 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAfriSenti: A Twitter Sentiment Analysis Benchmark for African Languages
Feb 17, 2023



Africa is home to over 2000 languages from over six language families and has the highest linguistic diversity among all continents. This includes 75 languages with at least one million speakers each. Yet, there is little NLP research conducted on African languages. Crucial in enabling such research is the availability of high-quality annotated datasets. In this paper, we introduce AfriSenti, which consists of 14 sentiment datasets of 110,000+ tweets in 14 African languages (Amharic, Algerian Arabic, Hausa, Igbo, Kinyarwanda, Moroccan Arabic, Mozambican Portuguese, Nigerian Pidgin, Oromo, Swahili, Tigrinya, Twi, Xitsonga, and Yor\`ub\'a) from four language families annotated by native speakers. The data is used in SemEval 2023 Task 12, the first Afro-centric SemEval shared task. We describe the data collection methodology, annotation process, and related challenges when curating each of the datasets. We conduct experiments with different sentiment classification baselines and discuss their usefulness. We hope AfriSenti enables new work on under-represented languages. The dataset is available at https://github.com/afrisenti-semeval/afrisent-semeval-2023 and can also be loaded as a huggingface datasets (https://huggingface.co/datasets/shmuhammad/AfriSenti).
Contextualization for the Organization of Text Documents Streams
May 30, 2022


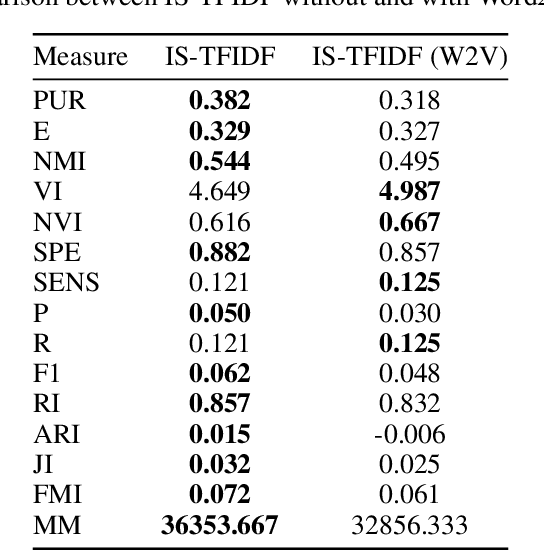
There has been a significant effort by the research community to address the problem of providing methods to organize documentation with the help of information Retrieval methods. In this report paper, we present several experiments with some stream analysis methods to explore streams of text documents. We use only dynamic algorithms to explore, analyze, and organize the flux of text documents. This document shows a case study with developed architectures of a Text Document Stream Organization, using incremental algorithms like Incremental TextRank, and IS-TFIDF. Both these algorithms are based on the assumption that the mapping of text documents and their document-term matrix in lower-dimensional evolving networks provides faster processing when compared to batch algorithms. With this architecture, and by using FastText Embedding to retrieve similarity between documents, we compare methods with large text datasets and ground truth evaluation of clustering capacities. The datasets used were Reuters and COVID-19 emotions. The results provide a new view for the contextualization of similarity when approaching flux of documents organization tasks, based on the similarity between documents in the flux, and by using mentioned algorithms.
NaijaSenti: A Nigerian Twitter Sentiment Corpus for Multilingual Sentiment Analysis
Jan 28, 2022
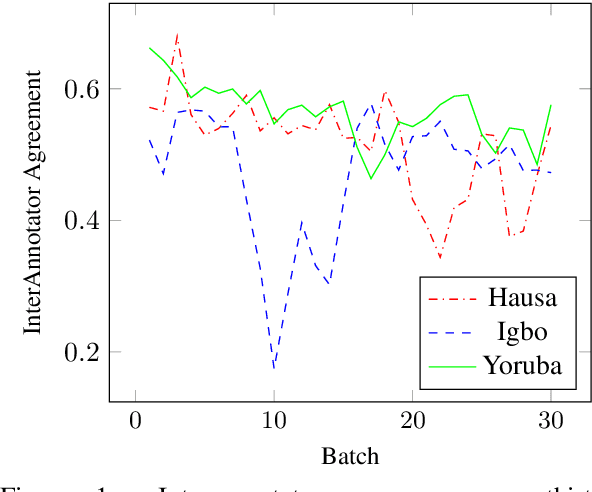

