 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegration of Vehicular Clouds and Autonomous Driving: Survey and Future Perspectives
Jan 15, 2022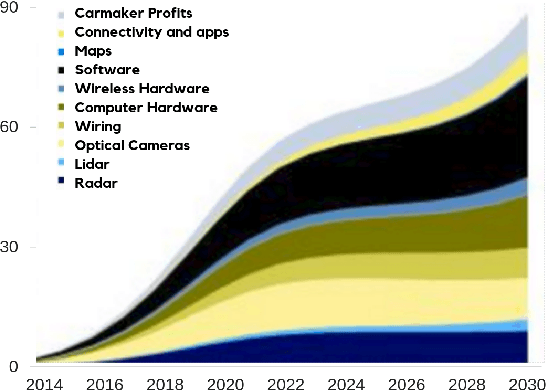
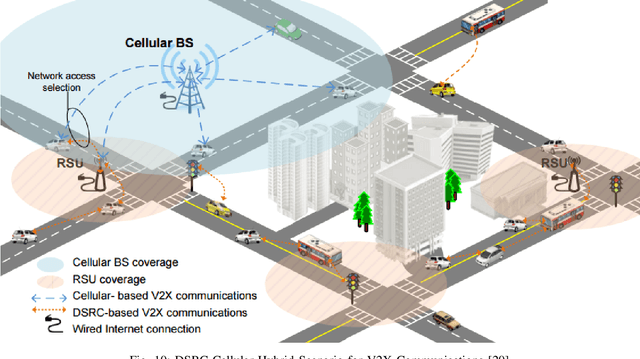
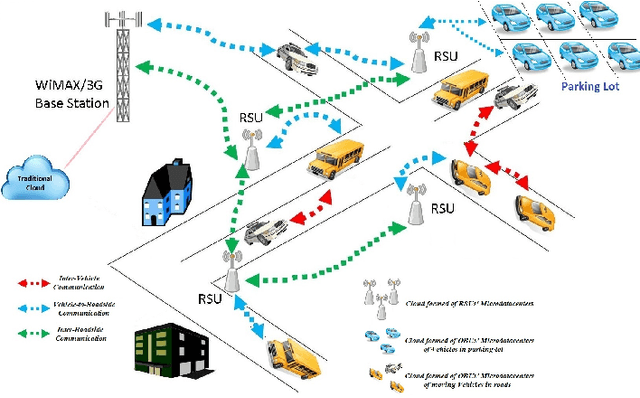
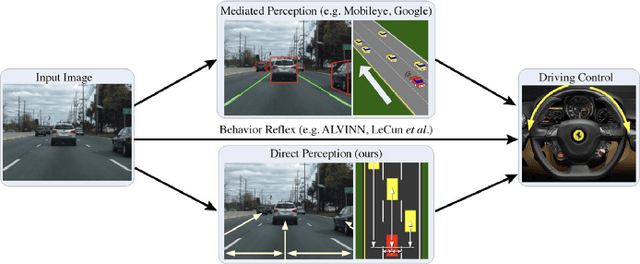
For decades, researchers on Vehicular Ad-hoc Networks (VANETs) and autonomous vehicles presented various solutions for vehicular safety and autonomy, respectively. Yet, the developed work in these two areas has been mostly conducted in their own separate worlds, and barely affect one-another despite the obvious relationships. In the coming years, the Internet of Vehicles (IoV), encompassing sensing, communications, connectivity, processing, networking, and computation is expected to bridge many technologies to offer value-added information for the navigation of self-driving vehicles, to reduce vehicle on board computation, and to deliver desired functionalities. Potentials for bridging the gap between these two worlds and creating synergies of these two technologies have recently started to attract significant attention of many companies and government agencies. In this article, we first present a comprehensive survey and an overview of the emerging key challenges related to the two worlds of Vehicular Clouds (VCs) including communications, networking, traffic modelling, medium access, VC Computing (VCC), VC collation strategies, security issues, and autonomous driving (AD) including 3D environment learning approaches and AD enabling deep-learning, computer vision and Artificial Intelligence (AI) techniques. We then discuss the recent related work and potential trends on merging these two worlds in order to enrich vehicle cognition of its surroundings, and enable safer and more informed and coordinated AD systems. Compared to other survey papers, this work offers more detailed summaries of the most relevant VCs and ADs systems in the literature, along with some key challenges and insights on how different technologies fit together to deliver safety, autonomy and infotainment services.
