 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanSplatHMR: Closing the Loop Between Human Mesh Recovery and Gaussian Splatting Avatar
May 04, 2026Accurately recovering human pose and appearance from video is an essential component of scene reconstruction, with applications to motion capture, motion prediction, virtual reality, and digital twinning. Despite significant interest in building realistic human avatars from video, this paper demonstrates that existing methods do not accurately recover the 3D geometry of humans. ViT-based approaches are not consistently reliable and can overfit to 2D views, while NeRF- and Gaussian Splatting-based avatars treat pose and appearance separately, limiting rendering generalization to new poses. To resolve these shortcomings, this paper proposes HumanSplatHMR, a joint optimization framework that refines 3D human poses while simultaneously learning a high-fidelity avatar for novel-view and novel-pose synthesis. Our key insight is to close the loop between geometric pose estimation and differentiable rendering. Unlike prior human avatar methods that rely on accurate human pose obtained through motion capture systems or offline refinement, which are impractical in in-the-wild scenarios, our approach uses only human mesh estimates from a state-of-the-art human pose estimator to better reflect real-world conditions. Therefore, instead of using the human pose only as a deformation prior, HumanSplatHMR backpropagates photometric, segmentation, and depth losses through a differentiable renderer to the pose parameters and global position. This coupling refines the global 3D pose over time, improving accuracy and alignment while producing better renderings from novel views. Experiments show consistent improvements over pose recovery baselines that omit image-level refinement and avatar baselines that decouple pose estimation from avatar reconstruction.
LongNav-R1: Horizon-Adaptive Multi-Turn RL for Long-Horizon VLA Navigation
Feb 12, 2026This paper develops LongNav-R1, an end-to-end multi-turn reinforcement learning (RL) framework designed to optimize Visual-Language-Action (VLA) models for long-horizon navigation. Unlike existing single-turn paradigm, LongNav-R1 reformulates the navigation decision process as a continuous multi-turn conversation between the VLA policy and the embodied environment. This multi-turn RL framework offers two distinct advantages: i) it enables the agent to reason about the causal effects of historical interactions and sequential future outcomes; and ii) it allows the model to learn directly from online interactions, fostering diverse trajectory generation and avoiding the behavioral rigidity often imposed by human demonstrations. Furthermore, we introduce Horizon-Adaptive Policy Optimization. This mechanism explicitly accounts for varying horizon lengths during advantage estimation, facilitating accurate temporal credit assignment over extended sequences. Consequently, the agent develops diverse navigation behaviors and resists collapse during long-horizon tasks. Experiments on object navigation benchmarks validate the framework's efficacy: With 4,000 rollout trajectories, LongNav-R1 boosts the Qwen3-VL-2B success rate from 64.3% to 73.0%. These results demonstrate superior sample efficiency and significantly outperform state-of-the-art methods. The model's generalizability and robustness are further validated by its zero-shot performance in long-horizon real-world navigation settings. All source code will be open-sourced upon publication.
SurfSLAM: Sim-to-Real Underwater Stereo Reconstruction For Real-Time SLAM
Jan 15, 2026Localization and mapping are core perceptual capabilities for underwater robots. Stereo cameras provide a low-cost means of directly estimating metric depth to support these tasks. However, despite recent advances in stereo depth estimation on land, computing depth from image pairs in underwater scenes remains challenging. In underwater environments, images are degraded by light attenuation, visual artifacts, and dynamic lighting conditions. Furthermore, real-world underwater scenes frequently lack rich texture useful for stereo depth estimation and 3D reconstruction. As a result, stereo estimation networks trained on in-air data cannot transfer directly to the underwater domain. In addition, there is a lack of real-world underwater stereo datasets for supervised training of neural networks. Poor underwater depth estimation is compounded in stereo-based Simultaneous Localization and Mapping (SLAM) algorithms, making it a fundamental challenge for underwater robot perception. To address these challenges, we propose a novel framework that enables sim-to-real training of underwater stereo disparity estimation networks using simulated data and self-supervised finetuning. We leverage our learned depth predictions to develop \algname, a novel framework for real-time underwater SLAM that fuses stereo cameras with IMU, barometric, and Doppler Velocity Log (DVL) measurements. Lastly, we collect a challenging real-world dataset of shipwreck surveys using an underwater robot. Our dataset features over 24,000 stereo pairs, along with high-quality, dense photogrammetry models and reference trajectories for evaluation. Through extensive experiments, we demonstrate the advantages of the proposed training approach on real-world data for improving stereo estimation in the underwater domain and for enabling accurate trajectory estimation and 3D reconstruction of complex shipwreck sites.
