 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Online EM for Big Topic Modeling
Dec 07, 2015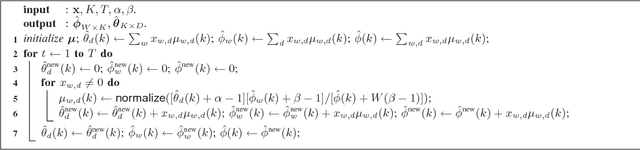
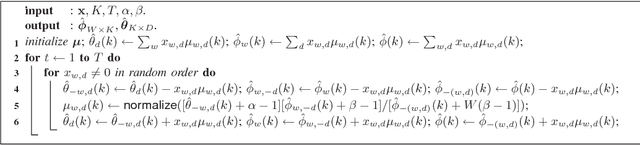

The expectation-maximization (EM) algorithm can compute the maximum-likelihood (ML) or maximum a posterior (MAP) point estimate of the mixture models or latent variable models such as latent Dirichlet allocation (LDA), which has been one of the most popular probabilistic topic modeling methods in the past decade. However, batch EM has high time and space complexities to learn big LDA models from big data streams. In this paper, we present a fast online EM (FOEM) algorithm that infers the topic distribution from the previously unseen documents incrementally with constant memory requirements. Within the stochastic approximation framework, we show that FOEM can converge to the local stationary point of the LDA's likelihood function. By dynamic scheduling for the fast speed and parameter streaming for the low memory usage, FOEM is more efficient for some lifelong topic modeling tasks than the state-of-the-art online LDA algorithms to handle both big data and big models (aka, big topic modeling) on just a PC.
Heterogeneous Multi-task Learning for Human Pose Estimation with Deep Convolutional Neural Network
Jun 13, 2014
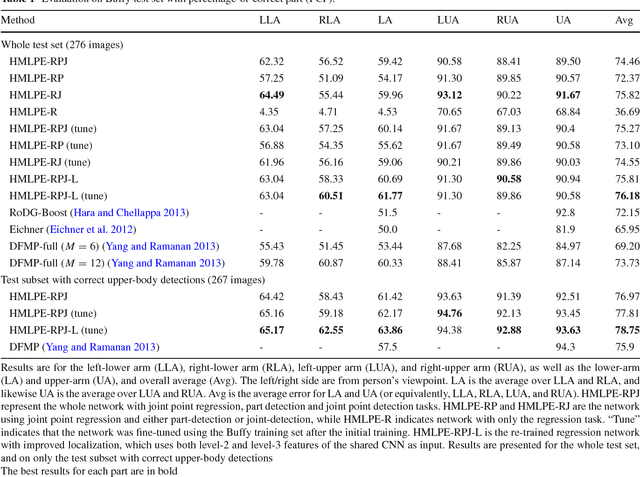
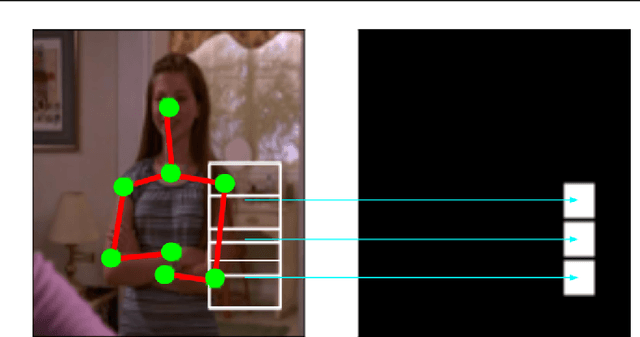

We propose an heterogeneous multi-task learning framework for human pose estimation from monocular image with deep convolutional neural network. In particular, we simultaneously learn a pose-joint regressor and a sliding-window body-part detector in a deep network architecture. We show that including the body-part detection task helps to regularize the network, directing it to converge to a good solution. We report competitive and state-of-art results on several data sets. We also empirically show that the learned neurons in the middle layer of our network are tuned to localized body parts.
ESSP: An Efficient Approach to Minimizing Dense and Nonsubmodular Energy Functions
May 19, 2014



Many recent advances in computer vision have demonstrated the impressive power of dense and nonsubmodular energy functions in solving visual labeling problems. However, minimizing such energies is challenging. None of existing techniques (such as s-t graph cut, QPBO, BP and TRW-S) can individually do this well. In this paper, we present an efficient method, namely ESSP, to optimize binary MRFs with arbitrary pairwise potentials, which could be nonsubmodular and with dense connectivity. We also provide a comparative study of our approach and several recent promising methods. From our study, we make some reasonable recommendations of combining existing methods that perform the best in different situations for this challenging problem. Experimental results validate that for dense and nonsubmodular energy functions, the proposed approach can usually obtain lower energies than the best combination of other techniques using comparably reasonable time.