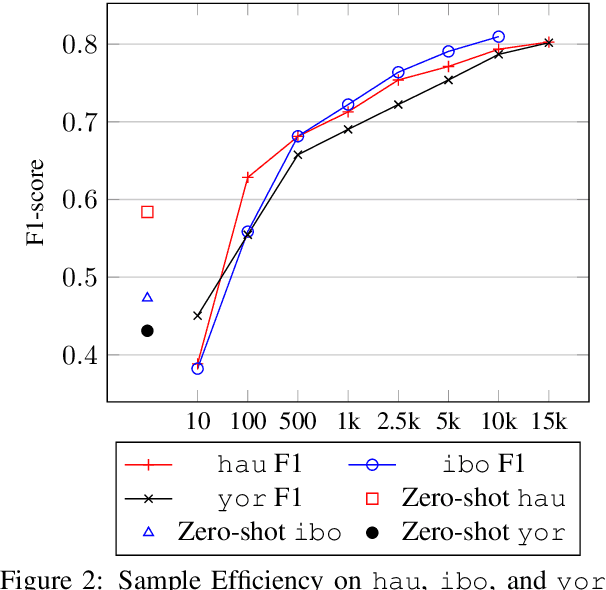
Sentiment analysis is one of the most widely studied applications in NLP, but most work focuses on languages with large amounts of data. We introduce the first large-scale human-annotated Twitter sentiment dataset for the four most widely spoken languages in Nigeria (Hausa, Igbo, Nigerian-Pidgin, and Yor\`ub\'a ) consisting of around 30,000 annotated tweets per language (and 14,000 for Nigerian-Pidgin), including a significant fraction of code-mixed tweets. We propose text collection, filtering, processing and labeling methods that enable us to create datasets for these low-resource languages. We evaluate a rangeof pre-trained models and transfer strategies on the dataset. We find that language-specific models and language-adaptivefine-tuning generally perform best. We release the datasets, trained models, sentiment lexicons, and code to incentivizeresearch on sentiment analysis in under-represented languages.
Effect of Incomplete Meta-dataset on Average Ranking Method
Aug 24, 2016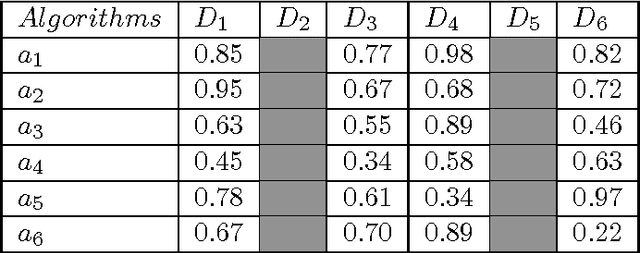
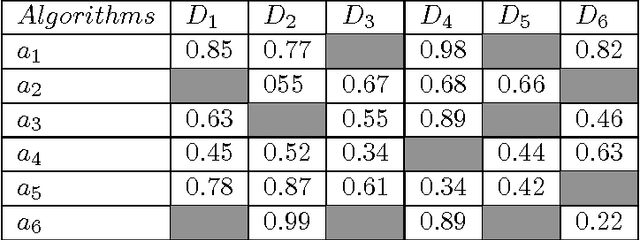
One of the simplest metalearning methods is the average ranking method. This method uses metadata in the form of test results of a given set of algorithms on given set of datasets and calculates an average rank for each algorithm. The ranks are used to construct the average ranking. We investigate the problem of how the process of generating the average ranking is affected by incomplete metadata including fewer test results. This issue is relevant, because if we could show that incomplete metadata does not affect the final results much, we could explore it in future design. We could simply conduct fewer tests and save thus computation time. In this paper we describe an upgraded average ranking method that is capable of dealing with incomplete metadata. Our results show that the proposed method is relatively robust to omission in test results in the meta datasets.