 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Transformer for Video Understanding Using Gated Multi-Level Attention and Temporal Adversarial Training
Paper and Code
Mar 18, 2021
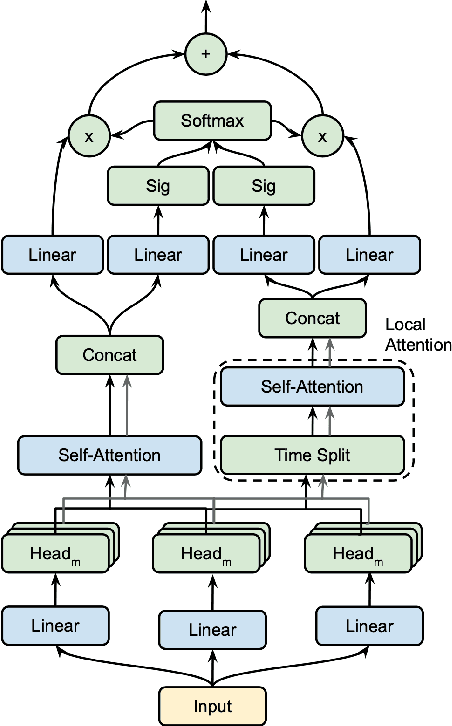


The introduction of Transformer model has led to tremendous advancements in sequence modeling, especially in text domain. However, the use of attention-based models for video understanding is still relatively unexplored. In this paper, we introduce Gated Adversarial Transformer (GAT) to enhance the applicability of attention-based models to videos. GAT uses a multi-level attention gate to model the relevance of a frame based on local and global contexts. This enables the model to understand the video at various granularities. Further, GAT uses adversarial training to improve model generalization. We propose temporal attention regularization scheme to improve the robustness of attention modules to adversarial examples. We illustrate the performance of GAT on the large-scale YoutTube-8M data set on the task of video categorization. We further show ablation studies along with quantitative and qualitative analysis to showcase the improvement.