A New Approach to Speeding Up Topic Modeling
Apr 08, 2014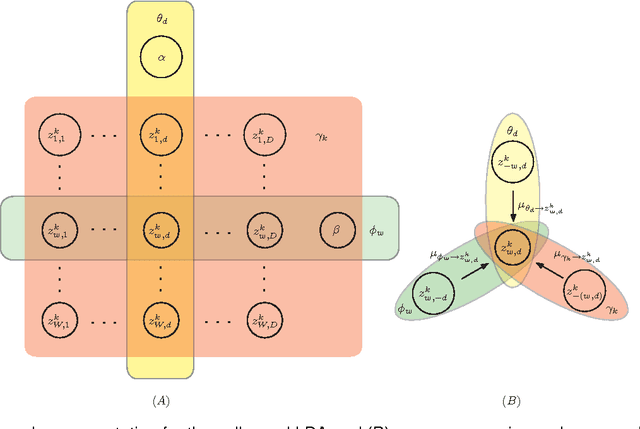

Latent Dirichlet allocation (LDA) is a widely-used probabilistic topic modeling paradigm, and recently finds many applications in computer vision and computational biology. In this paper, we propose a fast and accurate batch algorithm, active belief propagation (ABP), for training LDA. Usually batch LDA algorithms require repeated scanning of the entire corpus and searching the complete topic space. To process massive corpora having a large number of topics, the training iteration of batch LDA algorithms is often inefficient and time-consuming. To accelerate the training speed, ABP actively scans the subset of corpus and searches the subset of topic space for topic modeling, therefore saves enormous training time in each iteration. To ensure accuracy, ABP selects only those documents and topics that contribute to the largest residuals within the residual belief propagation (RBP) framework. On four real-world corpora, ABP performs around $10$ to $100$ times faster than state-of-the-art batch LDA algorithms with a comparable topic modeling accuracy.
Towards Big Topic Modeling
Nov 17, 2013

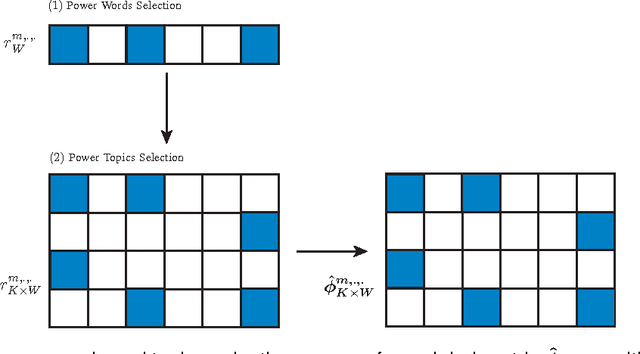
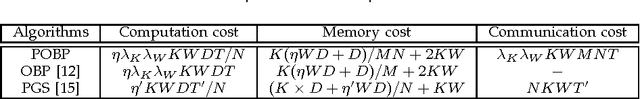
To solve the big topic modeling problem, we need to reduce both time and space complexities of batch latent Dirichlet allocation (LDA) algorithms. Although parallel LDA algorithms on the multi-processor architecture have low time and space complexities, their communication costs among processors often scale linearly with the vocabulary size and the number of topics, leading to a serious scalability problem. To reduce the communication complexity among processors for a better scalability, we propose a novel communication-efficient parallel topic modeling architecture based on power law, which consumes orders of magnitude less communication time when the number of topics is large. We combine the proposed communication-efficient parallel architecture with the online belief propagation (OBP) algorithm referred to as POBP for big topic modeling tasks. Extensive empirical results confirm that POBP has the following advantages to solve the big topic modeling problem: 1) high accuracy, 2) communication-efficient, 3) fast speed, and 4) constant memory usage when compared with recent state-of-the-art parallel LDA algorithms on the multi-processor architecture.
