 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Local Temporal Information for Multimodal Scene Classification
Oct 26, 2021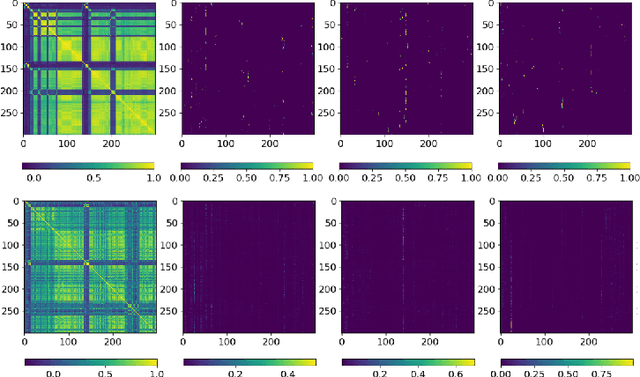

Robust video scene classification models should capture the spatial (pixel-wise) and temporal (frame-wise) characteristics of a video effectively. Transformer models with self-attention which are designed to get contextualized representations for individual tokens given a sequence of tokens, are becoming increasingly popular in many computer vision tasks. However, the use of Transformer based models for video understanding is still relatively unexplored. Moreover, these models fail to exploit the strong temporal relationships between the neighboring video frames to get potent frame-level representations. In this paper, we propose a novel self-attention block that leverages both local and global temporal relationships between the video frames to obtain better contextualized representations for the individual frames. This enables the model to understand the video at various granularities. We illustrate the performance of our models on the large scale YoutTube-8M data set on the task of video categorization and further analyze the results to showcase improvement.
Can't Fool Me: Adversarially Robust Transformer for Video Understanding
Oct 26, 2021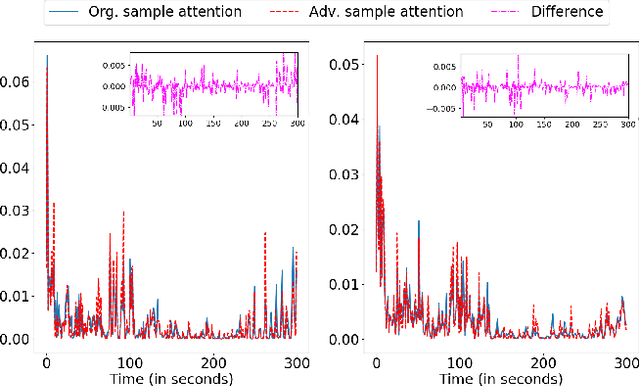
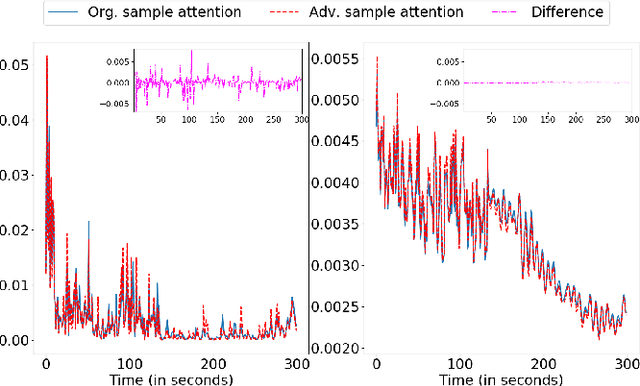


Deep neural networks have been shown to perform poorly on adversarial examples. To address this, several techniques have been proposed to increase robustness of a model for image classification tasks. However, in video understanding tasks, developing adversarially robust models is still unexplored. In this paper, we aim to bridge this gap. We first show that simple extensions of image based adversarially robust models slightly improve the worst-case performance. Further, we propose a temporal attention regularization scheme in Transformer to improve the robustness of attention modules to adversarial examples. We illustrate using a large-scale video data set YouTube-8M that the final model (A-ART) achieves close to non-adversarial performance on its adversarial example set. We achieve 91% GAP on adversarial examples, whereas baseline Transformer and simple adversarial extensions achieve 72.9% and 82% respectively, showing significant improvement in robustness over the state-of-the-art.
