 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Instance-wise Personalized Federated Learning via Semi-Implicit Bayesian Prompt Tuning
Aug 27, 2025Federated learning (FL) is a privacy-preserving machine learning paradigm that enables collaborative model training across multiple distributed clients without disclosing their raw data. Personalized federated learning (pFL) has gained increasing attention for its ability to address data heterogeneity. However, most existing pFL methods assume that each client's data follows a single distribution and learn one client-level personalized model for each client. This assumption often fails in practice, where a single client may possess data from multiple sources or domains, resulting in significant intra-client heterogeneity and suboptimal performance. To tackle this challenge, we propose pFedBayesPT, a fine-grained instance-wise pFL framework based on visual prompt tuning. Specifically, we formulate instance-wise prompt generation from a Bayesian perspective and model the prompt posterior as an implicit distribution to capture diverse visual semantics. We derive a variational training objective under the semi-implicit variational inference framework. Extensive experiments on benchmark datasets demonstrate that pFedBayesPT consistently outperforms existing pFL methods under both feature and label heterogeneity settings.
FedDEO: Description-Enhanced One-Shot Federated Learning with Diffusion Models
Jul 29, 2024In recent years, the attention towards One-Shot Federated Learning (OSFL) has been driven by its capacity to minimize communication. With the development of the diffusion model (DM), several methods employ the DM for OSFL, utilizing model parameters, image features, or textual prompts as mediums to transfer the local client knowledge to the server. However, these mediums often require public datasets or the uniform feature extractor, significantly limiting their practicality. In this paper, we propose FedDEO, a Description-Enhanced One-Shot Federated Learning Method with DMs, offering a novel exploration of utilizing the DM in OSFL. The core idea of our method involves training local descriptions on the clients, serving as the medium to transfer the knowledge of the distributed clients to the server. Firstly, we train local descriptions on the client data to capture the characteristics of client distributions, which are then uploaded to the server. On the server, the descriptions are used as conditions to guide the DM in generating synthetic datasets that comply with the distributions of various clients, enabling the training of the aggregated model. Theoretical analyses and sufficient quantitation and visualization experiments on three large-scale real-world datasets demonstrate that through the training of local descriptions, the server is capable of generating synthetic datasets with high quality and diversity. Consequently, with advantages in communication and privacy protection, the aggregated model outperforms compared FL or diffusion-based OSFL methods and, on some clients, outperforms the performance ceiling of centralized training.
FedRA: A Random Allocation Strategy for Federated Tuning to Unleash the Power of Heterogeneous Clients
Nov 19, 2023With the increasing availability of Foundation Models, federated tuning has garnered attention in the field of federated learning, utilizing data and computation resources from multiple clients to collaboratively fine-tune foundation models. However, in real-world federated scenarios, there often exist a multitude of heterogeneous clients with varying computation and communication resources, rendering them incapable of supporting the entire model fine-tuning process. In response to this challenge, we propose a novel federated tuning algorithm, FedRA. The implementation of FedRA is straightforward and can be seamlessly integrated into any transformer-based model without the need for further modification to the original model. Specifically, in each communication round, FedRA randomly generates an allocation matrix. For resource-constrained clients, it reorganizes a small number of layers from the original model based on the allocation matrix and fine-tunes using LoRA. Subsequently, the server aggregates the updated LoRA parameters from the clients according to the current allocation matrix into the corresponding layers of the original model. It is worth noting that FedRA also supports scenarios where none of the clients can support the entire global model, which is an impressive advantage. We conduct experiments on two large-scale image datasets, DomainNet and NICO++, under various non-iid settings. The results demonstrate that FedRA outperforms the compared methods significantly. The source code is available at \url{https://github.com/leondada/FedRA}.
