 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Generalisation to Unseen Viewpoints, Articulations, Shapes and Objects for 3D Hand Pose Estimation under Hand-Object Interaction
Mar 30, 2020
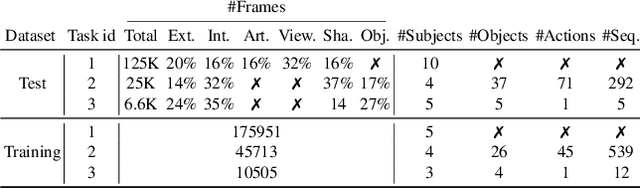
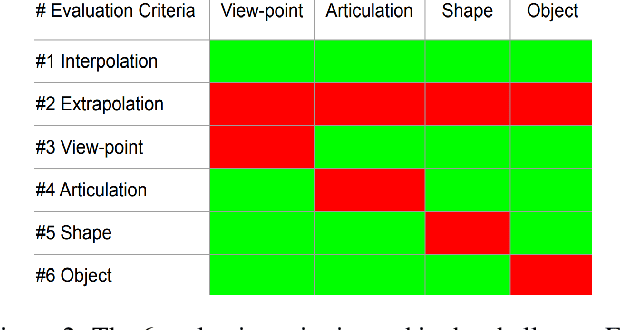
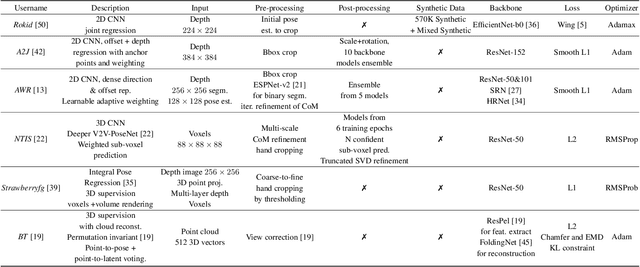
In this work, we study how well different type of approaches generalise in the task of 3D hand pose estimation under hand-object interaction and single hand scenarios. We show that the accuracy of state-of-the-art methods can drop, and that they fail mostly on poses absent from the training set. Unfortunately, since the space of hand poses is highly dimensional, it is inherently not feasible to cover the whole space densely, despite recent efforts in collecting large-scale training datasets. This sampling problem is even more severe when hands are interacting with objects and/or inputs are RGB rather than depth images, as RGB images also vary with lighting conditions and colors. To address these issues, we designed a public challenge to evaluate the abilities of current 3D hand pose estimators~(HPEs) to interpolate and extrapolate the poses of a training set. More exactly, our challenge is designed (a) to evaluate the influence of both depth and color modalities on 3D hand pose estimation, under the presence or absence of objects; (b) to assess the generalisation abilities \wrt~four main axes: shapes, articulations, viewpoints, and objects; (c) to explore the use of a synthetic hand model to fill the gaps of current datasets. Through the challenge, the overall accuracy has dramatically improved over the baseline, especially on extrapolation tasks, from 27mm to 13mm mean joint error. Our analyses highlight the impacts of: Data pre-processing, ensemble approaches, the use of MANO model, and different HPE methods/backbones.
HMTNet:3D Hand Pose Estimation from Single Depth Image Based on Hand Morphological Topology
Nov 12, 2019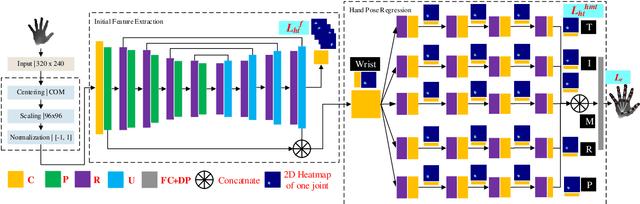
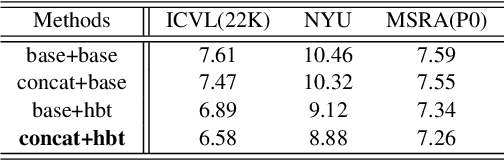
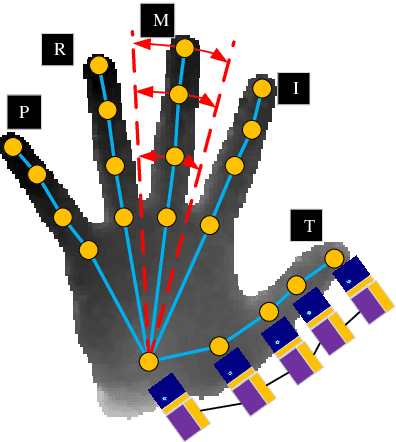
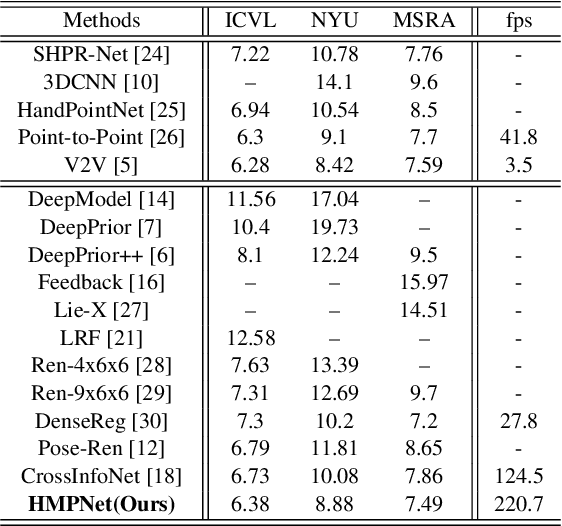
Thanks to the rapid development of CNNs and depth sensors, great progress has been made in 3D hand pose estimation. Nevertheless, it is still far from being solved for its cluttered circumstance and severe self-occlusion of hand. In this paper, we propose a method that takes advantage of human hand morphological topology (HMT) structure to improve the pose estimation performance. The main contributions of our work can be listed as below. Firstly, in order to extract more powerful features, we concatenate original and last layer of initial feature extraction module to preserve hand information better. Next, regression module inspired from hand morphological topology is proposed. In this submodule, we design a tree-like network structure according to hand joints distribution to make use of high order dependency of hand joints. Lastly, we conducted sufficient ablation experiments to verify our proposed method on each dataset. Experimental results on three popular hand pose dataset show superior performance of our method compared with the state-of-the-art methods. On ICVL and NYU dataset, our method outperforms great improvement over 2D state-of-the-art methods. On MSRA dataset, our method achieves comparable accuracy with the state-of-the-art methods. To summarize, our method is the most efficient method which can run at 220:7 fps on a single GPU compared with approximate accurate methods at present. The code will be available at.