 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Complexity of Enumerating Prime Implicants from Decision-DNNF Circuits
Jan 30, 2023We consider the problem EnumIP of enumerating prime implicants of Boolean functions represented by decision decomposable negation normal form (dec-DNNF) circuits. We study EnumIP from dec-DNNF within the framework of enumeration complexity and prove that it is in OutputP, the class of output polynomial enumeration problems, and more precisely in IncP, the class of polynomial incremental time enumeration problems. We then focus on two closely related, but seemingly harder, enumeration problems where further restrictions are put on the prime implicants to be generated. In the first problem, one is only interested in prime implicants representing subset-minimal abductive explanations, a notion much investigated in AI for more than three decades. In the second problem, the target is prime implicants representing sufficient reasons, a recent yet important notion in the emerging field of eXplainable AI, since they aim to explain predictions achieved by machine learning classifiers. We provide evidence showing that enumerating specific prime implicants corresponding to subset-minimal abductive explanations or to sufficient reasons is not in OutputP.
A Lower Bound on DNNF Encodings of Pseudo-Boolean Constraints
Jan 06, 2021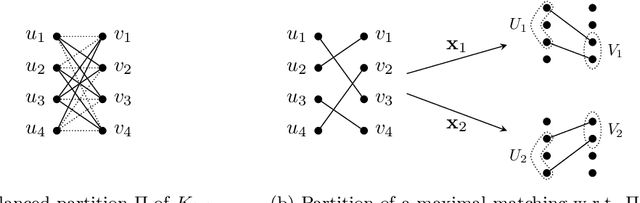
Two major considerations when encoding pseudo-Boolean (PB) constraints into SAT are the size of the encoding and its propagation strength, that is, the guarantee that it has a good behaviour under unit propagation. Several encodings with propagation strength guarantees rely upon prior compilation of the constraints into DNNF (decomposable negation normal form), BDD (binary decision diagram), or some other sub-variants. However it has been shown that there exist PB-constraints whose ordered BDD (OBDD) representations, and thus the inferred CNF encodings, all have exponential size. Since DNNFs are more succinct than OBDDs, preferring encodings via DNNF to avoid size explosion seems a legitimate choice. Yet in this paper, we prove the existence of PB-constraints whose DNNFs all require exponential size.
Lower Bounds for Approximate Knowledge Compilation
Nov 27, 2020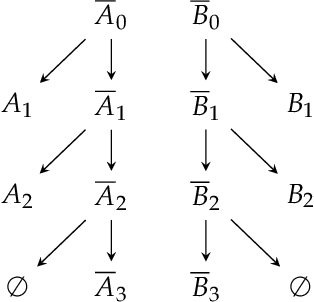
Knowledge compilation studies the trade-off between succinctness and efficiency of different representation languages. For many languages, there are known strong lower bounds on the representation size, but recent work shows that, for some languages, one can bypass these bounds using approximate compilation. The idea is to compile an approximation of the knowledge for which the number of errors can be controlled. We focus on circuits in deterministic decomposable negation normal form (d-DNNF), a compilation language suitable in contexts such as probabilistic reasoning, as it supports efficient model counting and probabilistic inference. Moreover, there are known size lower bounds for d-DNNF which by relaxing to approximation one might be able to avoid. In this paper we formalize two notions of approximation: weak approximation which has been studied before in the decision diagram literature and strong approximation which has been used in recent algorithmic results. We then show lower bounds for approximation by d-DNNF, complementing the positive results from the literature.