One-Shot Federated Learning with Classifier-Guided Diffusion Models
Nov 16, 2023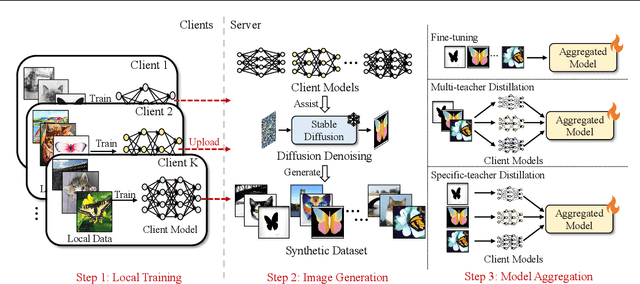
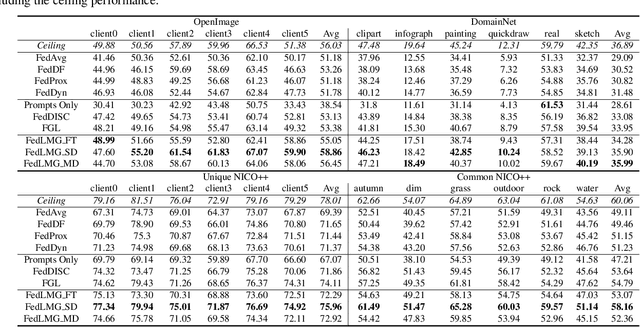
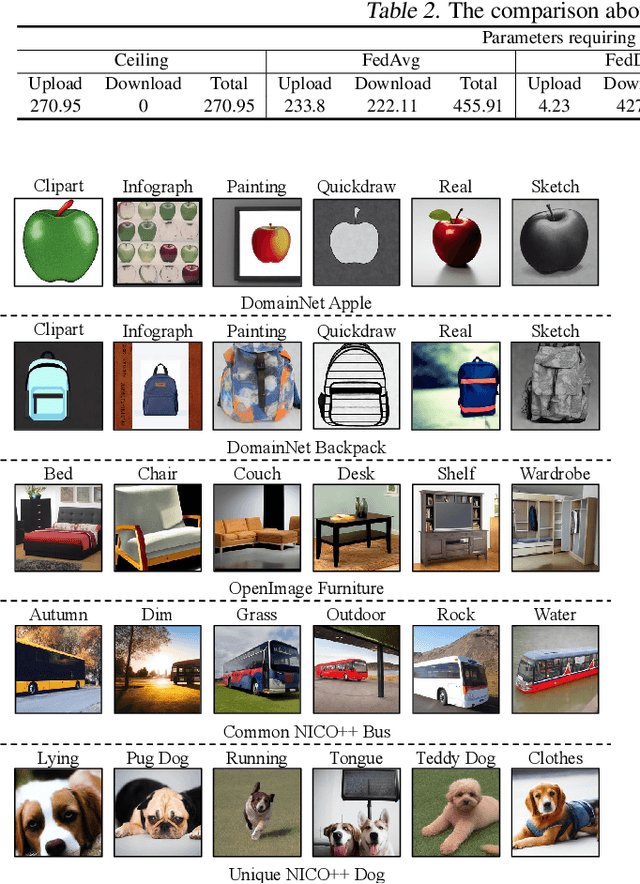

One-shot federated learning (OSFL) has gained attention in recent years due to its low communication cost. However, most of the existing methods require auxiliary datasets or training generators, which hinders their practicality in real-world scenarios. In this paper, we explore the novel opportunities that diffusion models bring to OSFL and propose FedCADO, utilizing guidance from client classifiers to generate data that complies with clients' distributions and subsequently training the aggregated model on the server. Specifically, our method involves targeted optimizations in two aspects. On one hand, we conditionally edit the randomly sampled initial noises, embedding them with specified semantics and distributions, resulting in a significant improvement in both the quality and stability of generation. On the other hand, we employ the BN statistics from the classifiers to provide detailed guidance during generation. These tailored optimizations enable us to limitlessly generate datasets, which closely resemble the distribution and quality of the original client dataset. Our method effectively handles the heterogeneous client models and the problems of non-IID features or labels. In terms of privacy protection, our method avoids training any generator or transferring any auxiliary information on clients, eliminating any additional privacy leakage risks. Leveraging the extensive knowledge stored in the pre-trained diffusion model, the synthetic datasets can assist us in surpassing the knowledge limitations of the client samples, resulting in aggregation models that even outperform the performance ceiling of centralized training in some cases, which is convincingly demonstrated in the sufficient quantification and visualization experiments conducted on three large-scale multi-domain image datasets.