Enhancing Transformer for Video Understanding Using Gated Multi-Level Attention and Temporal Adversarial Training
Mar 18, 2021
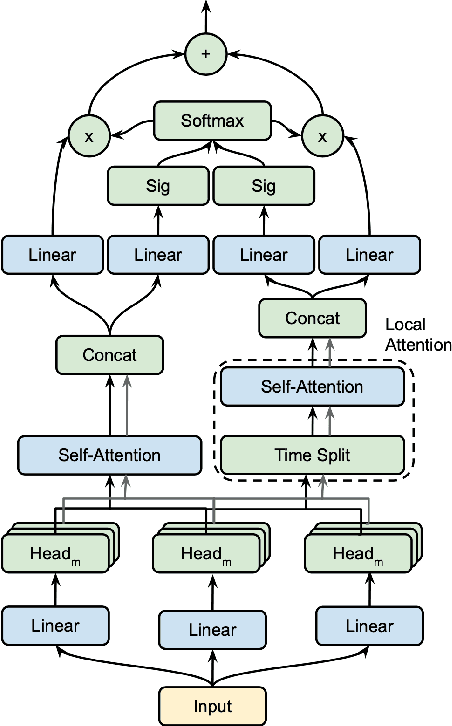


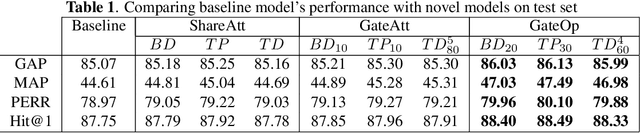
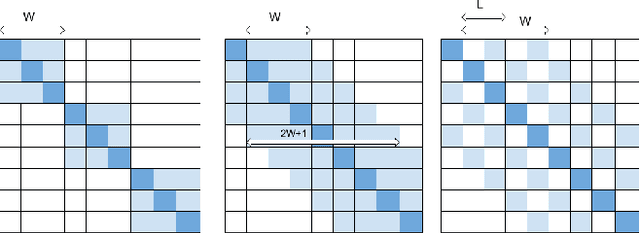
The introduction of Transformer model has led to tremendous advancements in sequence modeling, especially in text domain. However, the use of attention-based models for video understanding is still relatively unexplored. In this paper, we introduce Gated Adversarial Transformer (GAT) to enhance the applicability of attention-based models to videos. GAT uses a multi-level attention gate to model the relevance of a frame based on local and global contexts. This enables the model to understand the video at various granularities. Further, GAT uses adversarial training to improve model generalization. We propose temporal attention regularization scheme to improve the robustness of attention modules to adversarial examples. We illustrate the performance of GAT on the large-scale YoutTube-8M data set on the task of video categorization. We further show ablation studies along with quantitative and qualitative analysis to showcase the improvement.
Cross-modal Learning for Multi-modal Video Categorization
Mar 16, 2020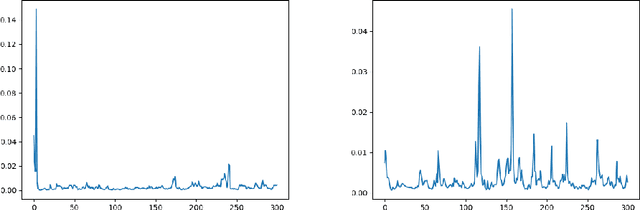
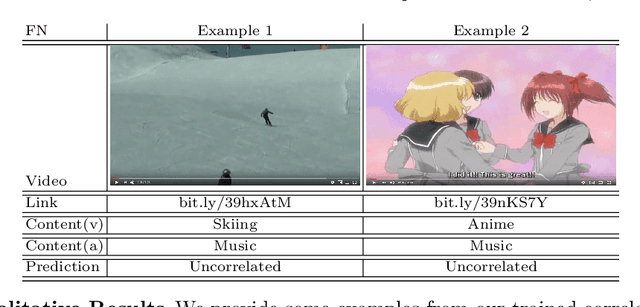
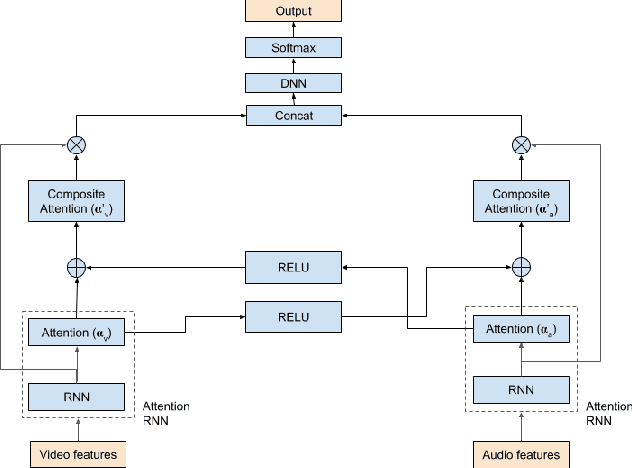
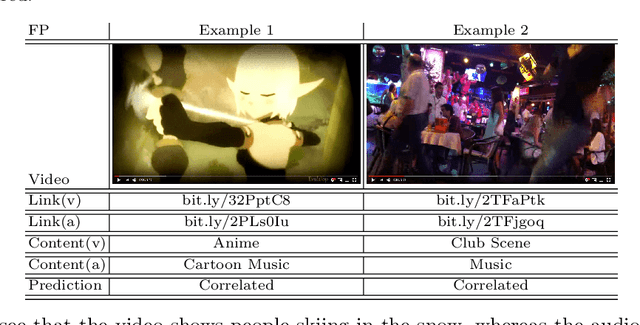
