 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotivating Learners in Multi-Orchestrator Mobile Edge Learning: A Stackelberg Game Approach
Sep 25, 2021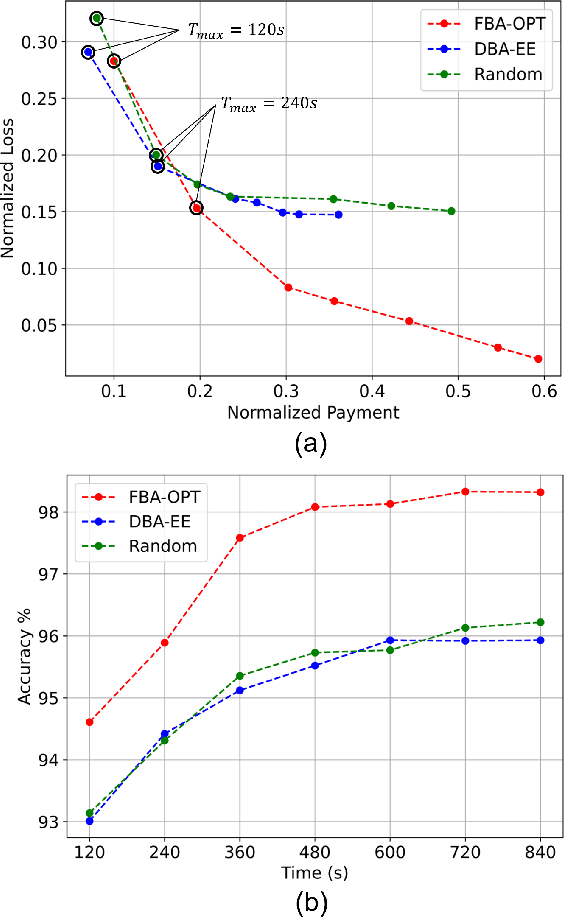
Mobile Edge Learning (MEL) is a learning paradigm that enables distributed training of Machine Learning models over heterogeneous edge devices (e.g., IoT devices). Multi-orchestrator MEL refers to the coexistence of multiple learning tasks with different datasets, each of which being governed by an orchestrator to facilitate the distributed training process. In MEL, the training performance deteriorates without the availability of sufficient training data or computing resources. Therefore, it is crucial to motivate edge devices to become learners and offer their computing resources, and either offer their private data or receive the needed data from the orchestrator and participate in the training process of a learning task. In this work, we propose an incentive mechanism, where we formulate the orchestrators-learners interactions as a 2-round Stackelberg game to motivate the participation of the learners. In the first round, the learners decide which learning task to get engaged in, and then in the second round, the amount of data for training in case of participation such that their utility is maximized. We then study the game analytically and derive the learners' optimal strategy. Finally, numerical experiments have been conducted to evaluate the performance of the proposed incentive mechanism.
Energy-Efficient Multi-Orchestrator Mobile Edge Learning
Sep 02, 2021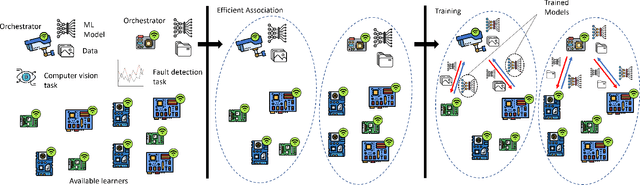