Privacy-Preserving Collaborative Chinese Text Recognition with Federated Learning
May 09, 2023



In Chinese text recognition, to compensate for the insufficient local data and improve the performance of local few-shot character recognition, it is often necessary for one organization to collect a large amount of data from similar organizations. However, due to the natural presence of private information in text data, different organizations are unwilling to share private data, such as addresses and phone numbers. Therefore, it becomes increasingly important to design a privacy-preserving collaborative training framework for the Chinese text recognition task. In this paper, we introduce personalized federated learning (pFL) into the Chinese text recognition task and propose the pFedCR algorithm, which significantly improves the model performance of each client (organization) without sharing private data. Specifically, based on CRNN, to handle the non-iid problem of client data, we add several attention layers to the model and design a two-stage training approach for the client. In addition, we fine-tune the output layer of the model using a virtual dataset on the server, mitigating the problem of character imbalance in Chinese documents. The proposed approach is validated on public benchmarks and two self-built real-world industrial scenario datasets. The experimental results show that the pFedCR algorithm can improve the performance of local personalized models while also improving their generalization performance on other client data domains. Compared to local training within an organization, pFedCR improves model performance by about 20%. Compared to other state-of-the-art personalized federated learning methods, pFedCR improves performance by 6%~8%. Moreover, through federated learning, pFedCR can correct erroneous information in the ground truth.
Exploring One-shot Semi-supervised Federated Learning with A Pre-trained Diffusion Model
May 06, 2023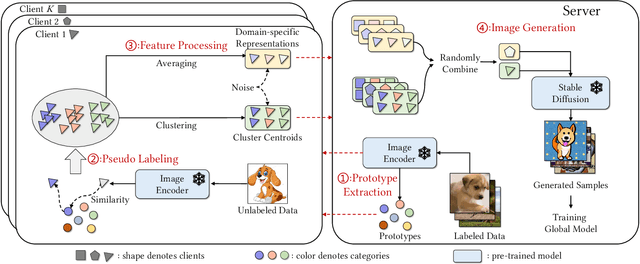
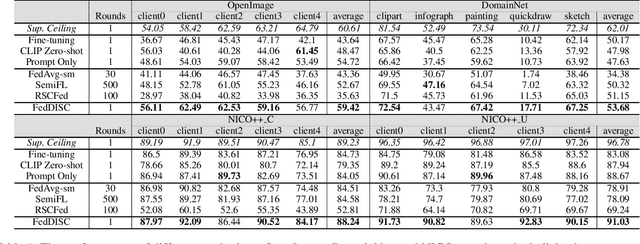
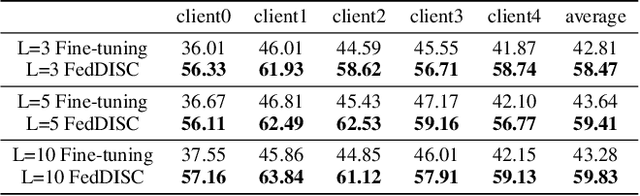
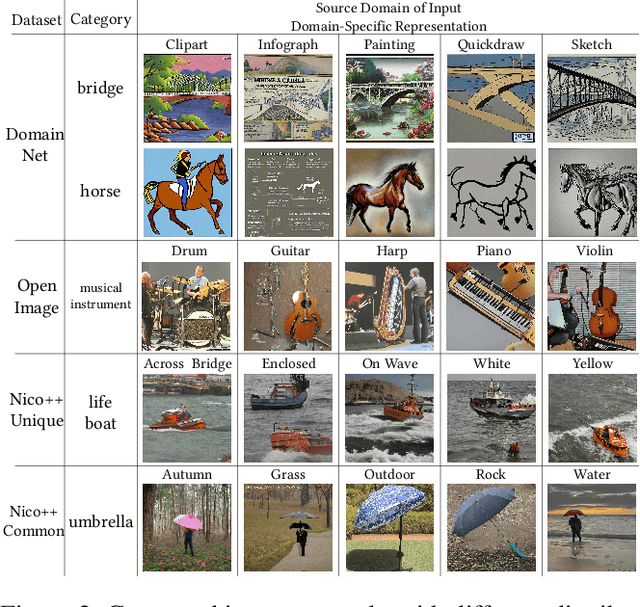
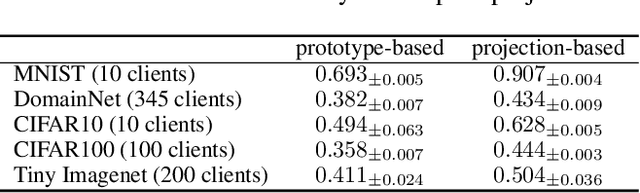