Multi-modal machine learning (ML) models can process data in multiple modalities (e.g., video, audio, text) and are useful for video content analysis in a variety of problems (e.g., object detection, scene understanding, activity recognition). In this paper, we focus on the problem of video categorization using a multi-modal ML technique. In particular, we have developed a novel multi-modal ML approach that we call "cross-modal learning", where one modality influences another but only when there is correlation between the modalities --- for that, we first train a correlation tower that guides the main multi-modal video categorization tower in the model. We show how this cross-modal principle can be applied to different types of models (e.g., RNN, Transformer, NetVLAD), and demonstrate through experiments how our proposed multi-modal video categorization models with cross-modal learning out-perform strong state-of-the-art baseline models.
Exploiting Temporal Coherence for Multi-modal Video Categorization
Feb 07, 2020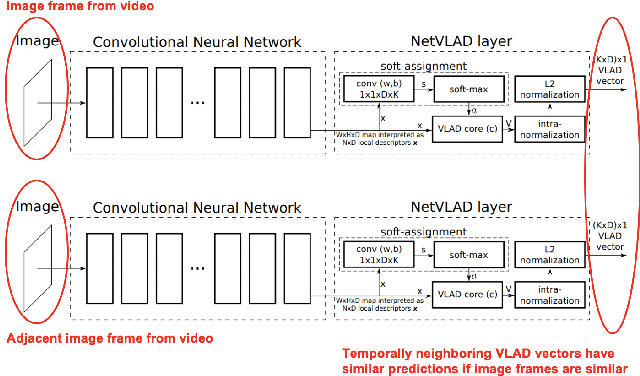
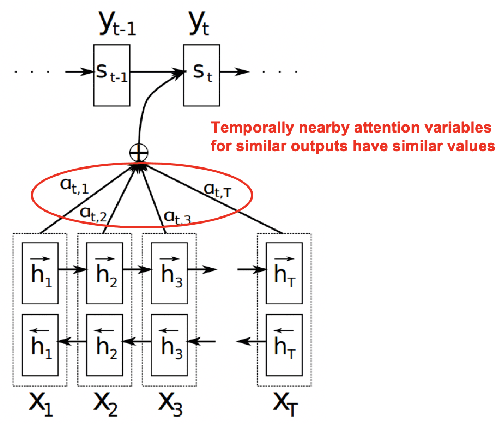
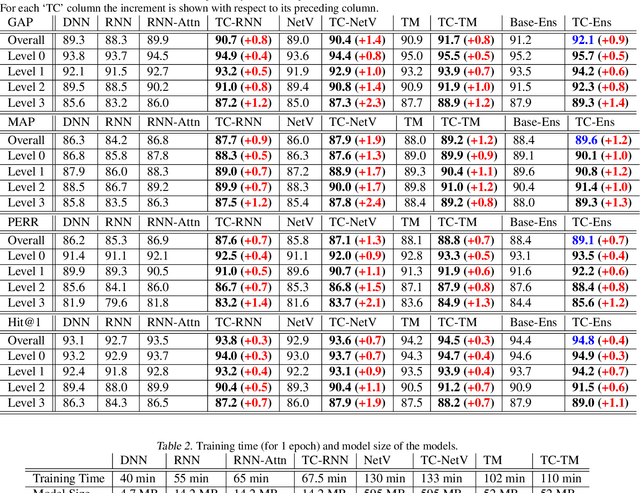
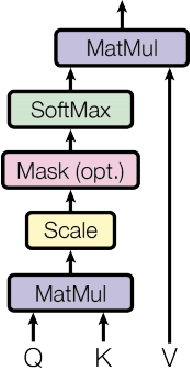
Multimodal ML models can process data in multiple modalities (e.g., video, images, audio, text) and are useful for video content analysis in a variety of problems (e.g., object detection, scene understanding). In this paper, we focus on the problem of video categorization by using a multimodal approach. We have developed a novel temporal coherence-based regularization approach, which applies to different types of models (e.g., RNN, NetVLAD, Transformer). We demonstrate through experiments how our proposed multimodal video categorization models with temporal coherence out-perform strong state-of-the-art baseline models.