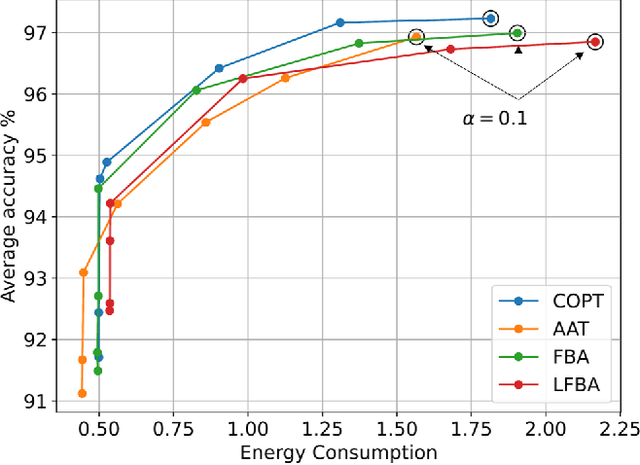
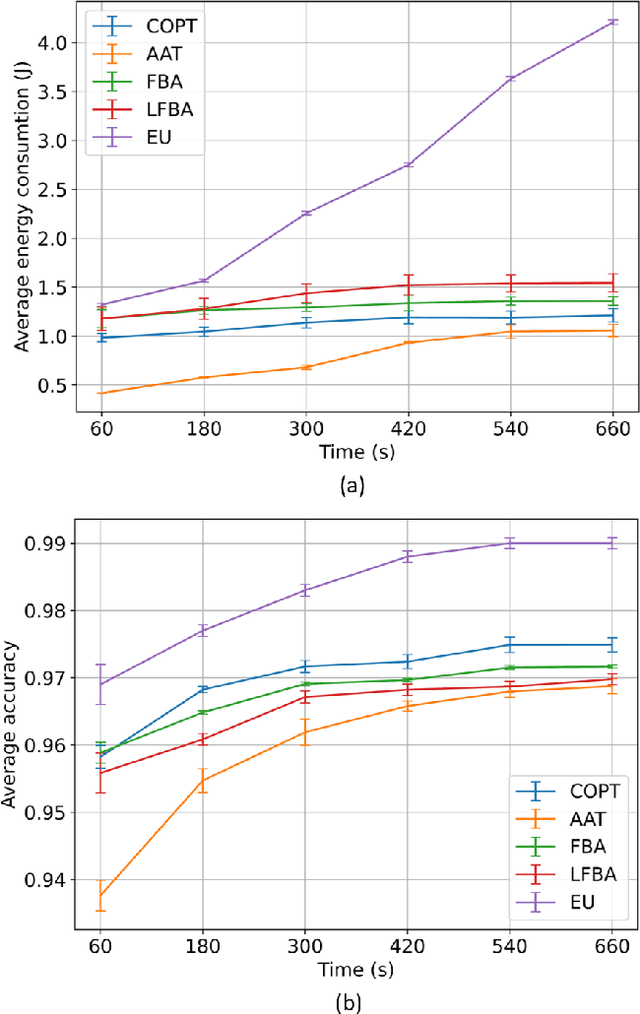
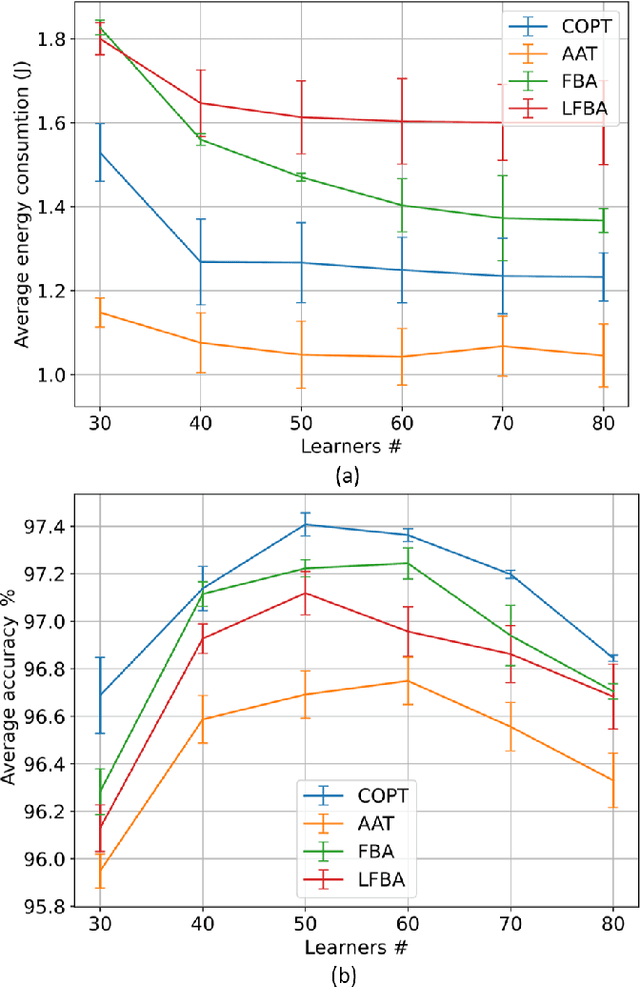
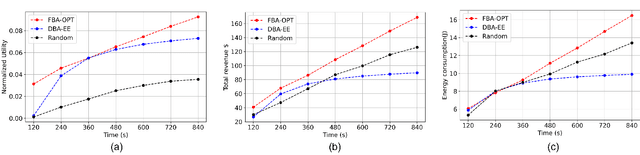
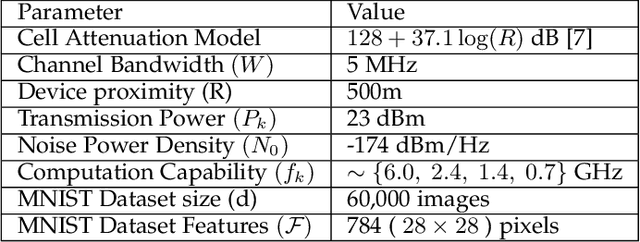
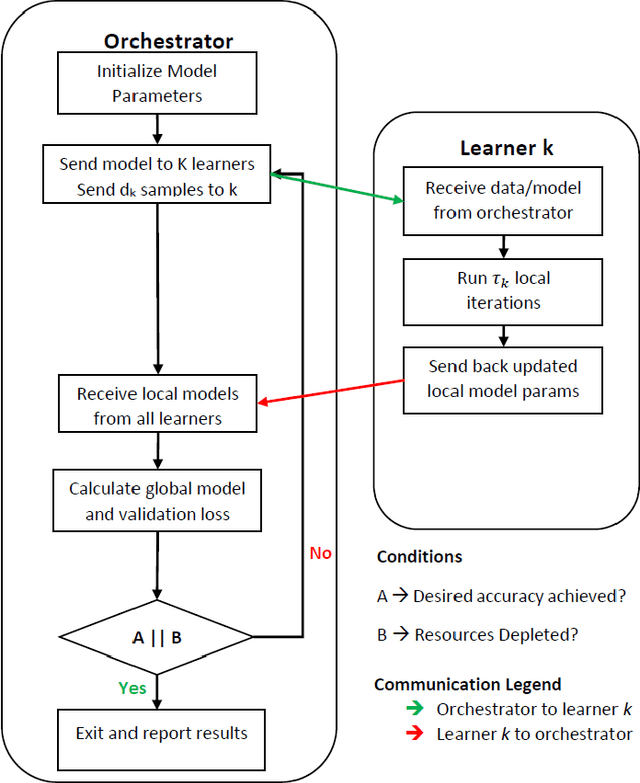
Mobile Edge Learning (MEL) is a collaborative learning paradigm that features distributed training of Machine Learning (ML) models over edge devices (e.g., IoT devices). In MEL, possible coexistence of multiple learning tasks with different datasets may arise. The heterogeneity in edge devices' capabilities will require the joint optimization of the learners-orchestrator association and task allocation. To this end, we aim to develop an energy-efficient framework for learners-orchestrator association and learning task allocation, in which each orchestrator gets associated with a group of learners with the same learning task based on their communication channel qualities and computational resources, and allocate the tasks accordingly. Therein, a multi objective optimization problem is formulated to minimize the total energy consumption and maximize the learning tasks' accuracy. However, solving such optimization problem requires centralization and the presence of the whole environment information at a single entity, which becomes impractical in large-scale systems. To reduce the solution complexity and to enable solution decentralization, we propose lightweight heuristic algorithms that can achieve near-optimal performance and facilitate the trade-offs between energy consumption, accuracy, and solution complexity. Simulation results show that the proposed approaches reduce the energy consumption significantly while executing multiple learning tasks compared to recent state-of-the-art methods.
