 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Auto-bidding based on Traffic Prediction in Live Advertising
Aug 08, 2025Internet live streaming is widely used in online entertainment and e-commerce, where live advertising is an important marketing tool for anchors. An advertising campaign hopes to maximize the effect (such as conversions) under constraints (such as budget and cost-per-click). The mainstream control of campaigns is auto-bidding, where the performance depends on the decision of the bidding algorithm in each request. The most widely used auto-bidding algorithms include Proportional-Integral-Derivative (PID) control, linear programming (LP), reinforcement learning (RL), etc. Existing methods either do not consider the entire time traffic, or have too high computational complexity. In this paper, the live advertising has high requirements for real-time bidding (second-level control) and faces the difficulty of unknown future traffic. Therefore, we propose a lightweight bidding algorithm Binary Constrained Bidding (BiCB), which neatly combines the optimal bidding formula given by mathematical analysis and the statistical method of future traffic estimation, and obtains good approximation to the optimal result through a low complexity solution. In addition, we complement the form of upper and lower bound constraints for traditional auto-bidding modeling and give theoretical analysis of BiCB. Sufficient offline and online experiments prove BiCB's good performance and low engineering cost.
GA-SAM: Gradient-Strength based Adaptive Sharpness-Aware Minimization for Improved Generalization
Oct 13, 2022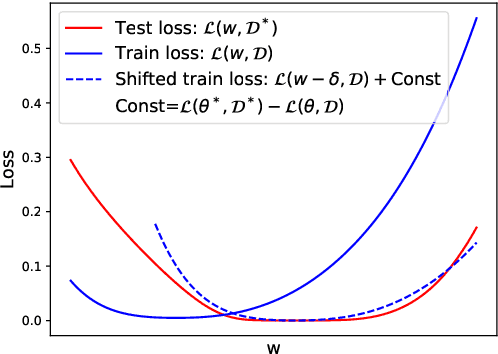
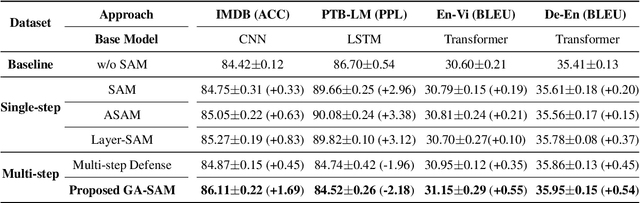
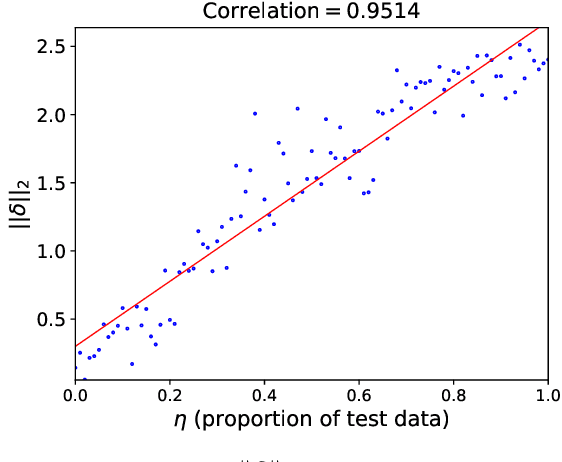

Recently, Sharpness-Aware Minimization (SAM) algorithm has shown state-of-the-art generalization abilities in vision tasks. It demonstrates that flat minima tend to imply better generalization abilities. However, it has some difficulty implying SAM to some natural language tasks, especially to models with drastic gradient changes, such as RNNs. In this work, we analyze the relation between the flatness of the local minimum and its generalization ability from a novel and straightforward theoretical perspective. We propose that the shift of the training and test distributions can be equivalently seen as a virtual parameter corruption or perturbation, which can explain why flat minima that are robust against parameter corruptions or perturbations have better generalization performances. On its basis, we propose a Gradient-Strength based Adaptive Sharpness-Aware Minimization (GA-SAM) algorithm to help to learn algorithms find flat minima that generalize better. Results in various language benchmarks validate the effectiveness of the proposed GA-SAM algorithm on natural language tasks.