Federated learning is a privacy-preserving collaborative learning approach. Recently, some studies have proposed the semi-supervised federated learning setting to handle the commonly seen real-world scenarios with labeled data on the server and unlabeled data on the clients. However, existing methods still face challenges such as high communication costs, training pressure on the client devices, and distribution differences among the server and the clients. In this paper, we introduce the powerful pre-trained diffusion models into federated learning and propose FedDISC, a Federated Diffusion Inspired Semi-supervised Co-training method, to address these challenges. Specifically, we first extract prototypes from the labeled data on the server and send them to the clients. The clients then use these prototypes to predict pseudo-labels of the local data, and compute the cluster centroids and domain-specific features to represent their personalized distributions. After adding noise, the clients send these features and their corresponding pseudo-labels back to the server, which uses a pre-trained diffusion model to conditionally generate pseudo-samples complying with the client distributions and train an aggregated model on them. Our method does not require local training and only involves forward inference on the clients. Our extensive experiments on DomainNet, Openimage, and NICO++ demonstrate that the proposed FedDISC method effectively addresses the one-shot semi-supervised problem on Non-IID clients and outperforms the compared SOTA methods. We also demonstrate through visualization that it is of neglectable possibility for FedDISC to leak privacy-sensitive information of the clients.
Cross-domain Federated Adaptive Prompt Tuning for CLIP
Nov 15, 2022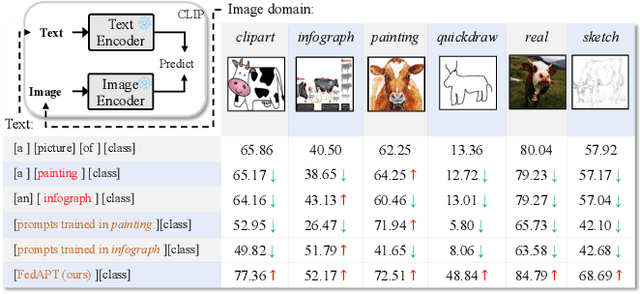
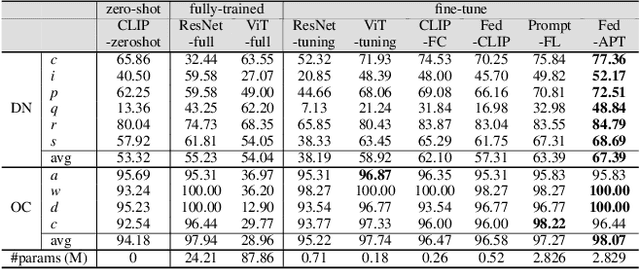
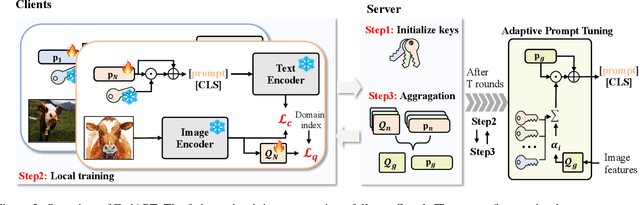
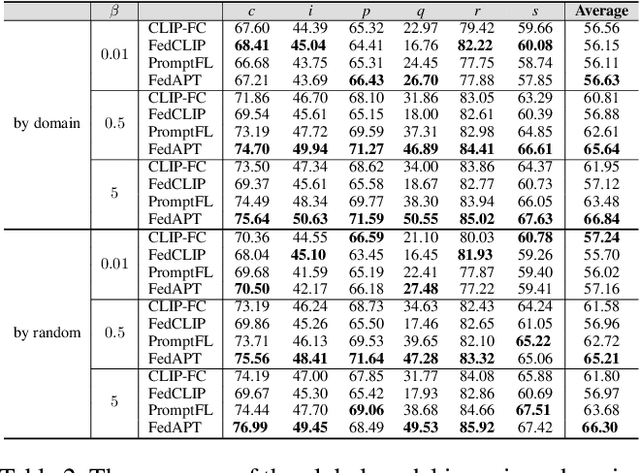
Federated learning (FL) allows multiple parties to collaboratively train a global model without disclosing their data. Existing research often requires all model parameters to participate in the training procedure. However, with the advent of powerful pre-trained models, it becomes possible to achieve higher performance with fewer learnable parameters in FL. In this paper, we propose a federated adaptive prompt tuning algorithm, FedAPT, for cross-domain federated image classification scenarios with the vision-language pre-trained model, CLIP, which gives play to the strong representation ability in FL. Compared with direct federated prompt tuning, our core idea is to adaptively unlock specific domain knowledge for each test sample in order to provide them with personalized prompts. To implement this idea, we design an adaptive prompt tuning module, which consists of a global prompt, an adaptive