These Magic Moments: Differentiable Uncertainty Quantification of Radiance Field Models
Mar 20, 2025
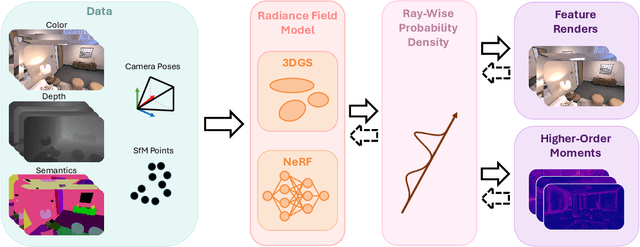
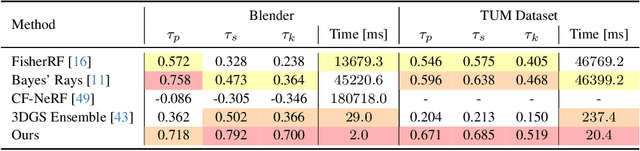

This paper introduces a novel approach to uncertainty quantification for radiance fields by leveraging higher-order moments of the rendering equation. Uncertainty quantification is crucial for downstream tasks including view planning and scene understanding, where safety and robustness are paramount. However, the high dimensionality and complexity of radiance fields pose significant challenges for uncertainty quantification, limiting the use of these uncertainty quantification methods in high-speed decision-making. We demonstrate that the probabilistic nature of the rendering process enables efficient and differentiable computation of higher-order moments for radiance field outputs, including color, depth, and semantic predictions. Our method outperforms existing radiance field uncertainty estimation techniques while offering a more direct, computationally efficient, and differentiable formulation without the need for post-processing. Beyond uncertainty quantification, we also illustrate the utility of our approach in downstream applications such as next-best-view (NBV) selection and active ray sampling for neural radiance field training. Extensive experiments on synthetic and real-world scenes confirm the efficacy of our approach, which achieves state-of-the-art performance while maintaining simplicity.
Conformalized Reachable Sets for Obstacle Avoidance With Spheres
Oct 13, 2024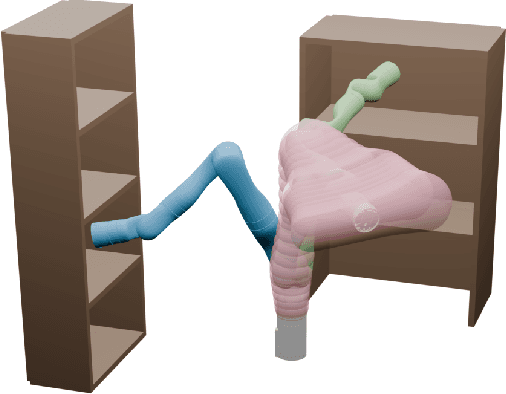
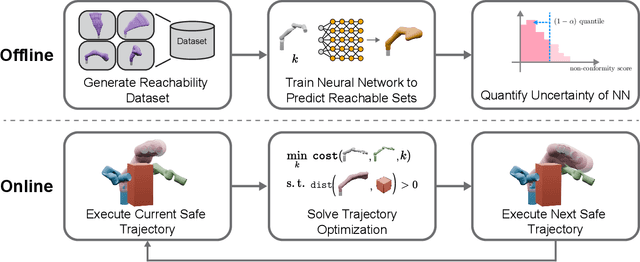
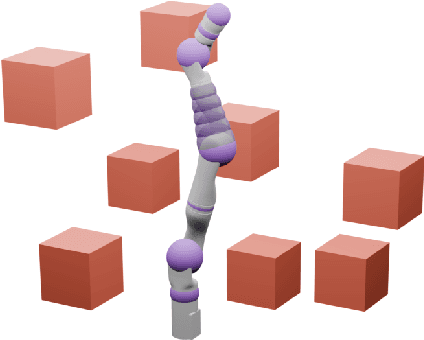
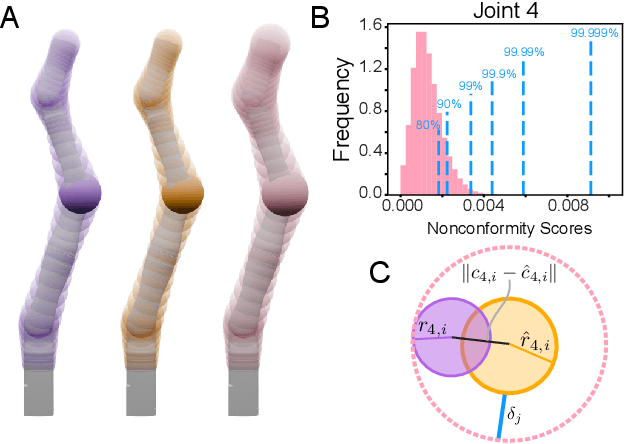
Safe motion planning algorithms are necessary for deploying autonomous robots in unstructured environments. Motion plans must be safe to ensure that the robot does not harm humans or damage any nearby objects. Generating these motion plans in real-time is also important to ensure that the robot can adapt to sudden changes in its environment. Many trajectory optimization methods introduce heuristics that balance safety and real-time performance, potentially increasing the risk of the robot colliding with its environment. This paper addresses this challenge by proposing Conformalized Reachable Sets for