 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet's Make a Splan: Risk-Aware Trajectory Optimization in a Normalized Gaussian Splat
Sep 25, 2024


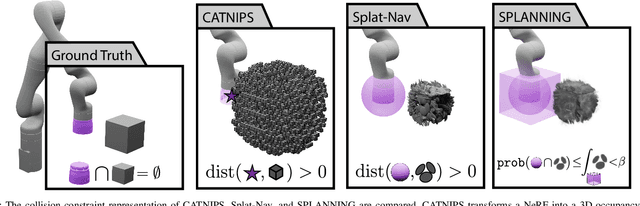
Neural Radiance Fields and Gaussian Splatting have transformed the field of computer vision by enabling photo-realistic representation of complex scenes. Despite this success, they have seen only limited use in real-world robotics tasks such as trajectory optimization. Two key factors have contributed to this limited success. First, it is challenging to reason about collisions in radiance models. Second, it is difficult to perform inference of radiance models fast enough for real-time trajectory synthesis. This paper addresses these challenges by proposing SPLANNING, a risk-aware trajectory optimizer that operates in a Gaussian Splatting model. This paper first derives a method for rigorously upper-bounding the probability of collision between a robot and a radiance field. Second, this paper introduces a normalized reformulation of Gaussian Splatting that enables the efficient computation of the collision bound in a Gaussian Splat. Third, a method is presented to optimize trajectories while avoiding collisions with a scene represented by a Gaussian Splat. Experiments demonstrate that SPLANNING outperforms state-of-the-art methods in generating collision-free trajectories in highly cluttered environments. The proposed system is also tested on a real-world robot manipulator. A project page is available at https://roahmlab.github.io/splanning.
OriCon3D: Effective 3D Object Detection using Orientation and Confidence
Apr 27, 2023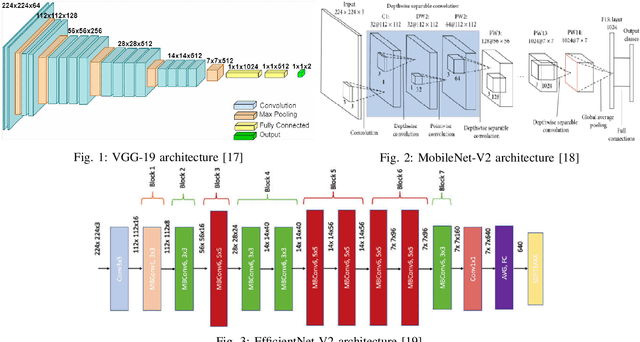
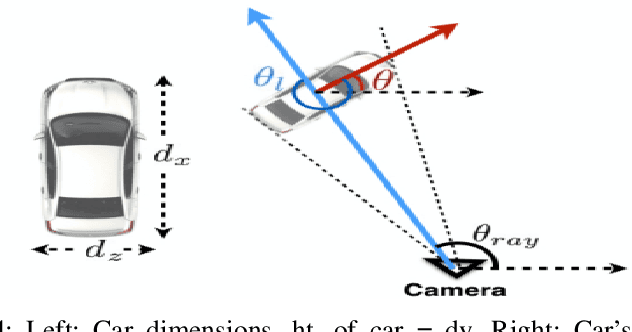
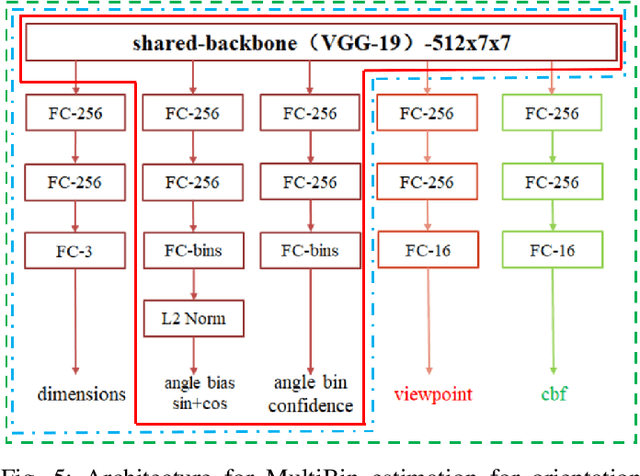
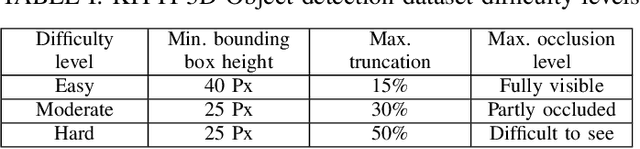
We introduce a technique for detecting 3D objects and estimating their position from a single image. Our method is built on top of a similar state-of-the-art technique [1], but with improved accuracy. The approach followed in this research first estimates common 3D properties of an object using a Deep Convolutional Neural Network (DCNN), contrary to other frameworks that only leverage centre-point predictions. We then combine these estimates with geometric constraints provided by a 2D bounding box to produce a complete 3D bounding box. The first output of our network estimates the 3D object orientation using a discrete-continuous loss [1]. The second output predicts the 3D object dimensions with minimal variance. Here we also present our extensions by augmenting light-weight feature extractors and a customized multibin architecture. By combining these estimates with the geometric constraints of the 2D bounding box, we can accurately (or comparatively) determine the 3D object pose better than our baseline [1] on the KITTI 3D detection benchmark [2].