Communication-Efficient Parallel Belief Propagation for Latent Dirichlet Allocation
Jun 11, 2012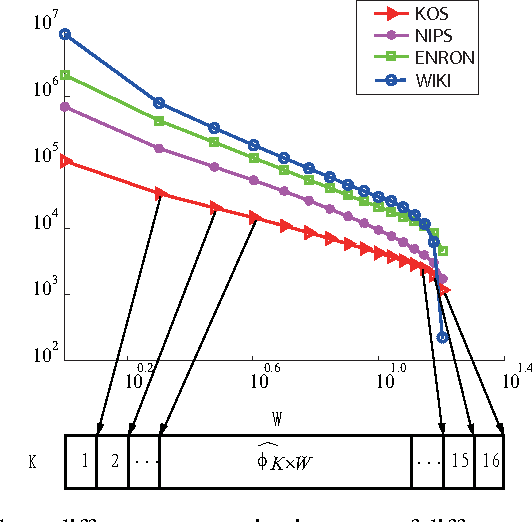
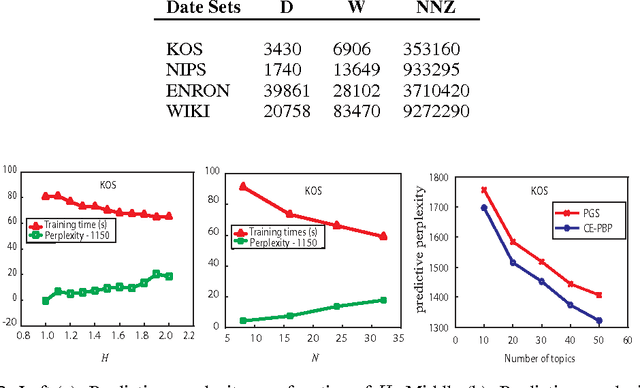
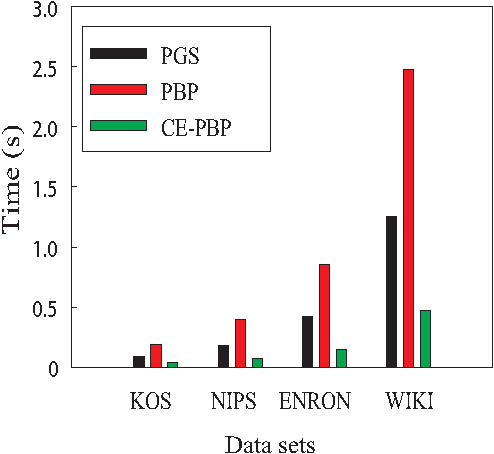
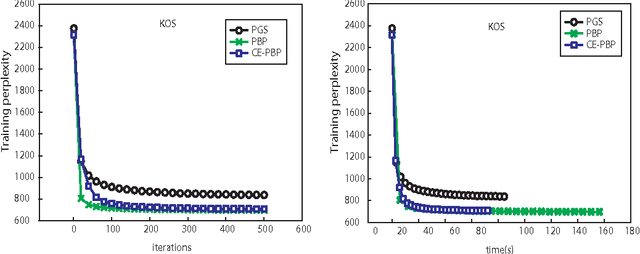
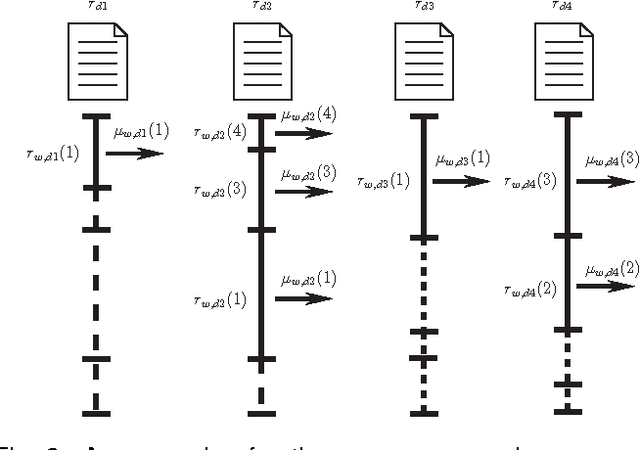
This paper presents a novel communication-efficient parallel belief propagation (CE-PBP) algorithm for training latent Dirichlet allocation (LDA). Based on the synchronous belief propagation (BP) algorithm, we first develop a parallel belief propagation (PBP) algorithm on the parallel architecture. Because the extensive communication delay often causes a low efficiency of parallel topic modeling, we further use Zipf's law to reduce the total communication cost in PBP. Extensive experiments on different data sets demonstrate that CE-PBP achieves a higher topic modeling accuracy and reduces more than 80% communication cost than the state-of-the-art parallel Gibbs sampling (PGS) algorithm.