Adversarial Parameter Defense by Multi-Step Risk Minimization
Sep 07, 2021
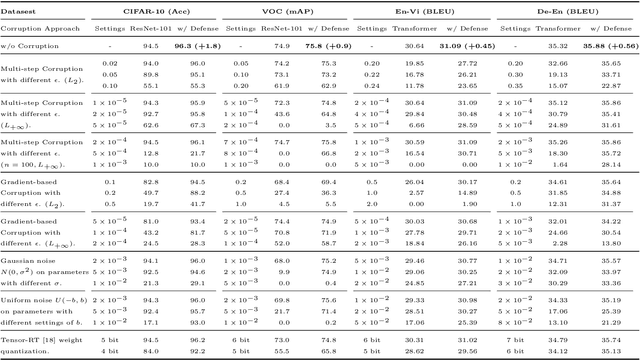
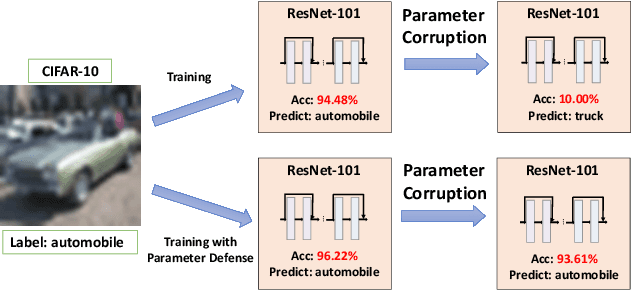
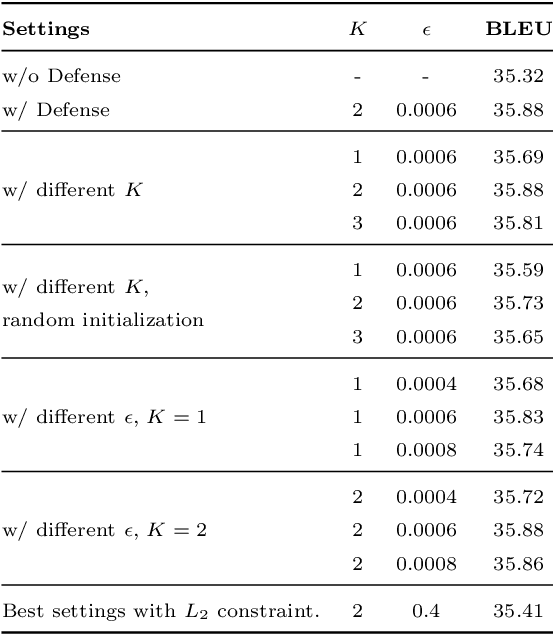
Previous studies demonstrate DNNs' vulnerability to adversarial examples and adversarial training can establish a defense to adversarial examples. In addition, recent studies show that deep neural networks also exhibit vulnerability to parameter corruptions. The vulnerability of model parameters is of crucial value to the study of model robustness and generalization. In this work, we introduce the concept of parameter corruption and propose to leverage the loss change indicators for measuring the flatness of the loss basin and the parameter robustness of neural network parameters. On such basis, we analyze parameter corruptions and propose the multi-step adversarial corruption algorithm. To enhance neural networks, we propose the adversarial parameter defense algorithm that minimizes the average risk of multiple adversarial parameter corruptions. Experimental results show that the proposed algorithm can improve both the parameter robustness and accuracy of neural networks.
