 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Discrepancy Aware Distillation for Model Aggregation in Federated Learning
Paper and Code
Oct 04, 2022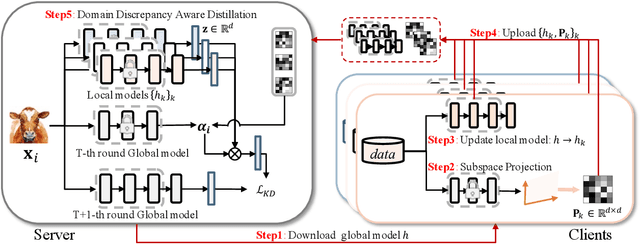
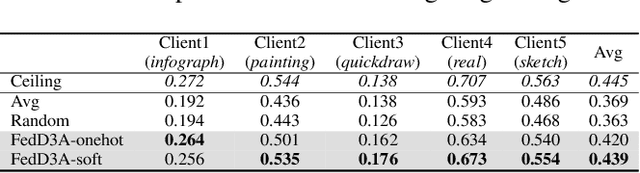

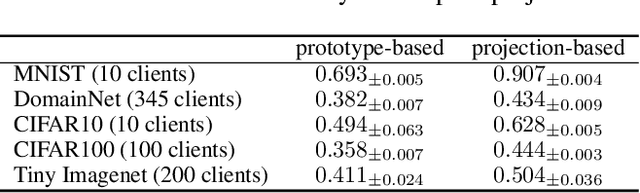
Knowledge distillation has recently become popular as a method of model aggregation on the server for federated learning. It is generally assumed that there are abundant public unlabeled data on the server. However, in reality, there exists a domain discrepancy between the datasets of the server domain and a client domain, which limits the performance of knowledge distillation. How to improve the aggregation under such a domain discrepancy setting is still an open problem. In this paper, we first analyze the generalization bound of the aggregation model produced from knowledge distillation for the client domains, and then describe two challenges, server-to-client discrepancy and client-to-client discrepancy, brought to the aggregation model by the domain discrepancies. Following our analysis, we propose an adaptive knowledge aggregation algorithm FedD3A based on domain discrepancy aware distillation to lower the bound. FedD3A performs adaptive weighting at the sample level in each round of FL. For each sample in the server domain, only the client models of its similar domains will be selected for playing the teacher role. To achieve this, we show that the discrepancy between the server-side sample and the client domain can be approximately measured using a subspace projection matrix calculated on each client without accessing its raw data. The server can thus leverage the projection matrices from multiple clients to assign weights to the corresponding teacher models for each server-side sample. We validate FedD3A on two popular cross-domain datasets and show that it outperforms the compared competitors in both cross-silo and cross-device FL settings.