 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Deep Reinforcement Learning in Support of IoT and Smart City Services
Oct 09, 2018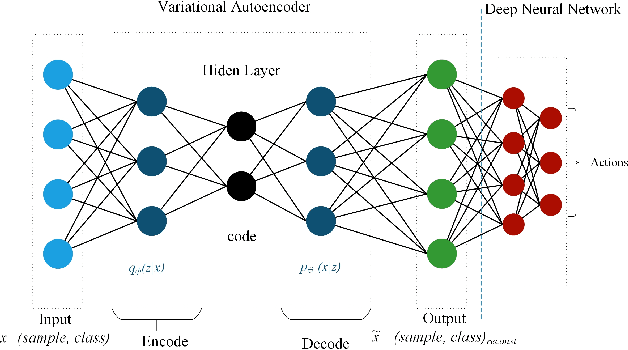
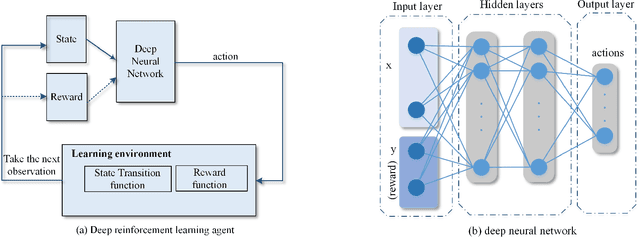
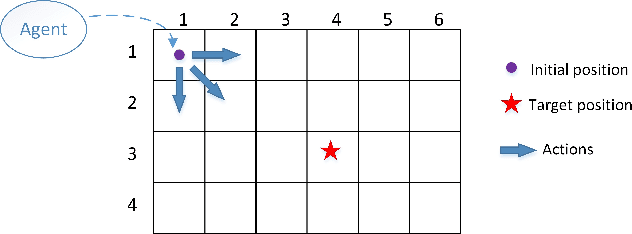
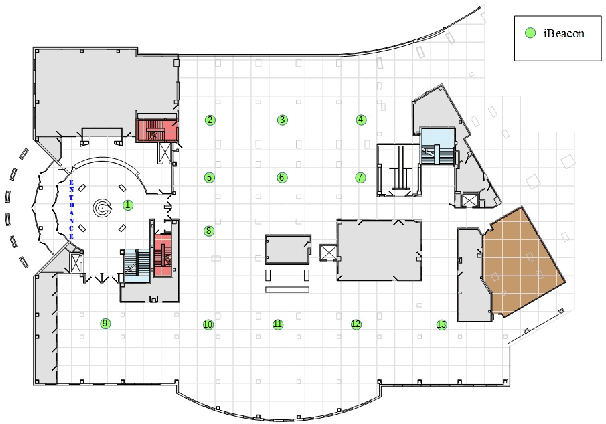
Smart services are an important element of the smart cities and the Internet of Things (IoT) ecosystems where the intelligence behind the services is obtained and improved through the sensory data. Providing a large amount of training data is not always feasible; therefore, we need to consider alternative ways that incorporate unlabeled data as well. In recent years, Deep reinforcement learning (DRL) has gained great success in several application domains. It is an applicable method for IoT and smart city scenarios where auto-generated data can be partially labeled by users' feedback for training purposes. In this paper, we propose a semi-supervised deep reinforcement learning model that fits smart city applications as it consumes both labeled and unlabeled data to improve the performance and accuracy of the learning agent. The model utilizes Variational Autoencoders (VAE) as the inference engine for generalizing optimal policies. To the best of our knowledge, the proposed model is the first investigation that extends deep reinforcement learning to the semi-supervised paradigm. As a case study of smart city applications, we focus on smart buildings and apply the proposed model to the problem of indoor localization based on BLE signal strength. Indoor localization is the main component of smart city services since people spend significant time in indoor environments. Our model learns the best action policies that lead to a close estimation of the target locations with an improvement of 23% in terms of distance to the target and at least 67% more received rewards compared to the supervised DRL model.
