 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic classification from possibilistic data: computing Kullback-Leibler projection with a possibility distribution
Apr 02, 2026We consider learning with possibilistic supervision for multi-class classification. For each training instance, the supervision is a normalized possibility distribution that expresses graded plausibility over the classes. From this possibility distribution, we construct a non-empty closed convex set of admissible probability distributions by combining two requirements: probabilistic compatibility with the possibility and necessity measures induced by the possibility distribution, and linear shape constraints that must be satisfied to preserve the qualitative structure of the possibility distribution. Thus, classes with the same possibility degree receive equal probabilities, and if a class has a strictly larger possibility degree than another class, then it receives a strictly larger probability. Given a strictly positive probability vector output by a model for an instance, we compute its Kullback-Leibler projection onto the admissible set. This projection yields the closest admissible probability distribution in Kullback-Leibler sense. We can then train the model by minimizing the divergence between the prediction and its projection, which quantifies the smallest adjustment needed to satisfy the induced dominance and shape constraints. The projection is computed with Dykstra's algorithm using Bregman projections associated with the negative entropy, and we provide explicit formulas for the projections onto each constraint set. Experiments conducted on synthetic data and on a real-world natural language inference task, based on the ChaosNLI dataset, show that the proposed projection algorithm is efficient enough for practical use, and that the resulting projection-based learning objective can improve predictive performance.
Credal Concept Bottleneck Models: Structural Separation of Epistemic and Aleatoric Uncertainty
Feb 11, 2026Decomposing predictive uncertainty into epistemic (model ignorance) and aleatoric (data ambiguity) components is central to reliable decision making, yet most methods estimate both from the same predictive distribution. Recent empirical and theoretical results show these estimates are typically strongly correlated, so changes in predictive spread simultaneously affect both components and blur their semantics. We propose a credal-set formulation in which uncertainty is represented as a set of predictive distributions, so that epistemic and aleatoric uncertainty correspond to distinct geometric properties: the size of the set versus the noise within its elements. We instantiate this idea in a Variational Credal Concept Bottleneck Model with two disjoint uncertainty heads trained by disjoint objectives and non-overlapping gradient paths, yielding separation by construction rather than post hoc decomposition. Across multi-annotator benchmarks, our approach reduces the correlation between epistemic and aleatoric uncertainty by over an order of magnitude compared to standard methods, while improving the alignment of epistemic uncertainty with prediction error and aleatoric uncertainty with ground-truth ambiguity.
MODE: Multi-Objective Adaptive Coreset Selection
Dec 24, 2025We present Mode(Multi-Objective adaptive Data Efficiency), a framework that dynamically combines coreset selection strategies based on their evolving contribution to model performance. Unlike static methods, \mode adapts selection criteria to training phases: emphasizing class balance early, diversity during representation learning, and uncertainty at convergence. We show that MODE achieves (1-1/e)-approximation with O(n \log n) complexity and demonstrates competitive accuracy while providing interpretable insights into data utility evolution. Experiments show \mode reduces memory requirements
$Π$-NeSy: A Possibilistic Neuro-Symbolic Approach
Apr 09, 2025In this article, we introduce a neuro-symbolic approach that combines a low-level perception task performed by a neural network with a high-level reasoning task performed by a possibilistic rule-based system. The goal is to be able to derive for each input instance the degree of possibility that it belongs to a target (meta-)concept. This (meta-)concept is connected to intermediate concepts by a possibilistic rule-based system. The probability of each intermediate concept for the input instance is inferred using a neural network. The connection between the low-level perception task and the high-level reasoning task lies in the transformation of neural network outputs modeled by probability distributions (through softmax activation) into possibility distributions. The use of intermediate concepts is valuable for the explanation purpose: using the rule-based system, the classification of an input instance as an element of the (meta-)concept can be justified by the fact that intermediate concepts have been recognized. From the technical side, our contribution consists of the design of efficient methods for defining the matrix relation and the equation system associated with a possibilistic rule-based system. The corresponding matrix and equation are key data structures used to perform inferences from a possibilistic rule-based system and to learn the values of the rule parameters in such a system according to a training data sample. Furthermore, leveraging recent results on the handling of inconsistent systems of fuzzy relational equations, an approach for learning rule parameters according to multiple training data samples is presented. Experiments carried out on the MNIST addition problems and the MNIST Sudoku puzzles problems highlight the effectiveness of our approach compared with state-of-the-art neuro-symbolic ones.
