 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Task Allocation for Mobile Edge Learning with Global Training Time Constraints
Paper and Code
Jul 04, 2020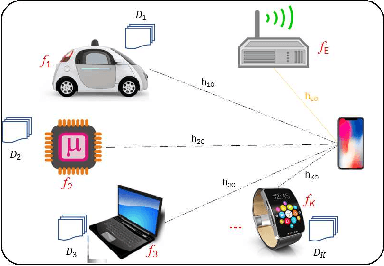
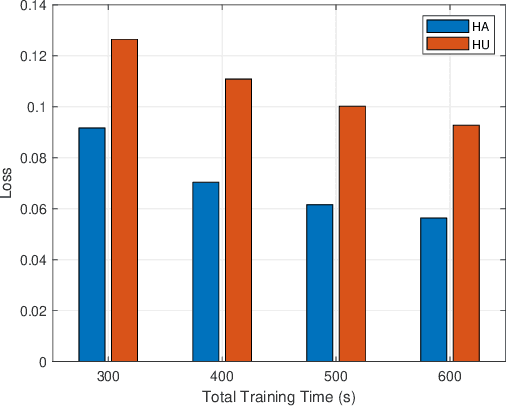
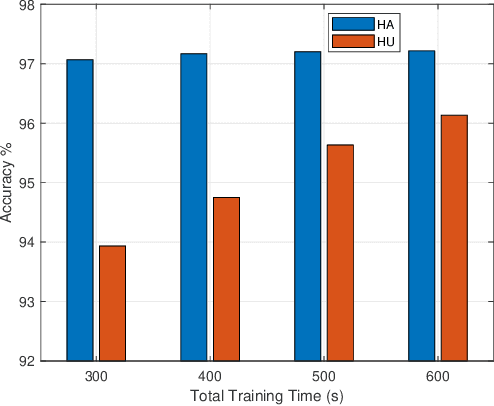
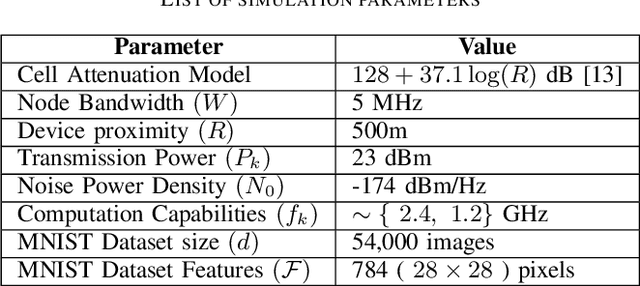
This paper proposes to minimize the loss of training a distributed machine learning (ML) model on nodes or learners connected via the resource-constrained wireless edge network by jointly optimizing the number of local and global updates and the task size allocation. The optimization is done while taking into account heterogeneous communication and computation capabilities of each learner. It is shown that the problem of interest cannot be solved analytically but by leveraging existing bounds on the difference between the optimal loss and the loss at any given iteration, an expression for the objective function is derived as a function of the number of local updates. It is shown that the problem is convex and can be solved by finding the argument that minimizes the loss. The result is then used to determine the batch sizes for each learner for the next global update step. The merits of the proposed solution, which is heterogeneity aware (HA), are exhibited by comparing its performance to the heterogeneity unaware (HU) approach.