Task Allocation for Asynchronous Mobile Edge Learning with Delay and Energy Constraints
Dec 04, 2020
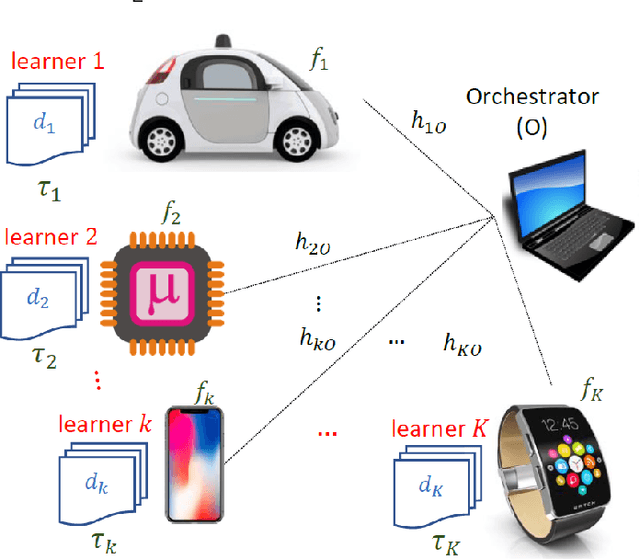
This paper extends the paradigm of "mobile edge learning (MEL)" by designing an optimal task allocation scheme for training a machine learning model in an asynchronous manner across mutiple edge nodes or learners connected via a resource-constrained wireless edge network. The optimization is done such that the portion of the task allotted to each learner is completed within a given global delay constraint and a local maximum energy consumption limit. The time and energy consumed are related directly to the heterogeneous communication and computational capabilities of the learners; i.e. the proposed model is heterogeneity aware (HA). Because the resulting optimization is an NP-hard quadratically-constrained integer linear program (QCILP), a two-step suggest-and-improve (SAI) solution is proposed based on using the solution of the relaxed synchronous problem to obtain the solution to the asynchronous problem. The proposed HA asynchronous (HA-Asyn) approach is compared against the HA synchronous (HA-Sync) scheme and the heterogeneity unaware (HU) equal batch allocation scheme. Results from a system of 20 learners tested for various completion time and energy consumption constraints show that the proposed HA-Asyn method works better than the HU synchronous/asynchronous (HU-Sync/Asyn) approach and can provide gains of up-to 25\% compared to the HA-Sync scheme.
