 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe BiGGen Bench: A Principled Benchmark for Fine-grained Evaluation of Language Models with Language Models
Jun 09, 2024



As language models (LMs) become capable of handling a wide range of tasks, their evaluation is becoming as challenging as their development. Most generation benchmarks currently assess LMs using abstract evaluation criteria like helpfulness and harmlessness, which often lack the flexibility and granularity of human assessment. Additionally, these benchmarks tend to focus disproportionately on specific capabilities such as instruction following, leading to coverage bias. To overcome these limitations, we introduce the BiGGen Bench, a principled generation benchmark designed to thoroughly evaluate nine distinct capabilities of LMs across 77 diverse tasks. A key feature of the BiGGen Bench is its use of instance-specific evaluation criteria, closely mirroring the nuanced discernment of human evaluation. We apply this benchmark to assess 103 frontier LMs using five evaluator LMs. Our code, data, and evaluation results are all publicly available at https://github.com/prometheus-eval/prometheus-eval/tree/main/BiGGen-Bench.
The CoT Collection: Improving Zero-shot and Few-shot Learning of Language Models via Chain-of-Thought Fine-Tuning
May 23, 2023Large Language Models (LLMs) have shown enhanced capabilities of solving novel tasks by reasoning step-by-step known as Chain-of-Thought (CoT) reasoning; how can we instill the same capability of reasoning step-by-step on unseen tasks into LMs that possess less than <100B parameters? To address this question, we first introduce the CoT Collection, a new instruction-tuning dataset that augments 1.88 million CoT rationales across 1,060 tasks. We show that continually fine-tuning Flan-T5 (3B & 11B) with the CoT Collection enables the 3B & 11B LMs to perform CoT better on unseen tasks, leading to an improvement in the average zero-shot accuracy on 27 datasets of the BIG-Bench-Hard benchmark by +4.34% and +2.44%, respectively. Furthermore, we show that instruction tuning with CoT allows LMs to possess stronger few-shot learning capabilities, resulting in an improvement of +2.97% and +2.37% on 4 domain-specific tasks over Flan-T5 (3B & 11B), respectively. We make our CoT Collection data and our trained models publicly available at https://github.com/kaist-lklab/CoT-Collection.
CoTEVer: Chain of Thought Prompting Annotation Toolkit for Explanation Verification
Mar 07, 2023Chain-of-thought (CoT) prompting enables large language models (LLMs) to solve complex reasoning tasks by generating an explanation before the final prediction. Despite it's promising ability, a critical downside of CoT prompting is that the performance is greatly affected by the factuality of the generated explanation. To improve the correctness of the explanations, fine-tuning language models with explanation data is needed. However, there exists only a few datasets that can be used for such approaches, and no data collection tool for building them. Thus, we introduce CoTEVer, a tool-kit for annotating the factual correctness of generated explanations and collecting revision data of wrong explanations. Furthermore, we suggest several use cases where the data collected with CoTEVer can be utilized for enhancing the faithfulness of explanations. Our toolkit is publicly available at https://github.com/SeungoneKim/CoTEVer.
Mind the Gap! Injecting Commonsense Knowledge for Abstractive Dialogue Summarization
Sep 02, 2022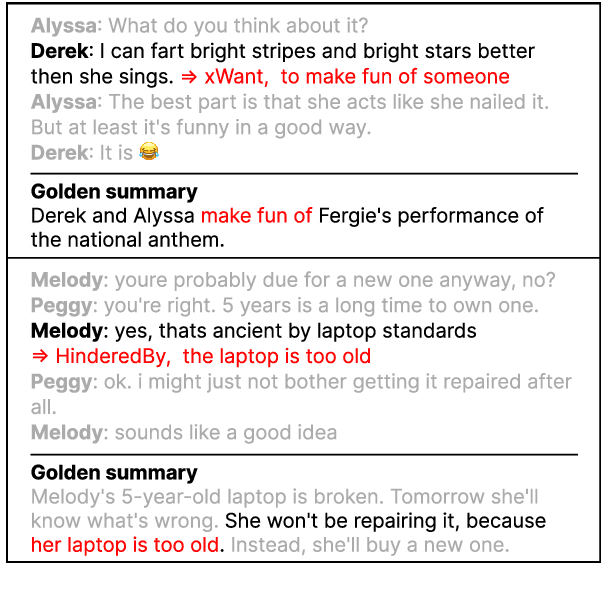



In this paper, we propose to leverage the unique characteristics of dialogues sharing commonsense knowledge across participants, to resolve the difficulties in summarizing them. We present SICK, a framework that uses commonsense inferences as additional context. Compared to previous work that solely relies on the input dialogue, SICK uses an external knowledge model to generate a rich set of commonsense inferences and selects the most probable one with a similarity-based selection method. Built upon SICK, SICK++ utilizes commonsense as supervision, where the task of generating commonsense inferences is added upon summarizing the dialogue in a multi-task learning setting. Experimental results show that with injected commonsense knowledge, our framework generates more informative and consistent summaries than existing methods.