 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Super-Resolution with Long-Term Self-Exemplars
Paper and Code
Jun 24, 2021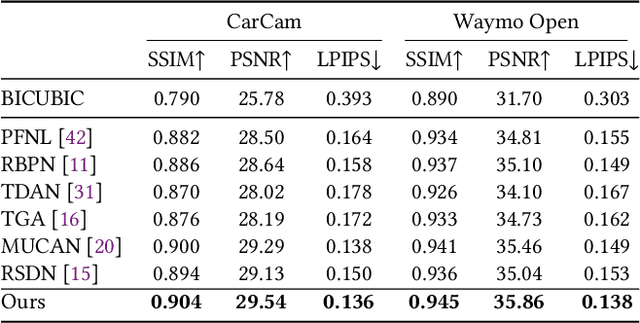
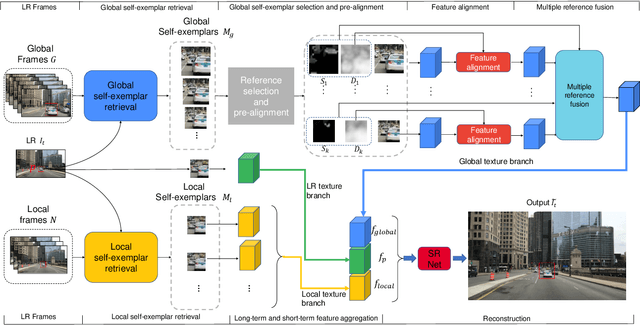
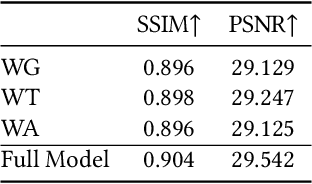

Existing video super-resolution methods often utilize a few neighboring frames to generate a higher-resolution image for each frame. However, the redundant information between distant frames has not been fully exploited in these methods: corresponding patches of the same instance appear across distant frames at different scales. Based on this observation, we propose a video super-resolution method with long-term cross-scale aggregation that leverages similar patches (self-exemplars) across distant frames. Our model also consists of a multi-reference alignment module to fuse the features derived from similar patches: we fuse the features of distant references to perform high-quality super-resolution. We also propose a novel and practical training strategy for referenced-based super-resolution. To evaluate the performance of our proposed method, we conduct extensive experiments on our collected CarCam dataset and the Waymo Open dataset, and the results demonstrate our method outperforms state-of-the-art methods. Our source code will be publicly available.