network, and some keys. The server randomly generates a set of keys and assigns a unique key to each client. Then all clients cooperatively train the global adaptive network and global prompt with the local datasets and the frozen keys. Ultimately, the global aggregation model can assign a personalized prompt to CLIP based on the domain features of each test sample. We perform extensive experiments on two multi-domain image classification datasets. The results show that FedAPT can achieve better performance with less than 10\% of the number of parameters of the fully trained model, and the global model can perform well in different client domains simultaneously.
Domain Discrepancy Aware Distillation for Model Aggregation in Federated Learning
Oct 04, 2022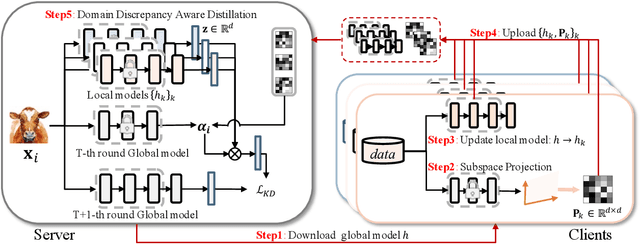
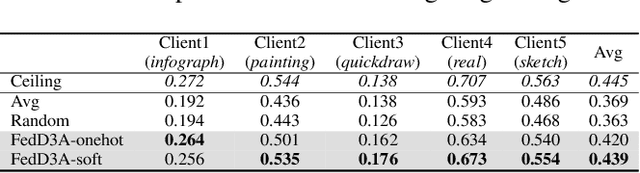

Knowledge distillation has recently become popular as a method of model aggregation on the server for federated learning. It is generally assumed that there are abundant public unlabeled data on the server. However, in reality, there exists a domain discrepancy between the datasets of the server domain and a client domain, which limits the performance of knowledge distillation. How to improve the aggregation under such a domain discrepancy setting is still an open problem. In this paper, we first analyze the generalization bound of the aggregation model produced from knowledge distillation for the client domains, and then describe two challenges, server-to-client discrepancy and client-to-client discrepancy, brought to the aggregation model by the domain discrepancies. Following our analysis, we propose an adaptive knowledge aggregation algorithm FedD3A based on domain discrepancy aware distillation to lower the bound. FedD3A performs adaptive weighting at the sample level in each round of FL. For each sample in the server domain, only the client models of its similar domains will be selected for playing the teacher role. To achieve this, we show that the discrepancy between the server-side sample and the client domain can be approximately measured using a subspace projection matrix calculated on each client without accessing its raw data. The server can thus leverage the projection matrices from multiple clients to assign weights to the corresponding teacher models for each server-side sample. We validate FedD3A on two popular cross-domain datasets and show that it outperforms the compared competitors in both cross-silo and cross-device FL settings.