* Accepted to Neural Networks. arXiv admin note: text overlap with arXiv:2006.05620
Learning Robust Representation for Clustering through Locality Preserving Variational Discriminative Network
Dec 25, 2020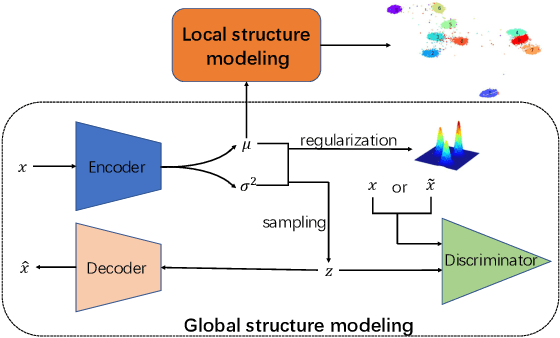
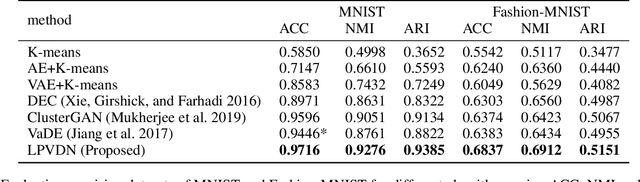
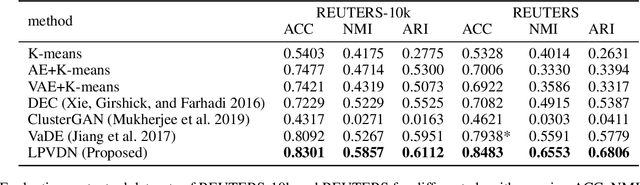
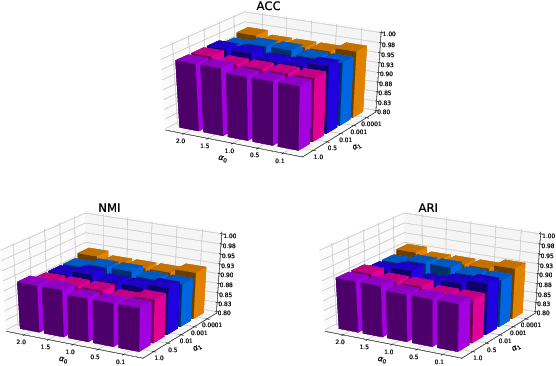
Clustering is one of the fundamental problems in unsupervised learning. Recent deep learning based methods focus on learning clustering oriented representations. Among those methods, Variational Deep Embedding achieves great success in various clustering tasks by specifying a Gaussian Mixture prior to the latent space. However, VaDE suffers from two problems: 1) it is fragile to the input noise; 2) it ignores the locality information between the neighboring data points. In this paper, we propose a joint learning framework that improves VaDE with a robust embedding discriminator and a local structure constraint, which are both helpful to improve the robustness of our model. Experiment results on various vision and textual datasets demonstrate that our method outperforms the state-of-the-art baseline models in all metrics. Further detailed analysis shows that our proposed model is very robust to the adversarial inputs, which is a desirable property for practical applications.
Exploring the Vulnerability of Deep Neural Networks: A Study of Parameter Corruption
Jun 10, 2020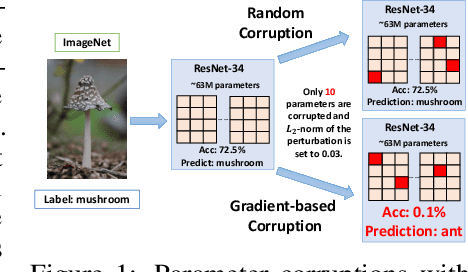
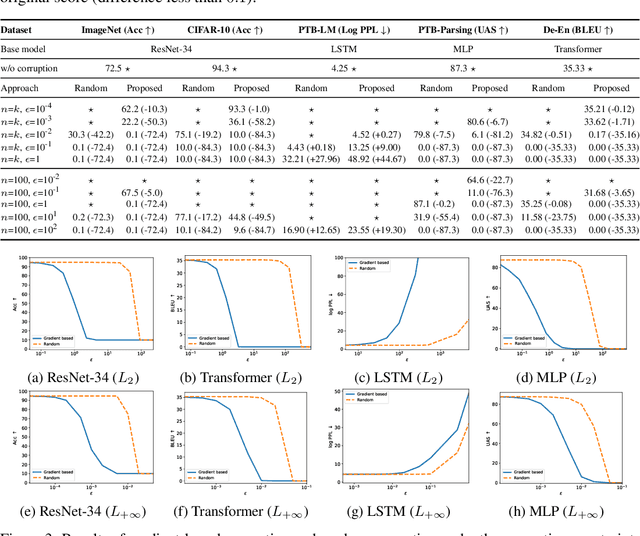
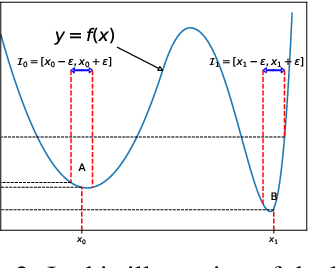

We argue that the vulnerability of model parameters is of crucial value to the study of model robustness and generalization but little research has been devoted to understanding this matter. In this work, we propose an indicator to measure the robustness of neural network parameters by exploiting their vulnerability via parameter corruption. The proposed indicator describes the maximum loss variation in the non-trivial worst-case scenario under parameter corruption. For practical purposes, we give a gradient-based estimation, which is far more effective than random corruption trials that can hardly induce the worst accuracy degradation. Equipped with theoretical support and empirical validation, we are able to systematically investigate the robustness of different model parameters and reveal vulnerability of deep neural networks that has been rarely paid attention to before. Moreover, we can enhance the models accordingly with the proposed adversarial corruption-resistant training, which not only improves the parameter robustness but also translates into accuracy elevation.