* 11 pages, 7 figures. Accepted for publication in IEEE Internet of Things Journal
Enabling Cognitive Smart Cities Using Big Data and Machine Learning: Approaches and Challenges
Oct 09, 2018



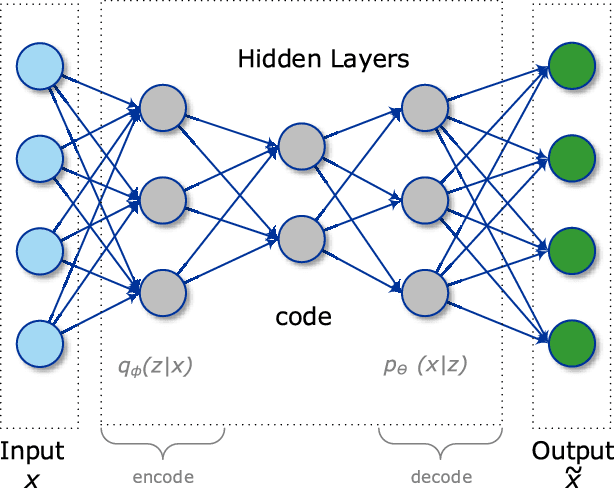
The development of smart cities and their fast-paced deployment is resulting in the generation of large quantities of data at unprecedented rates. Unfortunately, most of the generated data is wasted without extracting potentially useful information and knowledge because of the lack of established mechanisms and standards that benefit from the availability of such data. Moreover, the high dynamical nature of smart cities calls for new generation of machine learning approaches that are flexible and adaptable to cope with the dynamicity of data to perform analytics and learn from real-time data. In this article, we shed the light on the challenge of under utilizing the big data generated by smart cities from a machine learning perspective. Especially, we present the phenomenon of wasting unlabeled data. We argue that semi-supervision is a must for smart city to address this challenge. We also propose a three-level learning framework for smart cities that matches the hierarchical nature of big data generated by smart cities with a goal of providing different levels of knowledge abstractions. The proposed framework is scalable to meet the needs of smart city services. Fundamentally, the framework benefits from semi-supervised deep reinforcement learning where a small amount of data that has users' feedback serves as labeled data while a larger amount is without such users' feedback serves as unlabeled data. This paper also explores how deep reinforcement learning and its shift toward semi-supervision can handle the cognitive side of smart city services and improve their performance by providing several use cases spanning the different domains of smart cities. We also highlight several challenges as well as promising future research directions for incorporating machine learning and high-level intelligence into smart city services.
* 7 pages, 5 figures and 1 table. Final version is published in IEEE Communications Magazine
Deep Learning for IoT Big Data and Streaming Analytics: A Survey
Jun 05, 2018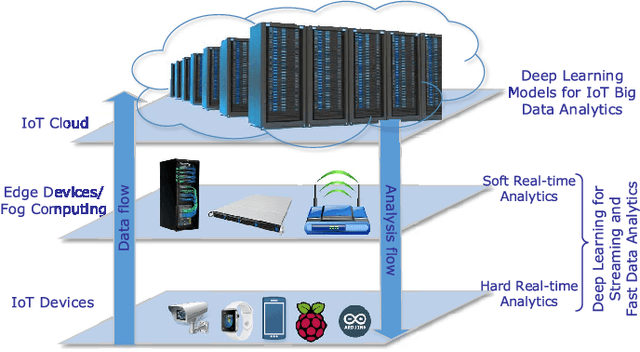


In the era of the Internet of Things (IoT), an enormous amount of sensing devices collect and/or generate various sensory data over time for a wide range of fields and applications. Based on the nature of the application, these devices will result in big or fast/real-time data streams. Applying analytics over such data streams to discover new information, predict future insights, and make control decisions is a crucial process that makes IoT a worthy paradigm for businesses and a quality-of-life improving technology. In this paper, we provide a thorough overview on using a class of advanced machine learning techniques, namely Deep Learning (DL), to facilitate the analytics and learning in the IoT domain. We start by articulating IoT data characteristics and identifying two major treatments for IoT data from a machine learning perspective, namely IoT big data analytics and IoT streaming data analytics. We also discuss why DL is a promising approach to achieve the desired analytics in these types of data and applications. The potential of using emerging DL techniques for IoT data analytics are then discussed, and its promises and challenges are introduced. We present a comprehensive background on different DL architectures and algorithms. We also analyze and summarize major reported research attempts that leveraged DL in the IoT domain. The smart IoT devices that have incorporated DL in their intelligence background are also discussed. DL implementation approaches on the fog and cloud centers in support of IoT applications are also surveyed. Finally, we shed light on some challenges and potential directions for future research. At the end of each section, we highlight the lessons learned based on our experiments and review of the recent literature.