Obstacle Avoidance With Spheres (CROWS). CROWS is a novel real-time, receding-horizon trajectory planner that generates probalistically-safe motion plans. Offline, CROWS learns a novel neural network-based representation of a spherebased reachable set that overapproximates the swept volume of the robot's motion. CROWS then uses conformal prediction to compute a confidence bound that provides a probabilistic safety guarantee on the learned reachable set. At runtime, CROWS performs trajectory optimization to select a trajectory that is probabilstically-guaranteed to be collision-free. We demonstrate that CROWS outperforms a variety of state-of-the-art methods in solving challenging motion planning tasks in cluttered environments while remaining collision-free. Code, data, and video demonstrations can be found at https://roahmlab.github.io/crows/
Let's Make a Splan: Risk-Aware Trajectory Optimization in a Normalized Gaussian Splat
Sep 25, 2024


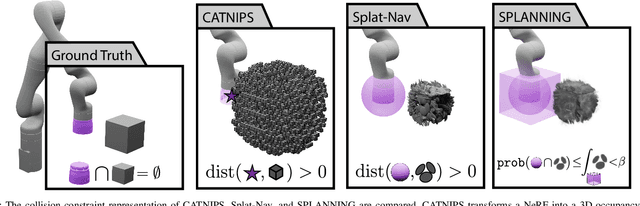
Neural Radiance Fields and Gaussian Splatting have transformed the field of computer vision by enabling photo-realistic representation of complex scenes. Despite this success, they have seen only limited use in real-world robotics tasks such as trajectory optimization. Two key factors have contributed to this limited success. First, it is challenging to reason about collisions in radiance models. Second, it is difficult to perform inference of radiance models fast enough for real-time trajectory synthesis. This paper addresses these challenges by proposing SPLANNING, a risk-aware trajectory optimizer that operates in a Gaussian Splatting model. This paper first derives a method for rigorously upper-bounding the probability of collision between a robot and a radiance field. Second, this paper introduces a normalized reformulation of Gaussian Splatting that enables the efficient computation of the collision bound in a Gaussian Splat. Third, a method is presented to optimize trajectories while avoiding collisions with a scene represented by a Gaussian Splat. Experiments demonstrate that SPLANNING outperforms state-of-the-art methods in generating collision-free trajectories in highly cluttered environments. The proposed system is also tested on a real-world robot manipulator. A project page is available at https://roahmlab.github.io/splanning.