Modeling Feature Representations for Affective Speech using Generative Adversarial Networks
Oct 31, 2019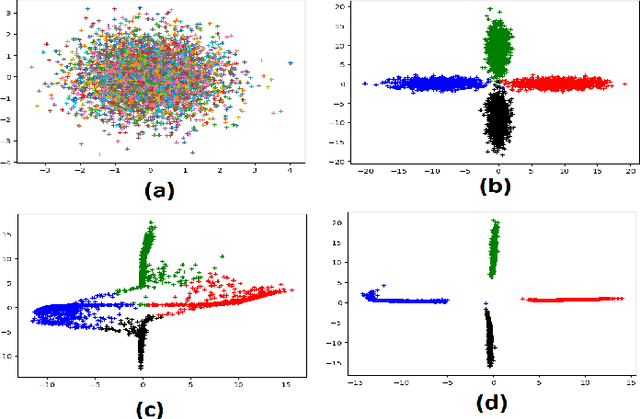
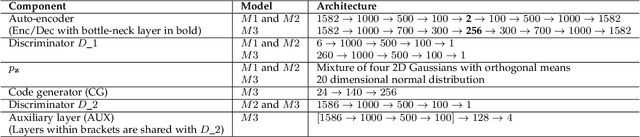
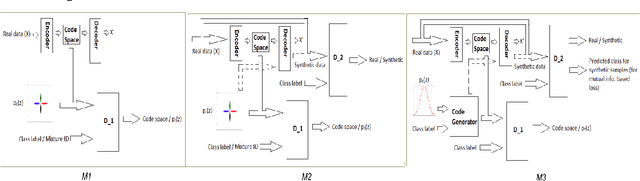

Emotion recognition is a classic field of research with a typical setup extracting features and feeding them through a classifier for prediction. On the other hand, generative models jointly capture the distributional relationship between emotions and the feature profiles. Relatively recently, Generative Adversarial Networks (GANs) have surfaced as a new class of generative models and have shown considerable success in modeling distributions in the fields of computer vision and natural language understanding. In this work, we experiment with variants of GAN architectures to generate feature vectors corresponding to an emotion in two ways: (i) A generator is trained with samples from a mixture prior. Each mixture component corresponds to an emotional class and can be sampled to generate features from the corresponding emotion. (ii) A one-hot vector corresponding to an emotion can be explicitly used to generate the features. We perform analysis on such models and also propose different metrics used to measure the performance of the GAN models in their ability to generate realistic synthetic samples. Apart from evaluation on a given dataset of interest, we perform a cross-corpus study where we study the utility of the synthetic samples as additional training data in low resource conditions.
