 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel In-context Learning for Large Vision Language Models
Mar 17, 2026Large vision-language models (LVLMs) employ multi-modal in-context learning (MM-ICL) to adapt to new tasks by leveraging demonstration examples. While increasing the number of demonstrations boosts performance, they incur significant inference latency due to the quadratic computational cost of Transformer attention with respect to the context length. To address this trade-off, we propose Parallel In-Context Learning (Parallel-ICL), a plug-and-play inference algorithm. Parallel-ICL partitions the long demonstration context into multiple shorter, manageable chunks. It processes these chunks in parallel and integrates their predictions at the logit level, using a weighted Product-of-Experts (PoE) ensemble to approximate the full-context output. Guided by ensemble learning theory, we introduce principled strategies for Parallel-ICL: (i) clustering-based context chunking to maximize inter-chunk diversity and (ii) similarity-based context compilation to weight predictions by query relevance. Extensive experiments on VQA, image captioning, and classification benchmarks demonstrate that Parallel-ICL achieves performance comparable to full-context MM-ICL, while significantly improving inference speed. Our work offers an effective solution to the accuracy-efficiency trade-off in MM-ICL, enabling dynamic task adaptation with substantially reduced inference overhead.
MultiModal Fine-tuning with Synthetic Captions
Jan 29, 2026In this paper, we address a fundamental gap between pre-training and fine-tuning of deep neural networks: while pre-training has shifted from unimodal to multimodal learning with enhanced visual understanding, fine-tuning predominantly remains unimodal, limiting the benefits of rich pre-trained representations. To bridge this gap, we propose a novel approach that transforms unimodal datasets into multimodal ones using Multimodal Large Language Models (MLLMs) to generate synthetic image captions for fine-tuning models with a multimodal objective. Our method employs carefully designed prompts incorporating class labels and domain context to produce high-quality captions tailored for classification tasks. Furthermore, we introduce a supervised contrastive loss function that explicitly encourages clustering of same-class representations during fine-tuning, along with a new inference technique that leverages class-averaged text embeddings from multiple synthetic captions per image. Extensive experiments across 13 image classification benchmarks demonstrate that our approach outperforms baseline methods, with particularly significant improvements in few-shot learning scenarios. Our work establishes a new paradigm for dataset enhancement that effectively bridges the gap between multimodal pre-training and fine-tuning. Our code is available at https://github.com/s-enmt/MMFT.
Difference Vector Equalization for Robust Fine-tuning of Vision-Language Models
Nov 13, 2025



Contrastive pre-trained vision-language models, such as CLIP, demonstrate strong generalization abilities in zero-shot classification by leveraging embeddings extracted from image and text encoders. This paper aims to robustly fine-tune these vision-language models on in-distribution (ID) data without compromising their generalization abilities in out-of-distribution (OOD) and zero-shot settings. Current robust fine-tuning methods tackle this challenge by reusing contrastive learning, which was used in pre-training, for fine-tuning. However, we found that these methods distort the geometric structure of the embeddings, which plays a crucial role in the generalization of vision-language models, resulting in limited OOD and zero-shot performance. To address this, we propose Difference Vector Equalization (DiVE), which preserves the geometric structure during fine-tuning. The idea behind DiVE is to constrain difference vectors, each of which is obtained by subtracting the embeddings extracted from the pre-trained and fine-tuning models for the same data sample. By constraining the difference vectors to be equal across various data samples, we effectively preserve the geometric structure. Therefore, we introduce two losses: average vector loss (AVL) and pairwise vector loss (PVL). AVL preserves the geometric structure globally by constraining difference vectors to be equal to their weighted average. PVL preserves the geometric structure locally by ensuring a consistent multimodal alignment. Our experiments demonstrate that DiVE effectively preserves the geometric structure, achieving strong results across ID, OOD, and zero-shot metrics.
Rationale-Enhanced Decoding for Multi-modal Chain-of-Thought
Jul 10, 2025Large vision-language models (LVLMs) have demonstrated remarkable capabilities by integrating pre-trained vision encoders with large language models (LLMs). Similar to single-modal LLMs, chain-of-thought (CoT) prompting has been adapted for LVLMs to enhance multi-modal reasoning by generating intermediate rationales based on visual and textual inputs. While CoT is assumed to improve grounding and accuracy in LVLMs, our experiments reveal a key challenge: existing LVLMs often ignore the contents of generated rationales in CoT reasoning. To address this, we re-formulate multi-modal CoT reasoning as a KL-constrained reward maximization focused on rationale-conditional log-likelihood. As the optimal solution, we propose rationale-enhanced decoding (RED), a novel plug-and-play inference-time decoding strategy. RED harmonizes visual and rationale information by multiplying distinct image-conditional and rationale-conditional next token distributions. Extensive experiments show that RED consistently and significantly improves reasoning over standard CoT and other decoding methods across multiple benchmarks and LVLMs. Our work offers a practical and effective approach to improve both the faithfulness and accuracy of CoT reasoning in LVLMs, paving the way for more reliable rationale-grounded multi-modal systems.