An Adaptive and Momental Bound Method for Stochastic Learning
Oct 27, 2019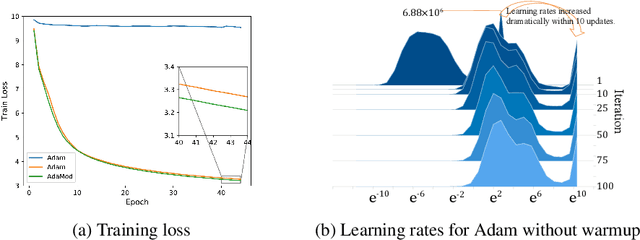
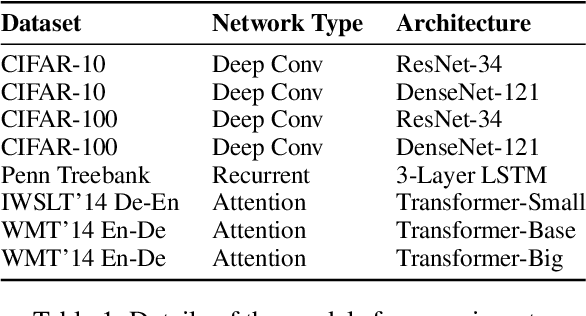
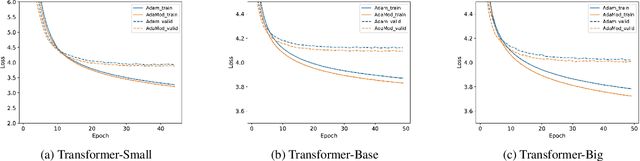

Training deep neural networks requires intricate initialization and careful selection of learning rates. The emergence of stochastic gradient optimization methods that use adaptive learning rates based on squared past gradients, e.g., AdaGrad, AdaDelta, and Adam, eases the job slightly. However, such methods have also been proven problematic in recent studies with their own pitfalls including non-convergence issues and so on. Alternative variants have been proposed for enhancement, such as AMSGrad, AdaShift and AdaBound. In this work, we identify a new problem of adaptive learning rate methods that exhibits at the beginning of learning where Adam produces extremely large learning rates that inhibit the start of learning. We propose the Adaptive and Momental Bound (AdaMod) method to restrict the adaptive learning rates with adaptive and momental upper bounds. The dynamic learning rate bounds are based on the exponential moving averages of the adaptive learning rates themselves, which smooth out unexpected large learning rates and stabilize the training of deep neural networks. Our experiments verify that AdaMod eliminates the extremely large learning rates throughout the training and brings significant improvements especially on complex networks such as DenseNet and Transformer, compared to Adam. Our implementation is available at: https://github.com/lancopku/AdaMod
PKUSEG: A Toolkit for Multi-Domain Chinese Word Segmentation
Jun 28, 2019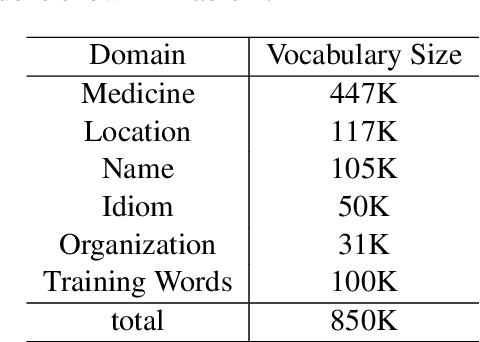


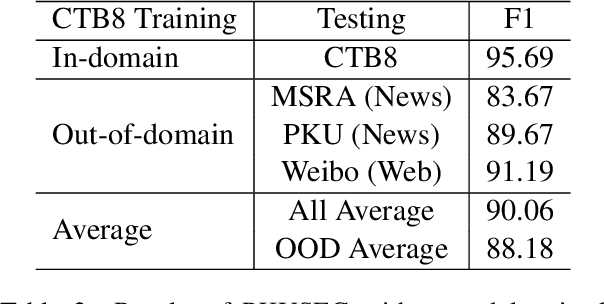
Chinese word segmentation (CWS) is a fundamental step of Chinese natural language processing. In this paper, we build a new toolkit, named PKUSEG, for multi-domain word segmentation. Unlike existing single-model toolkits, PKUSEG targets at multi-domain word segmentation and provides separate models for different domains, such as web, medicine, and tourism. The new toolkit also supports POS tagging and model training to adapt to various application scenarios. Experiments show that PKUSEG achieves high performance on multiple domains. The toolkit is now freely and publicly available for the usage of research and industry.