On Enhancing Speech Emotion Recognition using Generative Adversarial Networks
Jun 18, 2018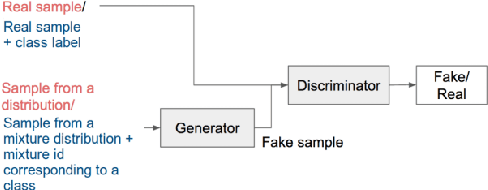
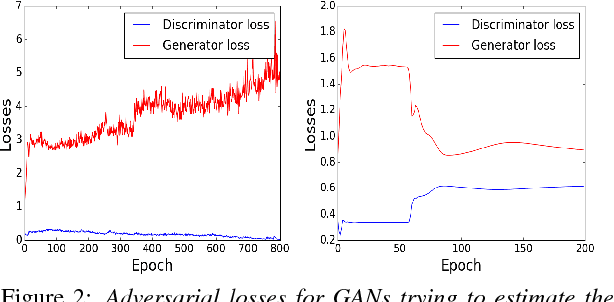
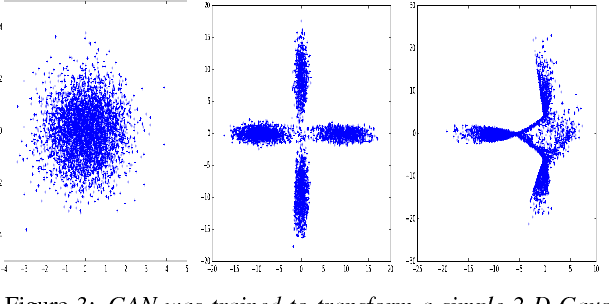

Generative Adversarial Networks (GANs) have gained a lot of attention from machine learning community due to their ability to learn and mimic an input data distribution. GANs consist of a discriminator and a generator working in tandem playing a min-max game to learn a target underlying data distribution; when fed with data-points sampled from a simpler distribution (like uniform or Gaussian distribution). Once trained, they allow synthetic generation of examples sampled from the target distribution. We investigate the application of GANs to generate synthetic feature vectors used for speech emotion recognition. Specifically, we investigate two set ups: (i) a vanilla GAN that learns the distribution of a lower dimensional representation of the actual higher dimensional feature vector and, (ii) a conditional GAN that learns the distribution of the higher dimensional feature vectors conditioned on the labels or the emotional class to which it belongs. As a potential practical application of these synthetically generated samples, we measure any improvement in a classifier's performance when the synthetic data is used along with real data for training. We perform cross-validation analyses followed by a cross-corpus study.
Semi-supervised and Transfer learning approaches for low resource sentiment classification
Jun 07, 2018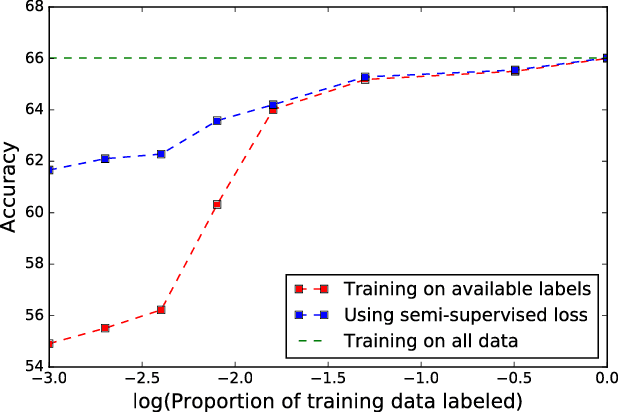
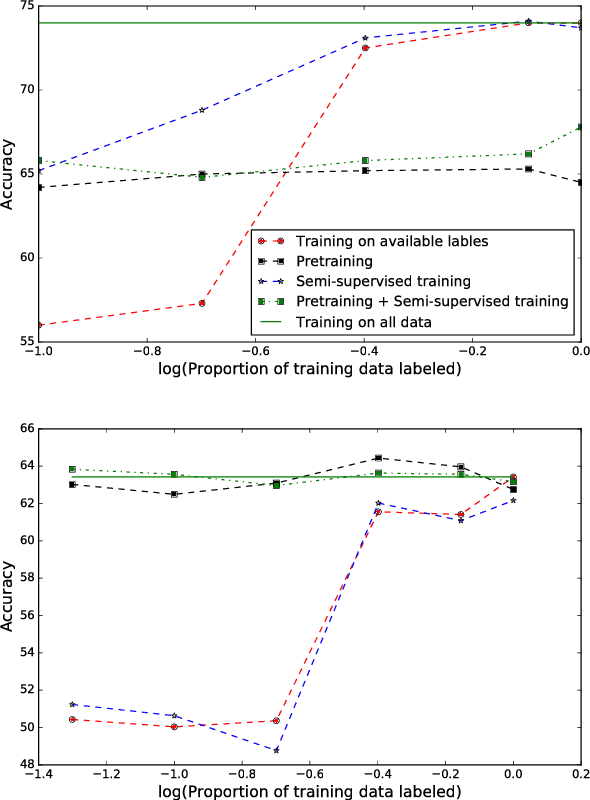
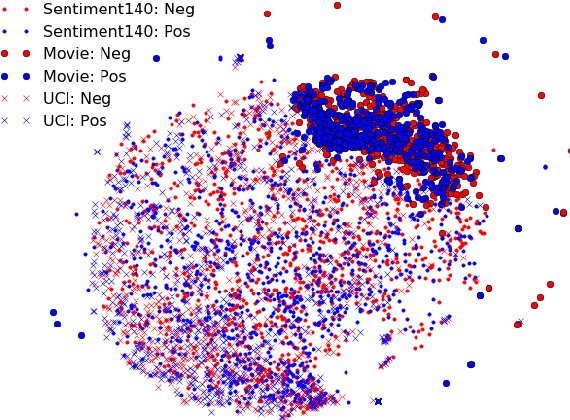
Sentiment classification involves quantifying the affective reaction of a human to a document, media item or an event. Although researchers have investigated several methods to reliably infer sentiment from lexical, speech and body language cues, training a model with a small set of labeled datasets is still a challenge. For instance, in expanding sentiment analysis to new languages and cultures, it may not always be possible to obtain comprehensive labeled datasets. In this paper, we investigate the application of semi-supervised