Uniformity First: Uniformity-aware Test-time Adaptation of Vision-language Models against Image Corruption
May 19, 2025Pre-trained vision-language models such as contrastive language-image pre-training (CLIP) have demonstrated a remarkable generalizability, which has enabled a wide range of applications represented by zero-shot classification. However, vision-language models still suffer when they face datasets with large gaps from training ones, i.e., distribution shifts. We found that CLIP is especially vulnerable to sensor degradation, a type of realistic distribution shift caused by sensor conditions such as weather, light, or noise. Collecting a new dataset from a test distribution for fine-tuning highly costs since sensor degradation occurs unexpectedly and has a range of variety. Thus, we investigate test-time adaptation (TTA) of zero-shot classification, which enables on-the-fly adaptation to the test distribution with unlabeled test data. Existing TTA methods for CLIP mainly focus on modifying image and text embeddings or predictions to address distribution shifts. Although these methods can adapt to domain shifts, such as fine-grained labels spaces or different renditions in input images, they fail to adapt to distribution shifts caused by sensor degradation. We found that this is because image embeddings are "corrupted" in terms of uniformity, a measure related to the amount of information. To make models robust to sensor degradation, we propose a novel method called uniformity-aware information-balanced TTA (UnInfo). To address the corruption of image embeddings, we introduce uniformity-aware confidence maximization, information-aware loss balancing, and knowledge distillation from the exponential moving average (EMA) teacher. Through experiments, we demonstrate that our UnInfo improves accuracy under sensor degradation by retaining information in terms of uniformity.
Post-pre-training for Modality Alignment in Vision-Language Foundation Models
Apr 17, 2025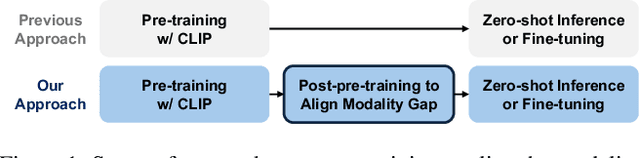
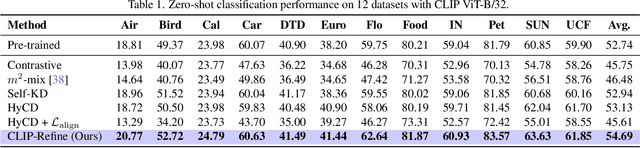
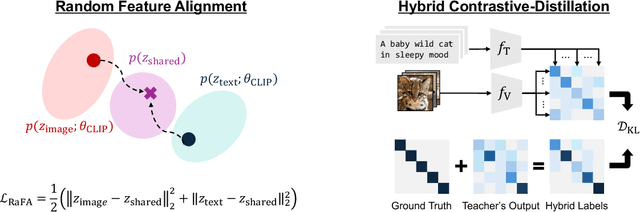
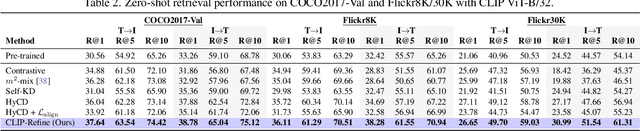
Contrastive language image pre-training (CLIP) is an essential component of building modern vision-language foundation models. While CLIP demonstrates remarkable zero-shot performance on downstream tasks, the multi-modal feature spaces still suffer from a modality gap, which is a gap between image and text feature clusters and limits downstream task performance. Although existing works attempt to address the modality gap by modifying pre-training or fine-tuning, they struggle with heavy training costs with large datasets or degradations of zero-shot performance. This paper presents CLIP-Refine, a post-pre-training method for CLIP models at a phase between pre-training and fine-tuning. CLIP-Refine aims to align the feature space with 1 epoch training on small image-text datasets without zero-shot performance degradations. To this end, we introduce two techniques: random feature alignment (RaFA) and hybrid contrastive-distillation (HyCD). RaFA aligns the image and text features to follow a shared prior distribution by minimizing the distance to random reference vectors sampled from the prior. HyCD updates the model with hybrid soft labels generated by combining ground-truth image-text pair labels and outputs from the pre-trained CLIP model. This contributes to achieving both maintaining the past knowledge and learning new knowledge to align features. Our extensive experiments with multiple classification and retrieval tasks show that CLIP-Refine succeeds in mitigating the modality gap and improving the zero-shot performance.