Cross-domain Federated Object Detection
Jun 30, 2022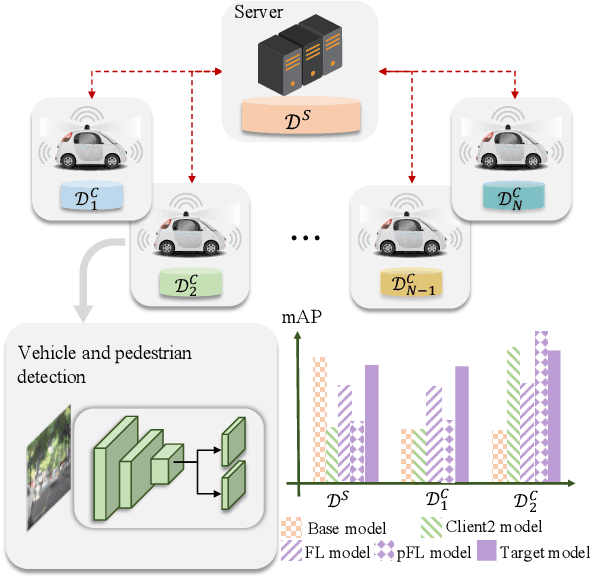
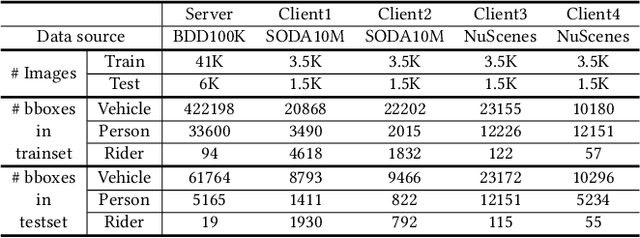
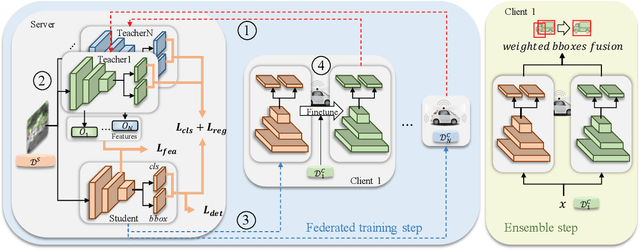
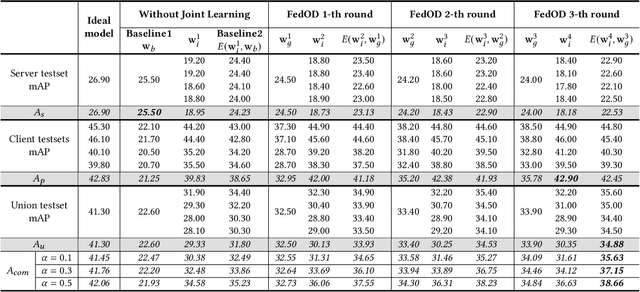
Detection models trained by one party (server) may face severe performance degradation when distributed to other users (clients). For example, in autonomous driving scenarios, different driving environments may bring obvious domain shifts, which lead to biases in model predictions. Federated learning that has emerged in recent years can enable multi-party collaborative training without leaking client data. In this paper, we focus on a special cross-domain scenario where the server contains large-scale data and multiple clients only contain a small amount of data; meanwhile, there exist differences in data distributions among the clients. In this case, traditional federated learning techniques cannot take into account the learning of both the global knowledge of all participants and the personalized knowledge of a specific client. To make up for this limitation, we propose a cross-domain federated object detection framework, named FedOD. In order to learn both the global knowledge and the personalized knowledge in different domains, the proposed framework first performs the federated training to obtain a public global aggregated model through multi-teacher distillation, and sends the aggregated model back to each client for finetuning its personalized local model. After very few rounds of communication, on each client we can perform weighted ensemble inference on the public global model and the personalized local model. With the ensemble, the generalization performance of the client-side model can outperform a single model with the same parameter scale. We establish a federated object detection dataset which has significant background differences and instance differences based on multiple public autonomous driving datasets, and then conduct extensive experiments on the dataset. The experimental results validate the effectiveness of the proposed method.
