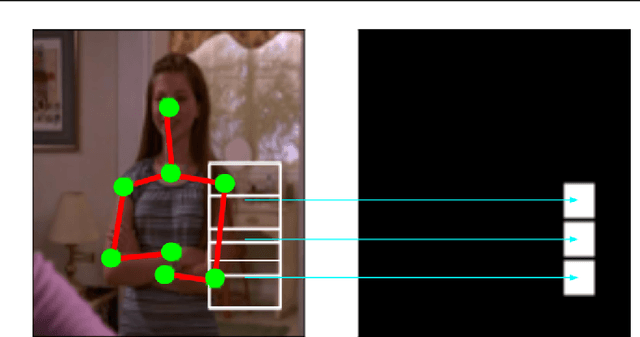

We propose an heterogeneous multi-task learning framework for human pose estimation from monocular image with deep convolutional neural network. In particular, we simultaneously learn a pose-joint regressor and a sliding-window body-part detector in a deep network architecture. We show that including the body-part detection task helps to regularize the network, directing it to converge to a good solution. We report competitive and state-of-art results on several data sets. We also empirically show that the learned neurons in the middle layer of our network are tuned to localized body parts.