Memory-Efficient Topic Modeling
Jun 08, 2012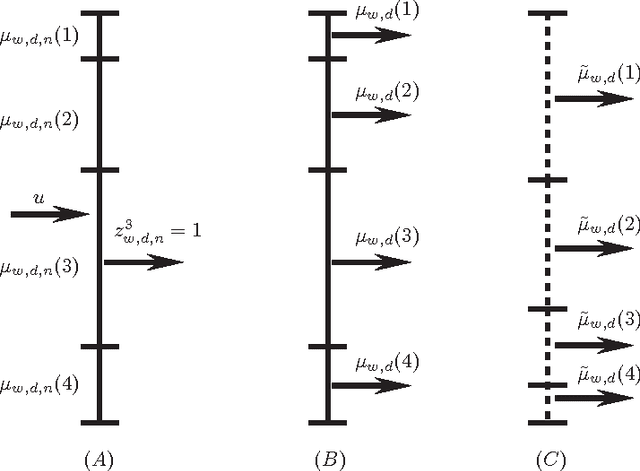

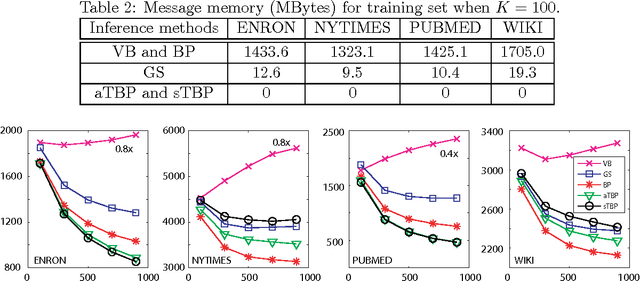
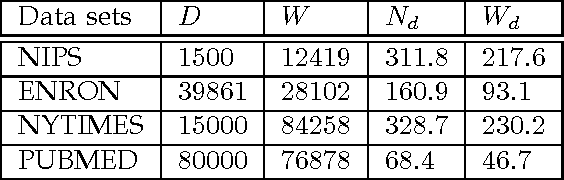
As one of the simplest probabilistic topic modeling techniques, latent Dirichlet allocation (LDA) has found many important applications in text mining, computer vision and computational biology. Recent training algorithms for LDA can be interpreted within a unified message passing framework. However, message passing requires storing previous messages with a large amount of memory space, increasing linearly with the number of documents or the number of topics. Therefore, the high memory usage is often a major problem for topic modeling of massive corpora containing a large number of topics. To reduce the space complexity, we propose a novel algorithm without storing previous messages for training LDA: tiny belief propagation (TBP). The basic idea of TBP relates the message passing algorithms with the non-negative matrix factorization (NMF) algorithms, which absorb the message updating into the message passing process, and thus avoid storing previous messages. Experimental results on four large data sets confirm that TBP performs comparably well or even better than current state-of-the-art training algorithms for LDA but with a much less memory consumption. TBP can do topic modeling when massive corpora cannot fit in the computer memory, for example, extracting thematic topics from 7 GB PUBMED corpora on a common desktop computer with 2GB memory.
Residual Belief Propagation for Topic Modeling
Apr 30, 2012
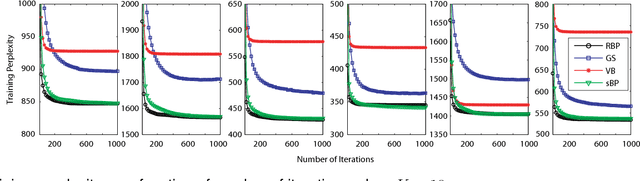
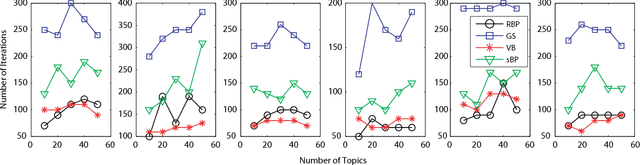
Fast convergence speed is a desired property for training latent Dirichlet allocation (LDA), especially in online and parallel topic modeling for massive data sets. This paper presents a novel residual belief propagation (RBP) algorithm to accelerate the convergence speed for training LDA. The proposed RBP uses an informed scheduling scheme for asynchronous message passing, which passes fast-convergent messages with a higher priority to influence those slow-convergent messages at each learning iteration. Extensive empirical studies confirm that RBP significantly reduces the training time until convergence while achieves a much lower predictive perplexity than other state-of-the-art training algorithms for LDA, including variational Bayes (VB), collapsed Gibbs sampling (GS), loopy belief propagation (BP), and residual VB (RVB).
* 6 pages, 8 figures