LONER: LiDAR Only Neural Representations for Real-Time SLAM
Sep 12, 2023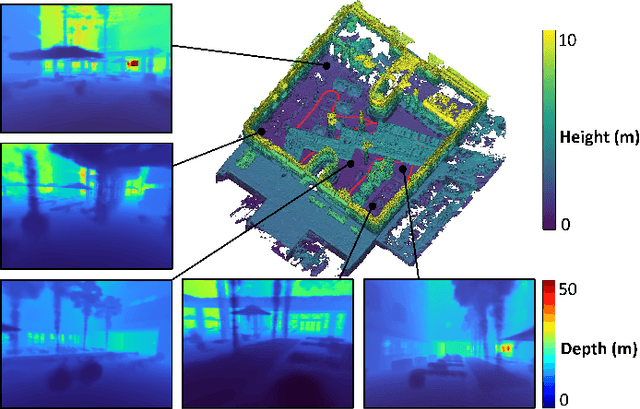
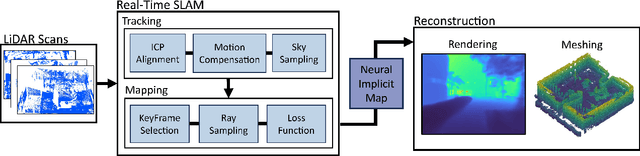
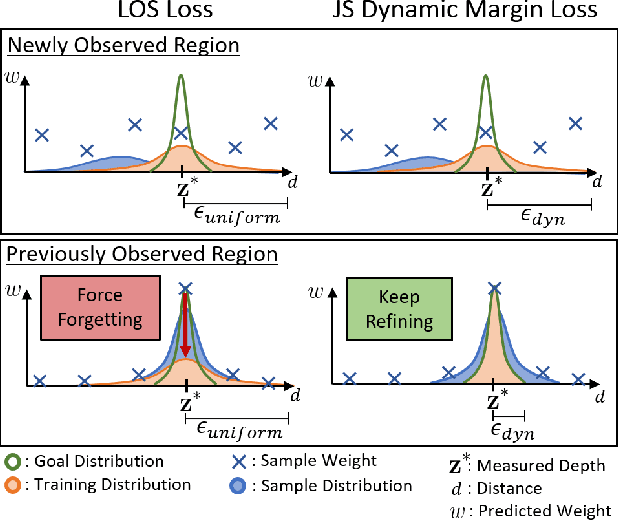
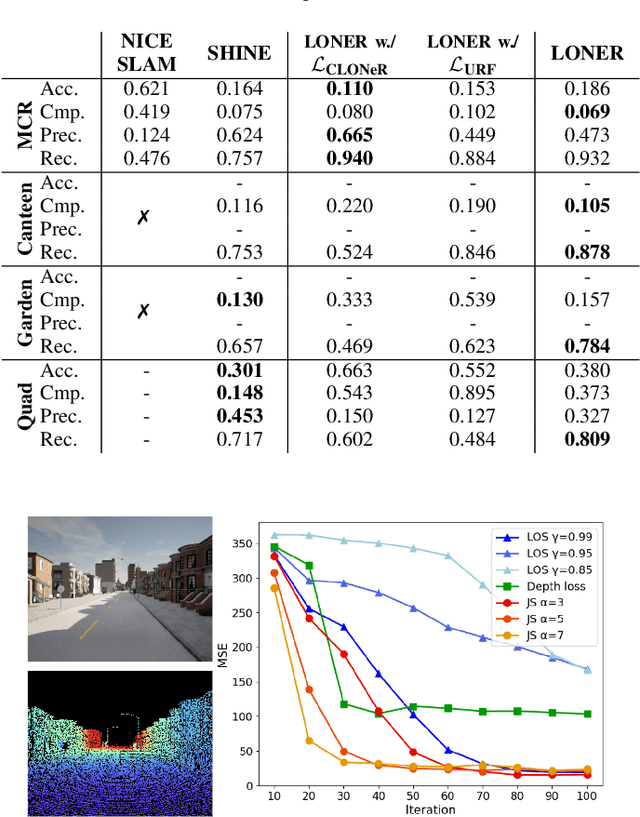
This paper proposes LONER, the first real-time LiDAR SLAM algorithm that uses a neural implicit scene representation. Existing implicit mapping methods for LiDAR show promising results in large-scale reconstruction, but either require groundtruth poses or run slower than real-time. In contrast, LONER uses LiDAR data to train an MLP to estimate a dense map in real-time, while simultaneously estimating the trajectory of the sensor. To achieve real-time performance, this paper proposes a novel information-theoretic loss function that accounts for the fact that different regions of the map may be learned to varying degrees throughout online training. The proposed method is evaluated qualitatively and quantitatively on two open-source datasets. This evaluation illustrates that the proposed loss function converges faster and leads to more accurate geometry reconstruction than other loss functions used in depth-supervised neural implicit frameworks. Finally, this paper shows that LONER estimates trajectories competitively with state-of-the-art LiDAR SLAM methods, while also producing dense maps competitive with existing real-time implicit mapping methods that use groundtruth poses.