Path Planning in Support of Smart Mobility Applications using Generative Adversarial Networks
Apr 23, 2018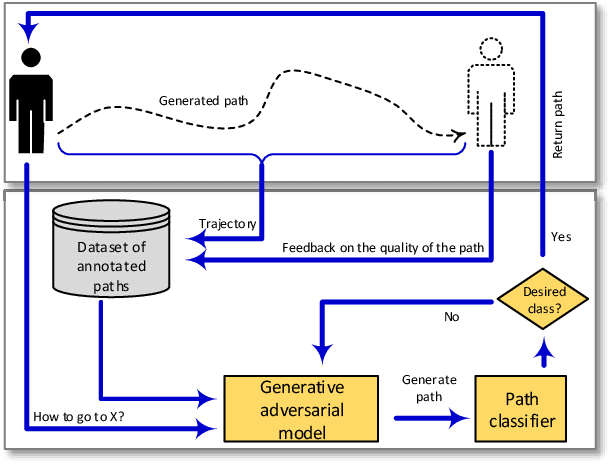
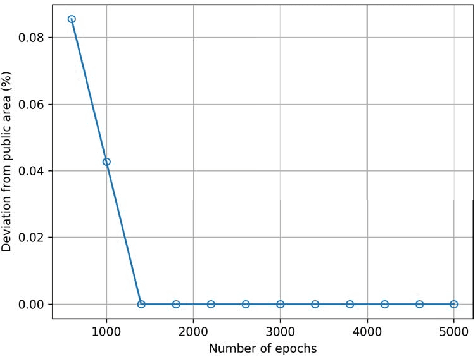
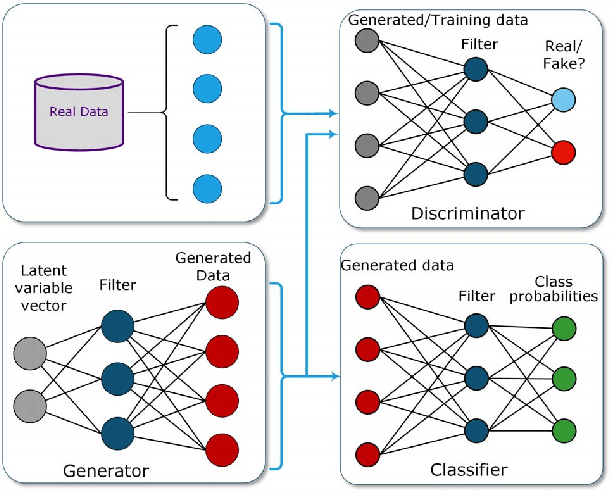
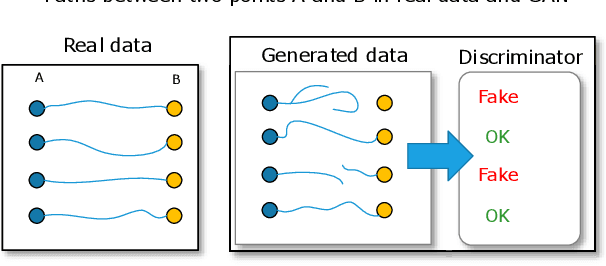
This paper describes and evaluates the use of Generative Adversarial Networks (GANs) for path planning in support of smart mobility applications such as indoor and outdoor navigation applications, individualized wayfinding for people with disabilities (e.g., vision impairments, physical disabilities, etc.), path planning for evacuations, robotic navigations, and path planning for autonomous vehicles. We propose an architecture based on GANs to recommend accurate and reliable paths for navigation applications. The proposed system can use crowd-sourced data to learn the trajectories and infer new ones. The system provides users with generated paths that help them navigate from their local environment to reach a desired location. As a use case, we experimented with the proposed method in support of a wayfinding application in an indoor environment. Our experiments assert that the generated paths are correct and reliable. The accuracy of the classification task for the generated paths is up to 99% and the quality of the generated paths has a mean opinion score of 89%.