Optimal Task Allocation for Mobile Edge Learning with Global Training Time Constraints
Jul 04, 2020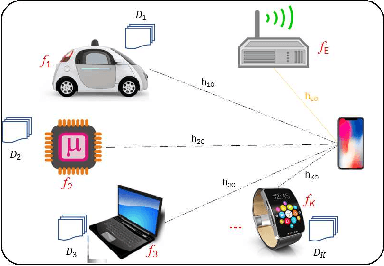
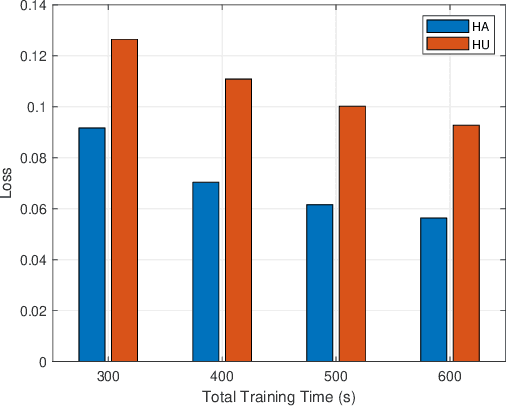
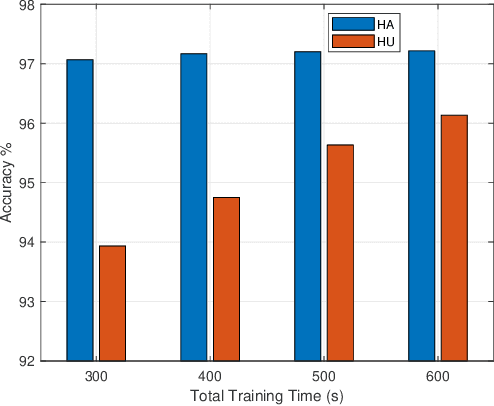
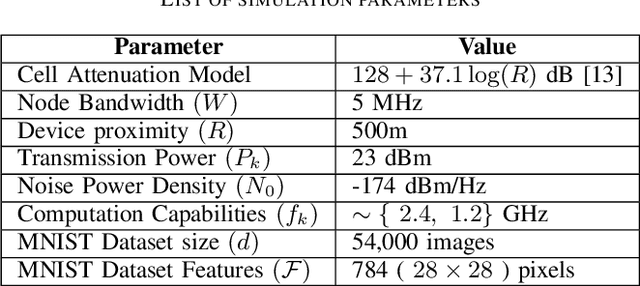
This paper proposes to minimize the loss of training a distributed machine learning (ML) model on nodes or learners connected via the resource-constrained wireless edge network by jointly optimizing the number of local and global updates and the task size allocation. The optimization is done while taking into account heterogeneous communication and computation capabilities of each learner. It is shown that the problem of interest cannot be solved analytically but by leveraging existing bounds on the difference between the optimal loss and the loss at any given iteration, an expression for the objective function is derived as a function of the number of local updates. It is shown that the problem is convex and can be solved by finding the argument that minimizes the loss. The result is then used to determine the batch sizes for each learner for the next global update step. The merits of the proposed solution, which is heterogeneity aware (HA), are exhibited by comparing its performance to the heterogeneity unaware (HU) approach.