Dynamic Blocked Clause Elimination for Projected Model Counting
Aug 12, 2024
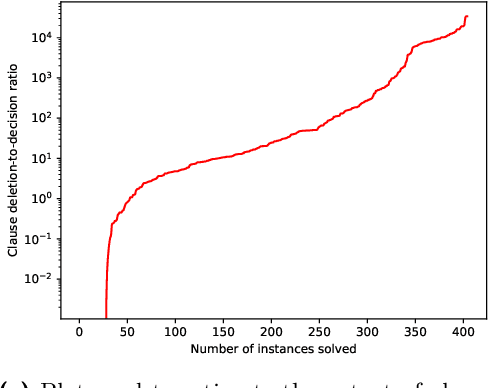
In this paper, we explore the application of blocked clause elimination for projected model counting. This is the problem of determining the number of models ||\exists X.{\Sigma}|| of a propositional formula {\Sigma} after eliminating a given set X of variables existentially. Although blocked clause elimination is a well-known technique for SAT solving, its direct application to model counting is challenging as in general it changes the number of models. However, we demonstrate, by focusing on projected variables during the blocked clause search, that blocked clause elimination can be leveraged while preserving the correct model count. To take advantage of blocked clause elimination in an efficient way during model counting, a novel data structure and associated algorithms are introduced. Our proposed approach is implemented in the model counter d4. Our experiments demonstrate the computational benefits of our new method of blocked clause elimination for projected model counting.
Reasoning About Action and Change
Jun 27, 2024The purpose of this book is to provide an overview of AI research, ranging from basic work to interfaces and applications, with as much emphasis on results as on current issues. It is aimed at an audience of master students and Ph.D. students, and can be of interest as well for researchers and engineers who want to know more about AI. The book is split into three volumes.
On the Complexity of Enumerating Prime Implicants from Decision-DNNF Circuits
Jan 30, 2023We consider the problem EnumIP of enumerating prime implicants of Boolean functions represented by decision decomposable negation normal form (dec-DNNF) circuits. We study EnumIP from dec-DNNF within the framework of enumeration complexity and prove that it is in OutputP, the class of output polynomial enumeration problems, and more precisely in IncP, the class of polynomial incremental time enumeration problems. We then focus on two closely related, but seemingly harder, enumeration problems where further restrictions are put on the prime implicants to be generated. In the first problem, one is only interested in prime implicants representing subset-minimal abductive explanations, a notion much investigated in AI for more than three decades. In the second problem, the target is prime implicants representing sufficient reasons, a recent yet important notion in the emerging field of eXplainable AI, since they aim to explain predictions achieved by machine learning classifiers. We provide evidence showing that enumerating specific prime implicants corresponding to subset-minimal abductive explanations or to sufficient reasons is not in OutputP.
