 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-modal Learning for Multi-modal Video Categorization
Paper and Code
Mar 16, 2020
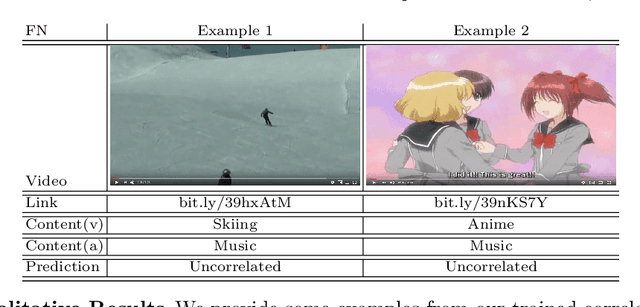
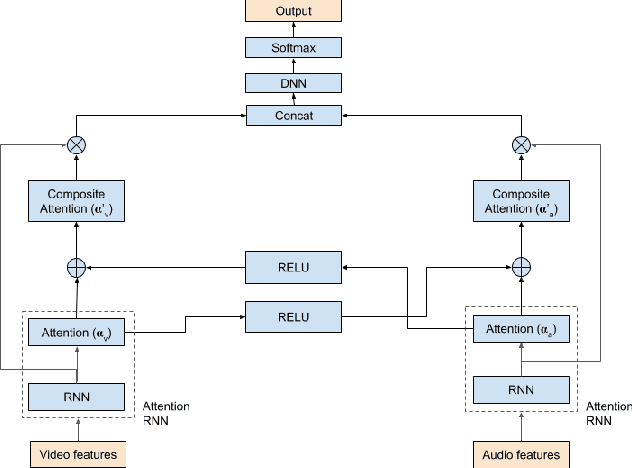
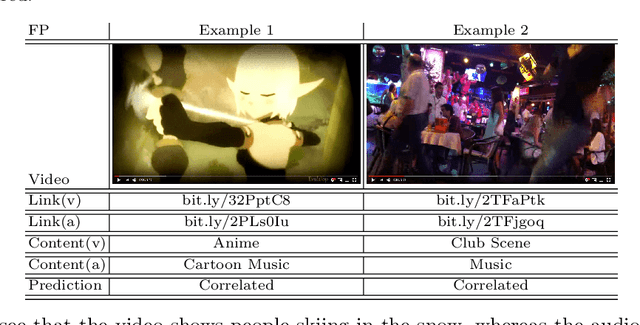
Multi-modal machine learning (ML) models can process data in multiple modalities (e.g., video, audio, text) and are useful for video content analysis in a variety of problems (e.g., object detection, scene understanding, activity recognition). In this paper, we focus on the problem of video categorization using a multi-modal ML technique. In particular, we have developed a novel multi-modal ML approach that we call "cross-modal learning", where one modality influences another but only when there is correlation between the modalities --- for that, we first train a correlation tower that guides the main multi-modal video categorization tower in the model. We show how this cross-modal principle can be applied to different types of models (e.g., RNN, Transformer, NetVLAD), and demonstrate through experiments how our proposed multi-modal video categorization models with cross-modal learning out-perform strong state-of-the-art baseline models.