MAD-TN: A Tool for Measuring Fluency in Human-Robot Collaboration
Sep 14, 2019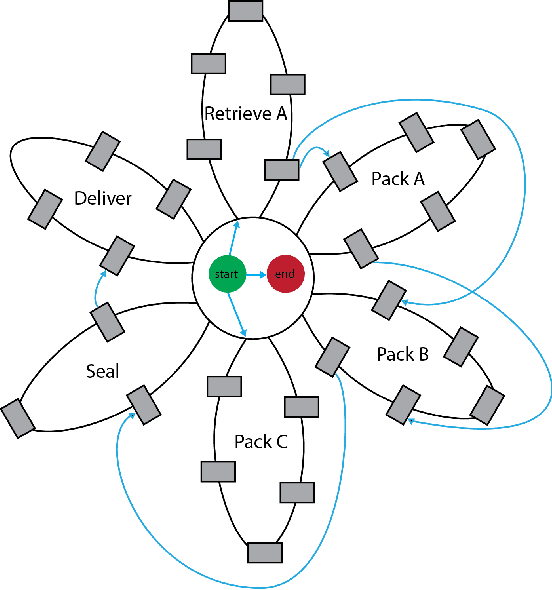
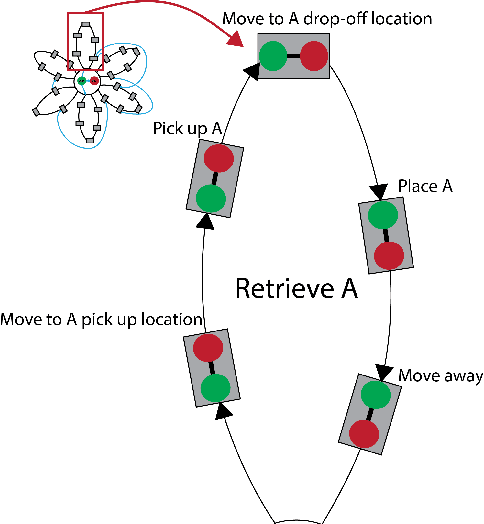
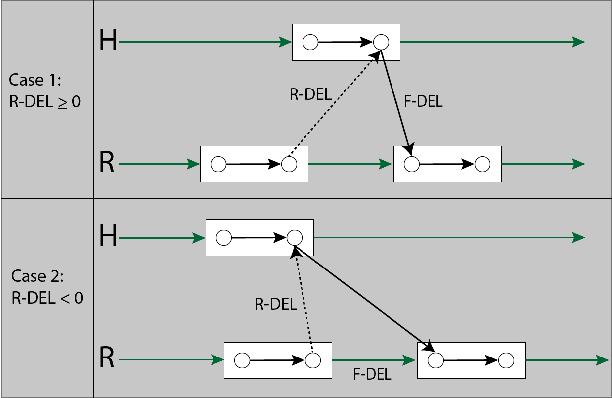
Fluency is an important metric in Human-Robot Interaction (HRI) that describes the coordination with which humans and robots collaborate on a task. Fluency is inherently linked to the timing of the task, making temporal constraint networks a promising way to model and measure fluency. We show that the Multi-Agent Daisy Temporal Network (MAD-TN) formulation, which expands on an existing concept of daisy-structured networks, is both an effective model of human-robot collaboration and a natural way to measure a number of existing fluency metrics. The MAD-TN model highlights new metrics that we hypothesize will strongly correlate with human teammates' perception of fluency.