and transfer learning methods to improve performances on low resource sentiment classification tasks. We experiment with extracting dense feature representations, pre-training and manifold regularization in enhancing the performance of sentiment classification systems. Our goal is a coherent implementation of these methods and we evaluate the gains achieved by these methods in matched setting involving training and testing on a single corpus setting as well as two cross corpora settings. In both the cases, our experiments demonstrate that the proposed methods can significantly enhance the model performance against a purely supervised approach, particularly in cases involving a handful of training data.
Adversarial Auto-encoders for Speech Based Emotion Recognition
Jun 06, 2018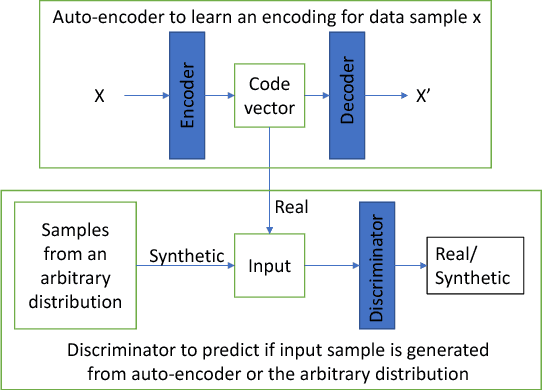

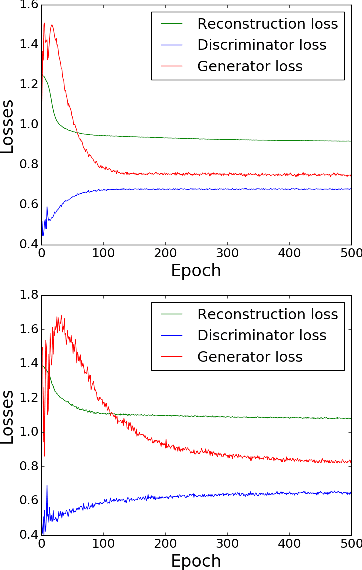
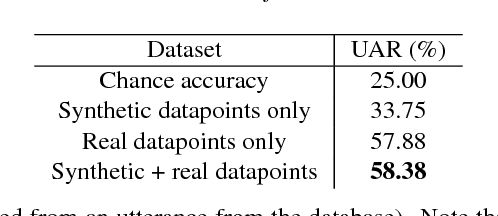
Recently, generative adversarial networks and adversarial autoencoders have gained a lot of attention in machine learning community due to their exceptional performance in tasks such as digit classification and face recognition. They map the autoencoder's bottleneck layer output (termed as code vectors) to different noise Probability Distribution Functions (PDFs), that can be further regularized to cluster based on class information. In addition, they also allow a generation of synthetic samples by sampling the code vectors from the mapped PDFs. Inspired by these properties, we investigate the application of adversarial autoencoders to the domain of emotion recognition. Specifically, we conduct experiments on the following two aspects: (i) their ability to encode high dimensional feature vector representations for emotional utterances into a compressed space (with a minimal loss of emotion class discriminability in the compressed space), and (ii) their ability to regenerate synthetic samples in the original feature space, to be later used for purposes such as training emotion recognition classifiers. We demonstrate the promise of adversarial autoencoders with regards to these aspects on the Interactive Emotional Dyadic Motion Capture (IEMOCAP) corpus and present our analysis.