One-shot Federated Learning without Server-side Training
Apr 26, 2022
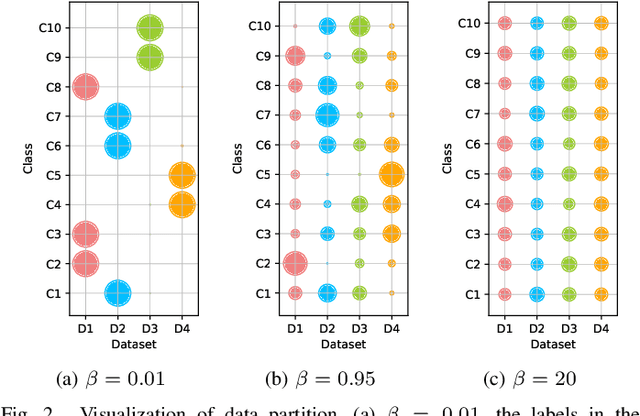
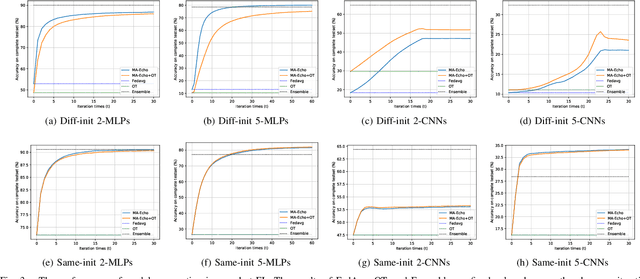
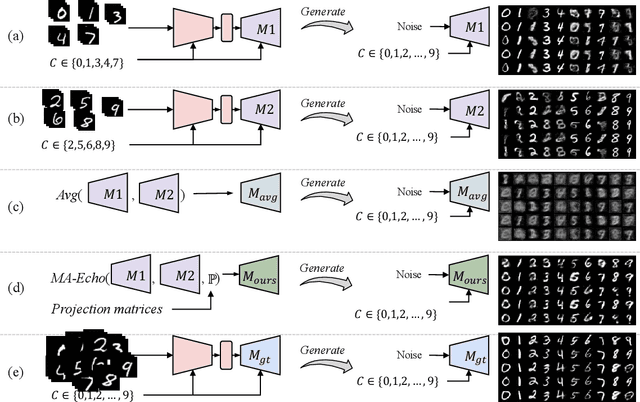
Federated Learning (FL) has recently made significant progress as a new machine learning paradigm for privacy protection. Due to the high communication cost of traditional FL, one-shot federated learning is gaining popularity as a way to reduce communication cost between clients and the server. Most of the existing one-shot FL methods are based on Knowledge Distillation; however, distillation based approach requires an extra training phase and depends on publicly available data sets. In this work, we consider a novel and challenging setting: performing a single round of parameter aggregation on the local models without server-side training on a public data set. In this new setting, we propose an effective algorithm for Model Aggregation via Exploring Common Harmonized Optima (MA-Echo), which iteratively updates the parameters of all local models to bring them close to a common low-loss area on the loss surface, without harming performance on their own data sets at the same time. Compared to the existing methods, MA-Echo can work well even in extremely non-identical data distribution settings where the support categories of each local model have no overlapped labels with those of the others. We conduct extensive experiments on two popular image classification data sets to compare the proposed method with existing methods and demonstrate the effectiveness of MA-Echo, which clearly outperforms the state-of-the-arts.