Computing Abductive Explanations for Boosted Trees
Sep 16, 2022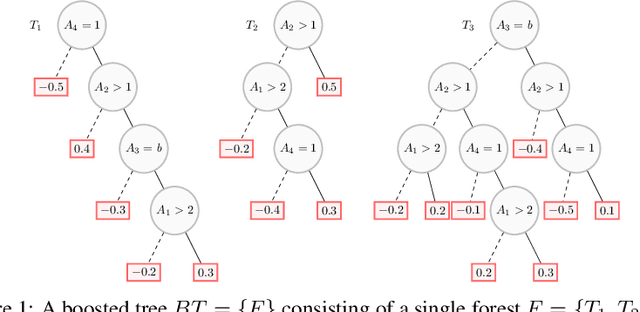

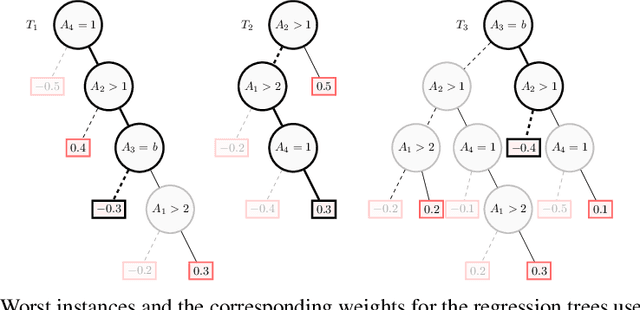
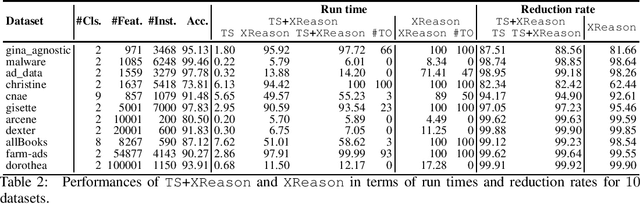
Boosted trees is a dominant ML model, exhibiting high accuracy. However, boosted trees are hardly intelligible, and this is a problem whenever they are used in safety-critical applications. Indeed, in such a context, rigorous explanations of the predictions made are expected. Recent work have shown how subset-minimal abductive explanations can be derived for boosted trees, using automated reasoning techniques. However, the generation of such well-founded explanations is intractable in the general case. To improve the scalability of their generation, we introduce the notion of tree-specific explanation for a boosted tree. We show that tree-specific explanations are abductive explanations that can be computed in polynomial time. We also explain how to derive a subset-minimal abductive explanation from a tree-specific explanation. Experiments on various datasets show the computational benefits of leveraging tree-specific explanations for deriving subset-minimal abductive explanations.
Rectifying Mono-Label Boolean Classifiers
Jun 17, 2022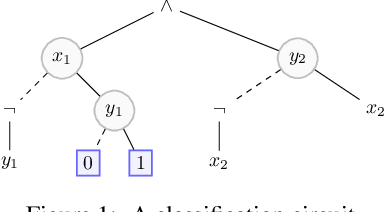

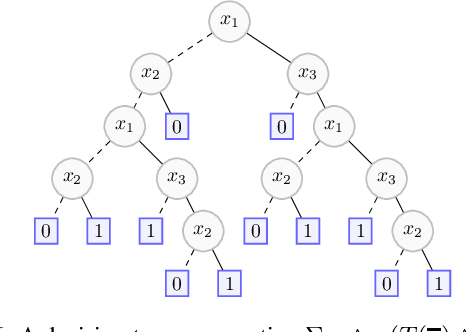
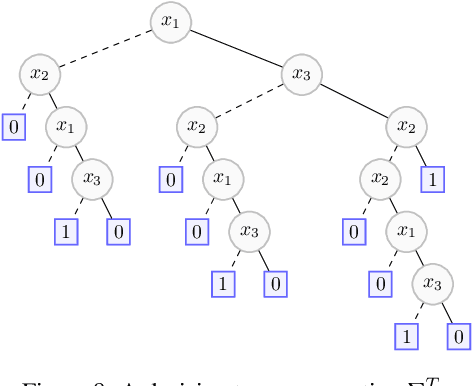
We elaborate on the notion of rectification of a Boolean classifier $\Sigma$. Given $\Sigma$ and some background knowledge $T$, postulates characterizing the way $\Sigma$ must be changed into a new classifier $\Sigma \star T$ that complies with $T$ have already been presented. We focus here on the specific case of mono-label Boolean classifiers, i.e., there is a single target concept and any instance is classified either as positive (an element of the concept), or as negative (an element of the complementary concept). In this specific case, our main contribution is twofold: (1) we show that there is a unique rectification operator $\star$ satisfying the postulates, and (2) when $\Sigma$ and $T$ are Boolean circuits, we show how a classification circuit equivalent to $\Sigma \star T$ can be computed in time linear in the size of $\Sigma$ and $T$; when $\Sigma$ and $T$ are decision trees, a decision tree equivalent to $\Sigma \star T$ can be computed in time polynomial in the size of $\Sigma$ and $T$.
