 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPS-DRIFT: Marine Surface Robot Localization using IMU-GPS Fusion and Invariant Filtering
Jul 02, 2025This paper presents an extension of the DRIFT invariant state estimation framework, enabling robust fusion of GPS and IMU data for accurate pose and heading estimation. Originally developed for testing and usage on a marine autonomous surface vehicle (ASV), this approach can also be utilized on other mobile systems. Building upon the original proprioceptive only DRIFT algorithm, we develop a symmetry-preserving sensor fusion pipeline utilizing the invariant extended Kalman filter (InEKF) to integrate global position updates from GPS directly into the correction step. Crucially, we introduce a novel heading correction mechanism that leverages GPS course-over-ground information in conjunction with IMU orientation, overcoming the inherent unobservability of yaw in dead-reckoning. The system was deployed and validated on a customized Blue Robotics BlueBoat, but the methodological focus is on the algorithmic approach to fusing exteroceptive and proprioceptive sensors for drift-free localization and reliable orientation estimation. This work provides an open source solution for accurate yaw observation and localization in challenging or GPS-degraded conditions, and lays the groundwork for future experimental and comparative studies.
Twilight SLAM: A Comparative Study of Low-Light Visual SLAM Pipelines
Apr 27, 2023
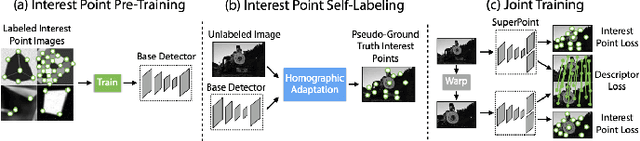
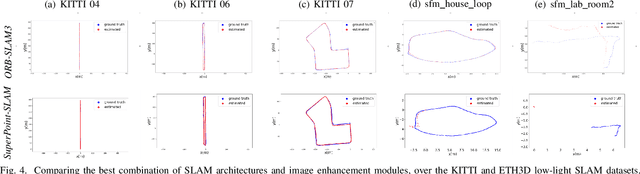
This paper presents a comparative study of low-light visual SLAM pipelines, specifically focusing on determining an efficient combination of the state-of-the-art low-light image enhancement algorithms with standard and contemporary Simultaneous Localization and Mapping (SLAM) frameworks by evaluating their performance in challenging low-light conditions. In this study, we investigate the performance of several different low-light SLAM pipelines for dark and/or poorly-lit datasets as opposed to just partially dim-lit datasets like other works in the literature. Our study takes an experimental approach to qualitatively and quantitatively compare the chosen combinations of modules to enhance the feature-based visual SLAM.
OriCon3D: Effective 3D Object Detection using Orientation and Confidence
Apr 27, 2023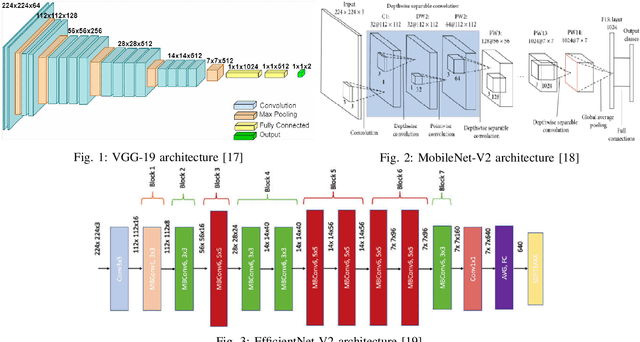
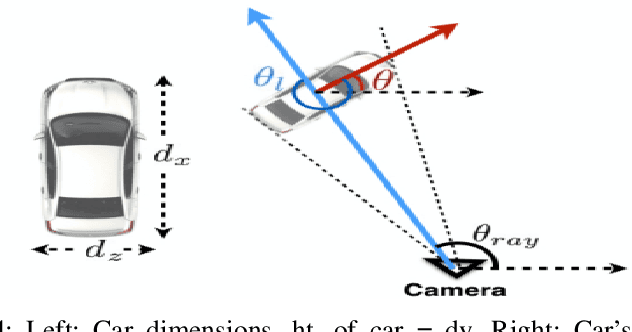
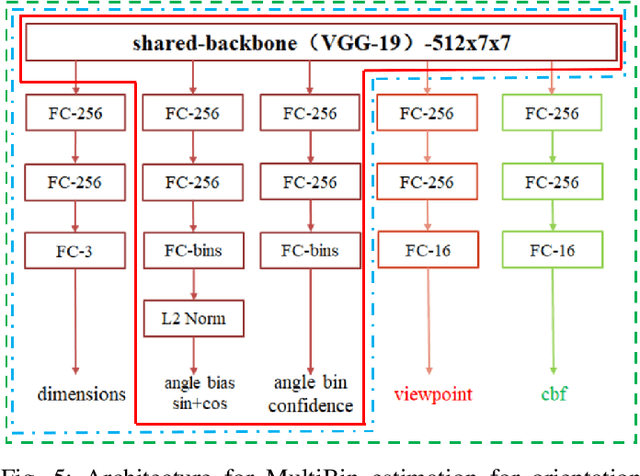
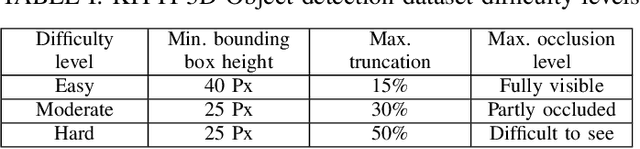
We introduce a technique for detecting 3D objects and estimating their position from a single image. Our method is built on top of a similar state-of-the-art technique [1], but with improved accuracy. The approach followed in this research first estimates common 3D properties of an object using a Deep Convolutional Neural Network (DCNN), contrary to other frameworks that only leverage centre-point predictions. We then combine these estimates with geometric constraints provided by a 2D bounding box to produce a complete 3D bounding box. The first output of our network estimates the 3D object orientation using a discrete-continuous loss [1]. The second output predicts the 3D object dimensions with minimal variance. Here we also present our extensions by augmenting light-weight feature extractors and a customized multibin architecture. By combining these estimates with the geometric constraints of the 2D bounding box, we can accurately (or comparatively) determine the 3D object pose better than our baseline [1] on the KITTI 3D detection benchmark [2].