Zero-shot Concept Bottleneck Models
Feb 13, 2025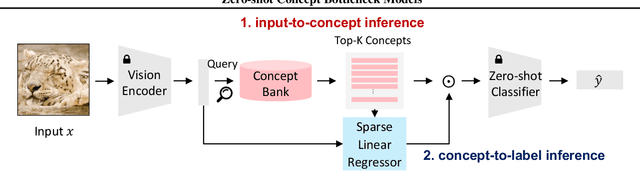

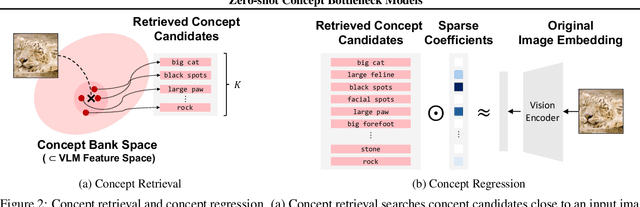

Concept bottleneck models (CBMs) are inherently interpretable and intervenable neural network models, which explain their final label prediction by the intermediate prediction of high-level semantic concepts. However, they require target task training to learn input-to-concept and concept-to-label mappings, incurring target dataset collections and training resources. In this paper, we present \textit{zero-shot concept bottleneck models} (Z-CBMs), which predict concepts and labels in a fully zero-shot manner without training neural networks. Z-CBMs utilize a large-scale concept bank, which is composed of millions of vocabulary extracted from the web, to describe arbitrary input in various domains. For the input-to-concept mapping, we introduce concept retrieval, which dynamically finds input-related concepts by the cross-modal search on the concept bank. In the concept-to-label inference, we apply concept regression to select essential concepts from the retrieved concepts by sparse linear regression. Through extensive experiments, we confirm that our Z-CBMs provide interpretable and intervenable concepts without any additional training. Code will be available at https://github.com/yshinya6/zcbm.
Test-time Adaptation for Regression by Subspace Alignment
Oct 04, 2024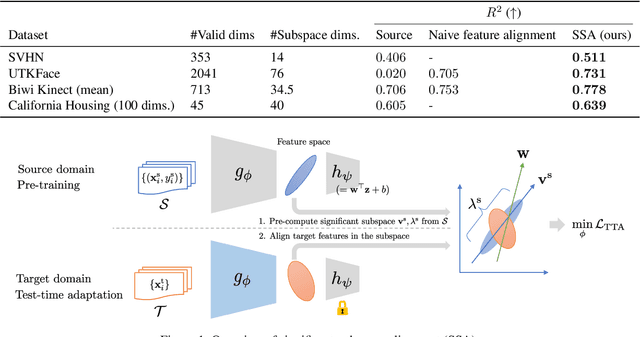
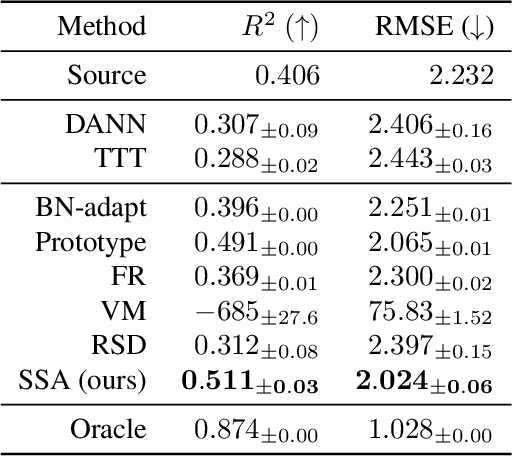
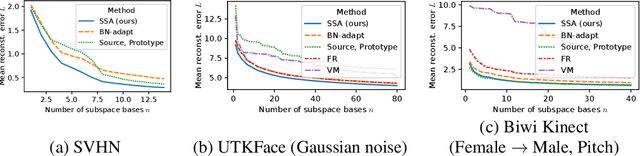
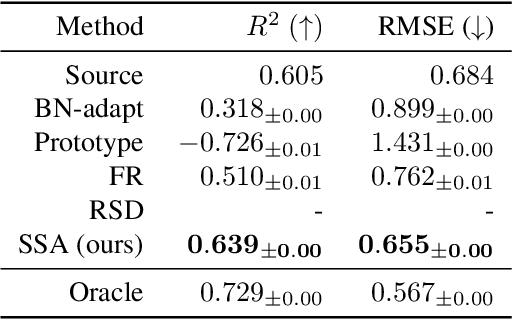
This paper investigates test-time adaptation (TTA) for regression, where a regression model pre-trained in a source domain is adapted to an unknown target distribution with unlabeled target data. Although regression is one of the fundamental tasks in machine learning, most of the existing TTA methods have classification-specific designs, which assume that models output class-categorical predictions, whereas regression models typically output only single scalar values. To enable TTA for regression, we adopt a feature alignment approach, which aligns the feature distributions between the source and target domains to mitigate the domain gap. However, we found that naive feature alignment employed in existing TTA methods for classification is ineffective or even worse for regression because the features are distributed in a small subspace and many of the raw feature dimensions have little significance to the output. For an effective feature alignment in TTA for regression, we propose Significant-subspace Alignment (SSA). SSA consists of two components: subspace detection and dimension weighting. Subspace detection finds the feature subspace that is representative and significant to the output. Then, the feature alignment is performed in the subspace during TTA. Meanwhile, dimension weighting raises the importance of the dimensions of the feature subspace that have greater significance to the output. We experimentally show that SSA outperforms various baselines on real-world datasets.