Adaptive Task Allocation for Asynchronous Federated Mobile Edge Learning
May 05, 2019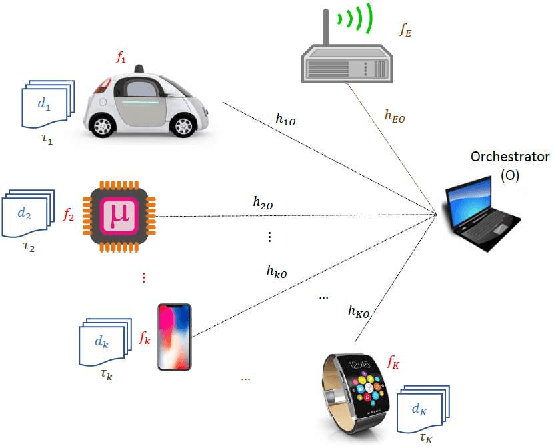

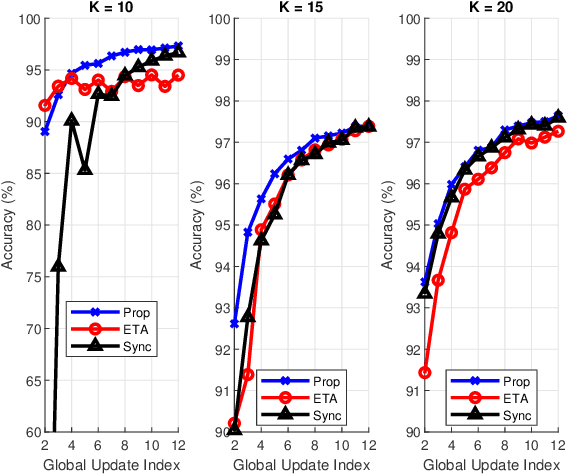
This paper proposes a scheme to efficiently execute distributed learning tasks in an asynchronous manner while minimizing the gradient staleness on wireless edge nodes with heterogeneous computing and communication capacities. The designed approach considered in this paper ensures that all devices work for a certain duration that covers the time for data/model distribution, learning iterations, model collection and global aggregation. The resulting problem is an integer non-convex program with quadratic equality constraints as well as linear equality and inequality constraints. Because the problem is NP-hard, we relax the integer constraints in order to solve it efficiently with available solvers. Analytical bounds are derived using the KKT conditions and Lagrangian analysis in conjunction with the suggest-and-improve approach. Results show that our approach reduces the gradient staleness and can offer better accuracy than the synchronous scheme and the asynchronous scheme with equal task allocation.
Adaptive Task Allocation for Mobile Edge Learning
Nov 09, 2018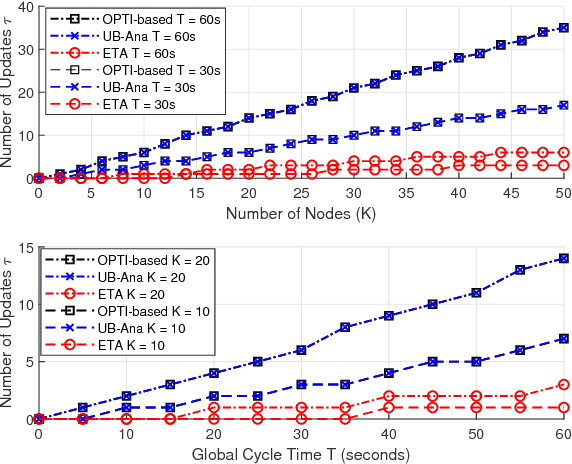
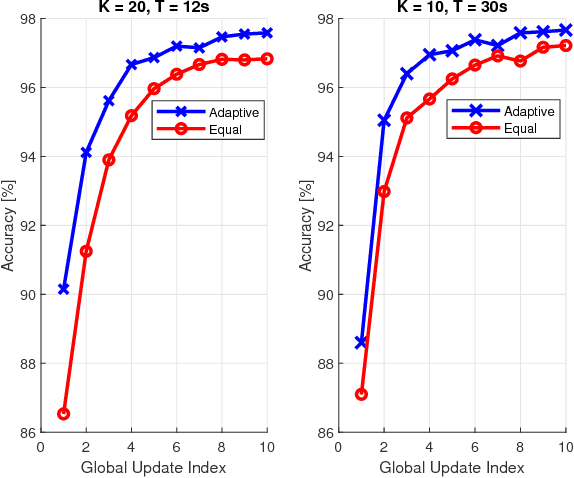
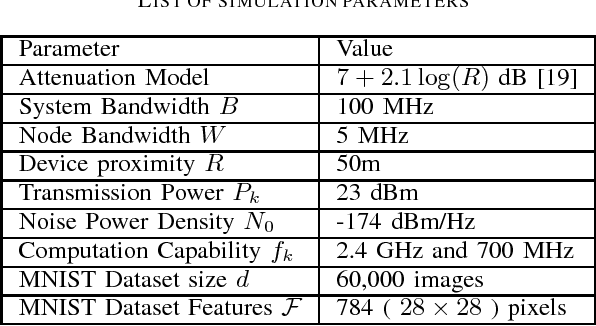
This paper aims to establish a new optimization paradigm for implementing realistic distributed learning algorithms, with performance guarantees, on wireless edge nodes with heterogeneous computing and communication capacities. We will refer to this new paradigm as "Mobile Edge Learning (MEL)". The problem of dynamic task allocation for MEL is considered in this paper with the aim to maximize the learning accuracy, while guaranteeing that the total times of data distribution/aggregation over heterogeneous channels, and local computing iterations at the heterogeneous nodes, are bounded by a preset duration. The problem is first formulated as a quadratically-constrained integer linear problem. Being an NP-hard problem, the paper relaxes it into a non-convex problem over real variables. We thus proposed two solutions based on deriving analytical upper bounds of the optimal solution of this relaxed problem using Lagrangian analysis and KKT conditions, and the use of suggest-and-improve starting from equal batch allocation, respectively. The merits of these proposed solutions are exhibited by comparing their performances to both numerical approaches and the equal task allocation approach.