Exploration on Grounded Word Embedding: Matching Words and Images with Image-Enhanced Skip-Gram Model
Sep 08, 2018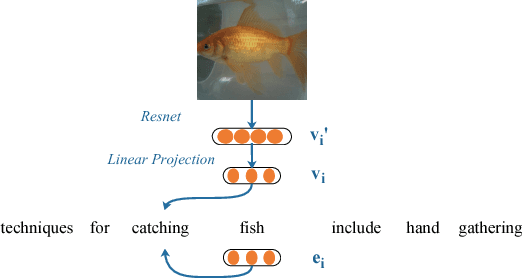

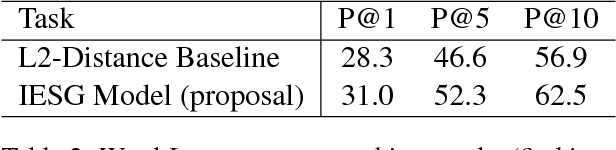

Word embedding is designed to represent the semantic meaning of a word with low dimensional vectors. The state-of-the-art methods of learning word embeddings (word2vec and GloVe) only use the word co-occurrence information. The learned embeddings are real number vectors, which are obscure to human. In this paper, we propose an Image-Enhanced Skip-Gram Model to learn grounded word embeddings by representing the word vectors in the same hyper-plane with image vectors. Experiments show that the image vectors and word embeddings learned by our model are highly correlated, which indicates that our model is able to provide a vivid image-based explanation to the word embeddings.
Acquisition of Localization Confidence for Accurate Object Detection
Jul 30, 2018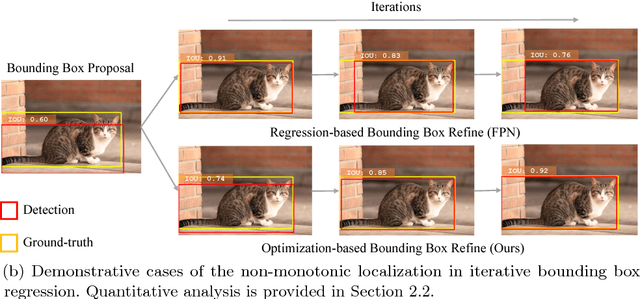

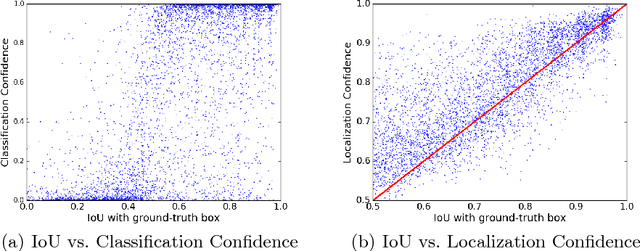
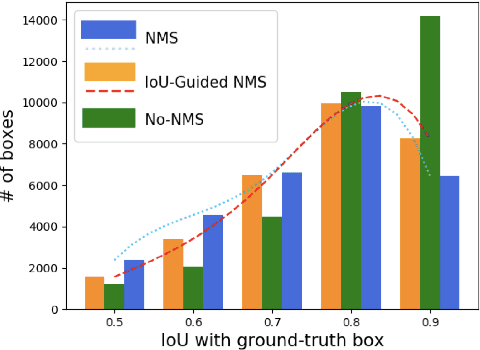
Modern CNN-based object detectors rely on bounding box regression and non-maximum suppression to localize objects. While the probabilities for class labels naturally reflect classification confidence, localization confidence is absent. This makes properly localized bounding boxes degenerate during iterative regression or even suppressed during NMS. In the paper we propose IoU-Net learning to predict the IoU between each detected bounding box and the matched ground-truth. The network acquires this confidence of localization, which improves the NMS procedure by preserving accurately localized bounding boxes. Furthermore, an optimization-based bounding box refinement method is proposed, where the predicted IoU is formulated as the objective. Extensive experiments on the MS-COCO dataset show the effectiveness of IoU-Net, as well as its compatibility with and adaptivity to several state-of-the-art object detectors.