Pseudo Polynomial-Time Top-k Algorithms for d-DNNF Circuits
Feb 11, 2022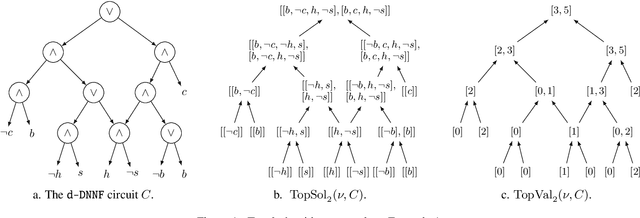

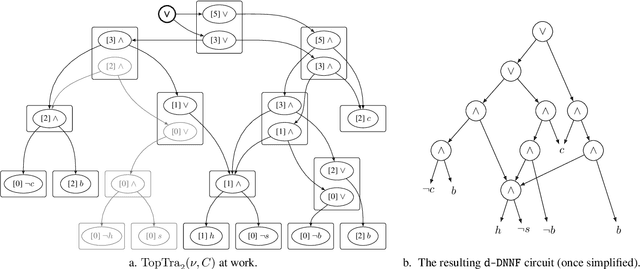
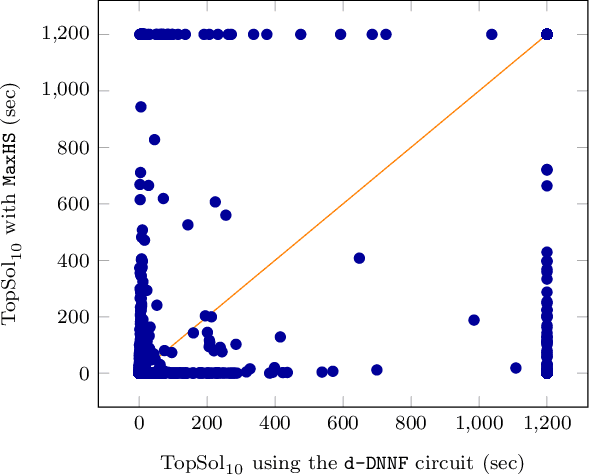
We are interested in computing $k$ most preferred models of a given d-DNNF circuit $C$, where the preference relation is based on an algebraic structure called a monotone, totally ordered, semigroup $(K, \otimes, <)$. In our setting, every literal in $C$ has a value in $K$ and the value of an assignment is an element of $K$ obtained by aggregating using $\otimes$ the values of the corresponding literals. We present an algorithm that computes $k$ models of $C$ among those having the largest values w.r.t. $<$, and show that this algorithm runs in time polynomial in $k$ and in the size of $C$. We also present a pseudo polynomial-time algorithm for deriving the top-$k$ values that can be reached, provided that an additional (but not very demanding) requirement on the semigroup is satisfied. Under the same assumption, we present a pseudo polynomial-time algorithm that transforms $C$ into a d-DNNF circuit $C'$ satisfied exactly by the models of $C$ having a value among the top-$k$ ones. Finally, focusing on the semigroup $(\mathbb{N}, +, <)$, we compare on a large number of instances the performances of our compilation-based algorithm for computing $k$ top solutions with those of an algorithm tackling the same problem, but based on a partial weighted MaxSAT solver.