Deep Learning for IoT Big Data and Streaming Analytics: A Survey
Jun 05, 2018

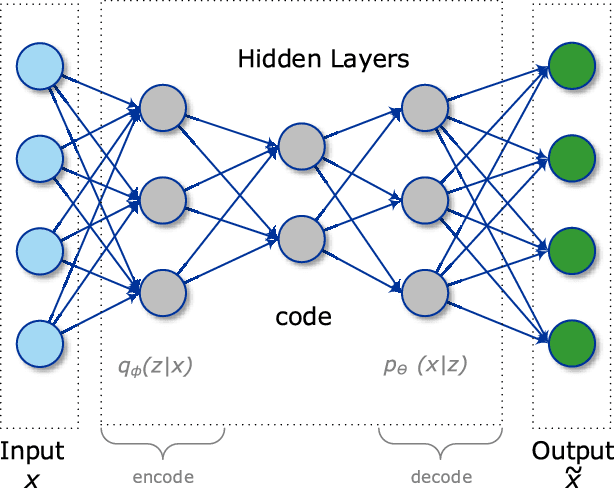

In the era of the Internet of Things (IoT), an enormous amount of sensing devices collect and/or generate various sensory data over time for a wide range of fields and applications. Based on the nature of the application, these devices will result in big or fast/real-time data streams. Applying analytics over such data streams to discover new information, predict future insights, and make control decisions is a crucial process that makes IoT a worthy paradigm for businesses and a quality-of-life improving technology. In this paper, we provide a thorough overview on using a class of advanced machine learning techniques, namely Deep Learning (DL), to facilitate the analytics and learning in the IoT domain. We start by articulating IoT data characteristics and identifying two major treatments for IoT data from a machine learning perspective, namely IoT big data analytics and IoT streaming data analytics. We also discuss why DL is a promising approach to achieve the desired analytics in these types of data and applications. The potential of using emerging DL techniques for IoT data analytics are then discussed, and its promises and challenges are introduced. We present a comprehensive background on different DL architectures and algorithms. We also analyze and summarize major reported research attempts that leveraged DL in the IoT domain. The smart IoT devices that have incorporated DL in their intelligence background are also discussed. DL implementation approaches on the fog and cloud centers in support of IoT applications are also surveyed. Finally, we shed light on some challenges and potential directions for future research. At the end of each section, we highlight the lessons learned based on our experiments and review of the recent literature.