VANETs Meet Autonomous Vehicles: A Multimodal 3D Environment Learning Approach
May 24, 2017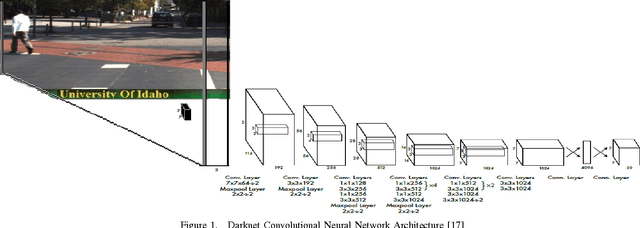
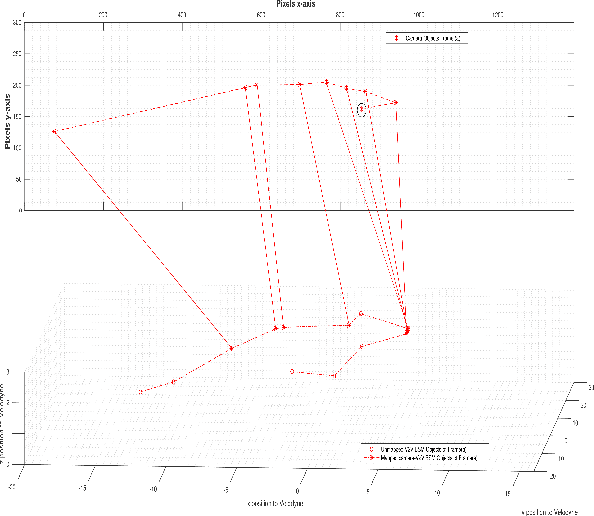
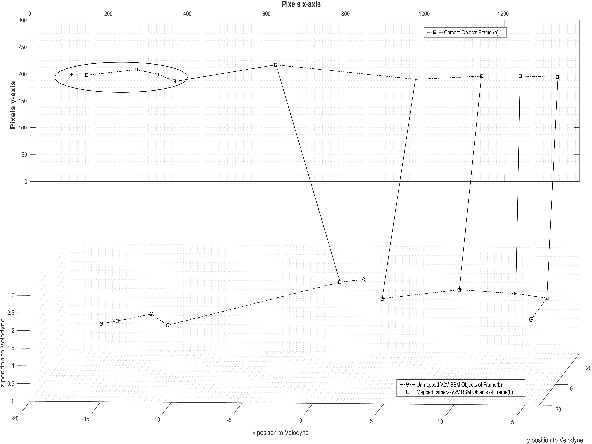
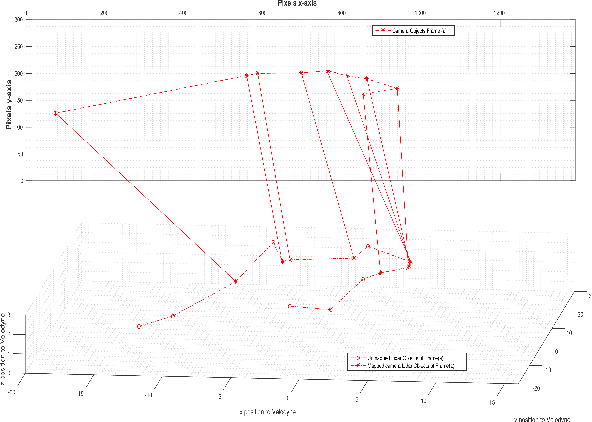
In this paper, we design a multimodal framework for object detection, recognition and mapping based on the fusion of stereo camera frames, point cloud Velodyne Lidar scans, and Vehicle-to-Vehicle (V2V) Basic Safety Messages (BSMs) exchanged using Dedicated Short Range Communication (DSRC). We merge the key features of rich texture descriptions of objects from 2D images, depth and distance between objects provided by 3D point cloud and awareness of hidden vehicles from BSMs' 3D information. We present a joint pixel to point cloud and pixel to V2V correspondences of objects in frames from the Kitti Vision Benchmark Suite by using a semi-supervised manifold alignment approach to achieve camera-Lidar and camera-V2V mapping of their recognized objects that have the same underlying manifold.