 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan't Fool Me: Adversarially Robust Transformer for Video Understanding
Paper and Code
Oct 26, 2021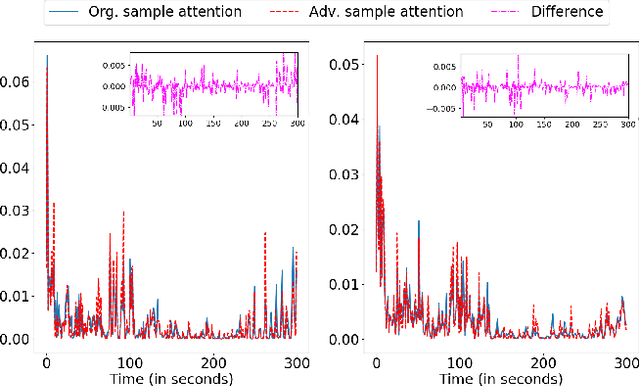
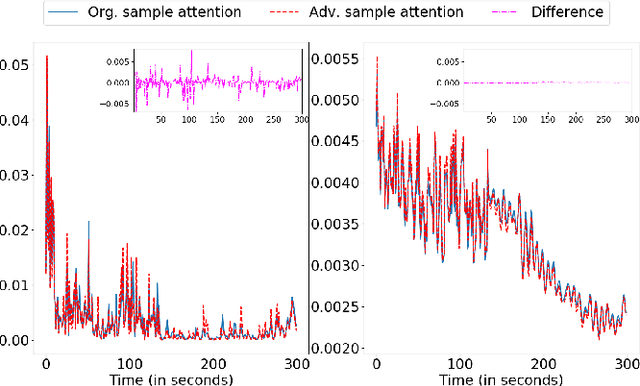


Deep neural networks have been shown to perform poorly on adversarial examples. To address this, several techniques have been proposed to increase robustness of a model for image classification tasks. However, in video understanding tasks, developing adversarially robust models is still unexplored. In this paper, we aim to bridge this gap. We first show that simple extensions of image based adversarially robust models slightly improve the worst-case performance. Further, we propose a temporal attention regularization scheme in Transformer to improve the robustness of attention modules to adversarial examples. We illustrate using a large-scale video data set YouTube-8M that the final model (A-ART) achieves close to non-adversarial performance on its adversarial example set. We achieve 91% GAP on adversarial examples, whereas baseline Transformer and simple adversarial extensions achieve 72.9% and 82% respectively, showing significant improvement in robustness over the state-of-the-art.