VANETs Meet Autonomous Vehicles: A Multimodal 3D Environment Learning Approach
May 24, 2017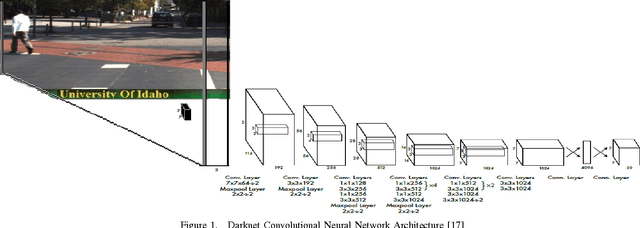
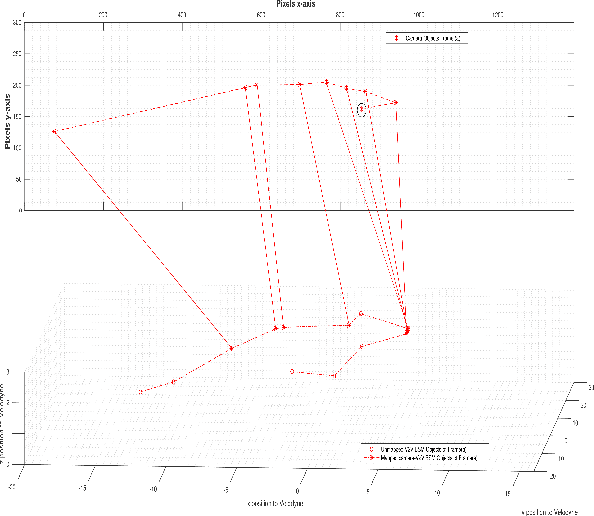
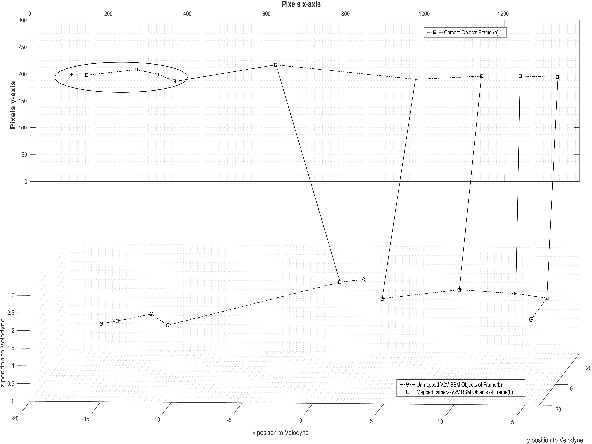
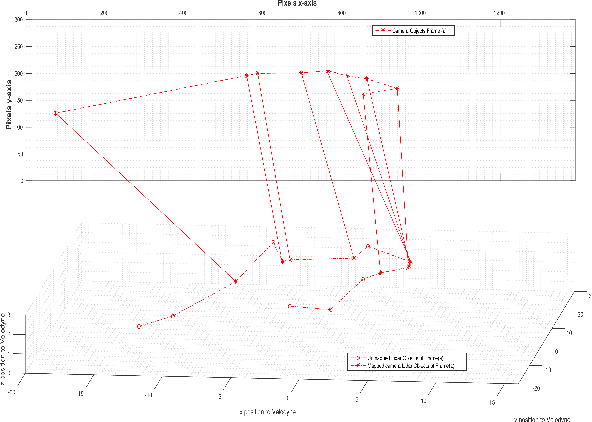
In this paper, we design a multimodal framework for object detection, recognition and mapping based on the fusion of stereo camera frames, point cloud Velodyne Lidar scans, and Vehicle-to-Vehicle (V2V) Basic Safety Messages (BSMs) exchanged using Dedicated Short Range Communication (DSRC). We merge the key features of rich texture descriptions of objects from 2D images, depth and distance between objects provided by 3D point cloud and awareness of hidden vehicles from BSMs' 3D information. We present a joint pixel to point cloud and pixel to V2V correspondences of objects in frames from the Kitti Vision Benchmark Suite by using a semi-supervised manifold alignment approach to achieve camera-Lidar and camera-V2V mapping of their recognized objects that have the same underlying manifold.
Joint Indoor Localization and Radio Map Construction with Limited Deployment Load
Oct 12, 2013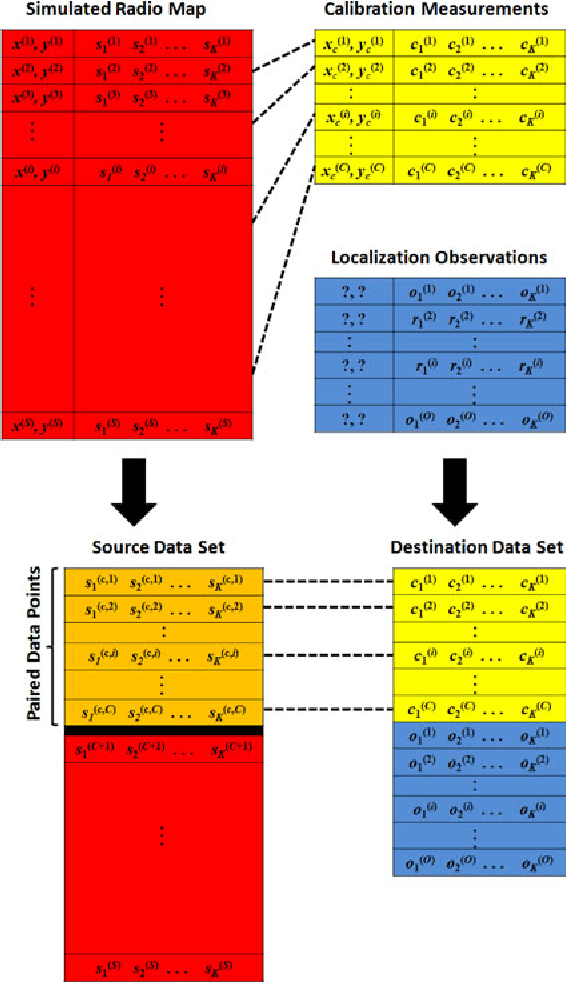
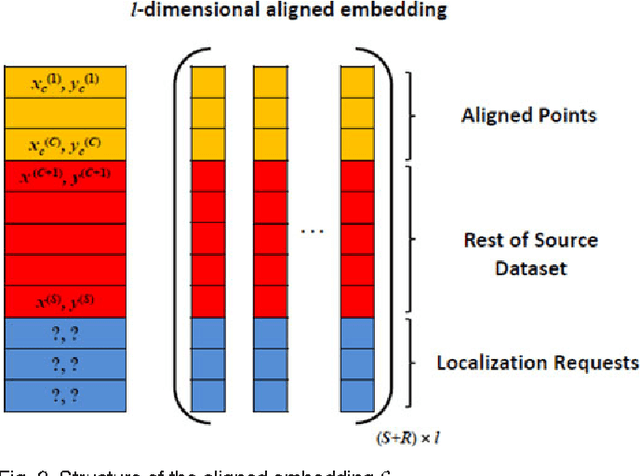
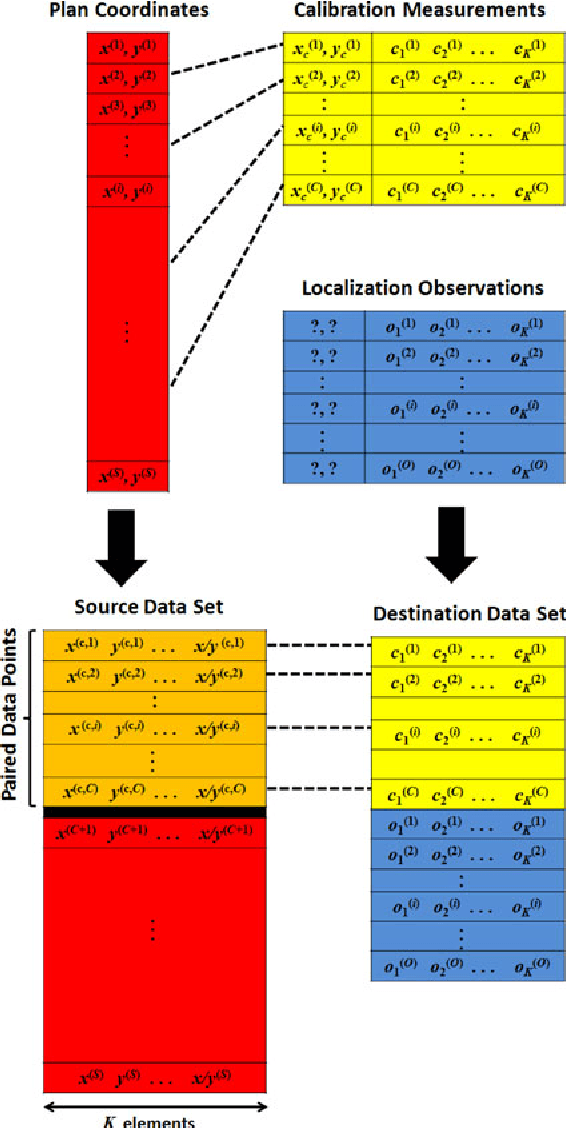

One major bottleneck in the practical implementation of received signal strength (RSS) based indoor localization systems is the extensive deployment efforts required to construct the radio maps through fingerprinting. In this paper, we aim to design an indoor localization scheme that can be directly employed without building a full fingerprinted radio map of the indoor environment. By accumulating the information of localized RSSs, this scheme can also simultaneously construct the radio map with limited calibration. To design this scheme, we employ a source data set that possesses the same spatial correlation of the RSSs in the indoor environment under study. The knowledge of this data set is then transferred to a limited number of calibration fingerprints and one or several RSS observations with unknown locations, in order to perform direct localization of these observations using manifold alignment. We test two different source data sets, namely a simulated radio propagation map and the environments plan coordinates. For moving users, we exploit the correlation of their observations to improve the localization accuracy. The online testing in two indoor environments shows that the plan coordinates achieve better results than the simulated radio maps, and a negligible degradation with 70-85% reduction in calibration load.