Explanation Bottleneck Models
Sep 26, 2024



Recent concept-based interpretable models have succeeded in providing meaningful explanations by pre-defined concept sets. However, the dependency on the pre-defined concepts restricts the application because of the limited number of concepts for explanations. This paper proposes a novel interpretable deep neural network called explanation bottleneck models (XBMs). XBMs generate a text explanation from the input without pre-defined concepts and then predict a final task prediction based on the generated explanation by leveraging pre-trained vision-language encoder-decoder models. To achieve both the target task performance and the explanation quality, we train XBMs through the target task loss with the regularization penalizing the explanation decoder via the distillation from the frozen pre-trained decoder. Our experiments, including a comparison to state-of-the-art concept bottleneck models, confirm that XBMs provide accurate and fluent natural language explanations without pre-defined concept sets. Code will be available at https://github.com/yshinya6/xbm/.
Evaluating Time-Series Training Dataset through Lens of Spectrum in Deep State Space Models
Aug 29, 2024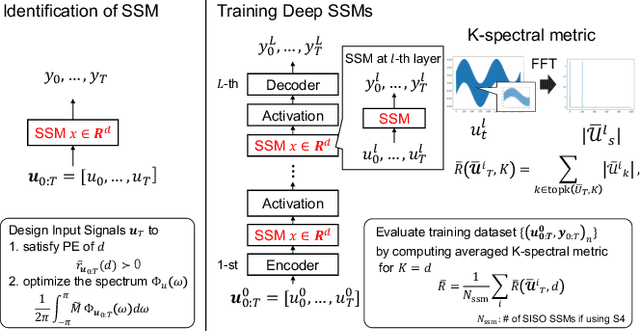

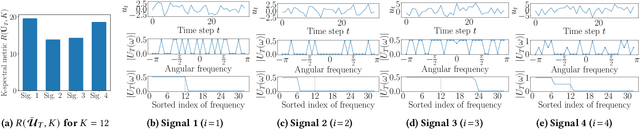
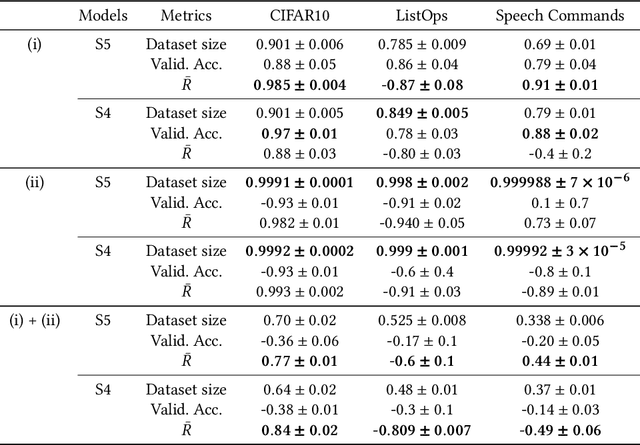
This study investigates a method to evaluate time-series datasets in terms of the performance of deep neural networks (DNNs) with state space models (deep SSMs) trained on the dataset. SSMs have attracted attention as components inside DNNs to address time-series data. Since deep SSMs have powerful representation capacities, training datasets play a crucial role in solving a new task. However, the effectiveness of training datasets cannot be known until deep SSMs are actually trained on them. This can increase the cost of data collection for new tasks, as a trial-and-error process of data collection and time-consuming training are needed to achieve the necessary performance. To advance the practical use of deep SSMs, the metric of datasets to estimate the performance early in the training can be one key element. To this end, we introduce the concept of data evaluation methods used in system identification. In system identification of linear dynamical systems, the effectiveness of datasets is evaluated by using the spectrum of input signals. We introduce this concept to deep SSMs, which are nonlinear dynamical systems. We propose the K-spectral metric, which is the sum of the top-K spectra of signals inside deep SSMs, by focusing on the fact that each layer of a deep SSM can be regarded as a linear dynamical system. Our experiments show that the K-spectral metric has a large absolute value of the correlation coefficient with the performance and can be used to evaluate the quality of training datasets.