 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextualization for the Organization of Text Documents Streams
May 30, 2022


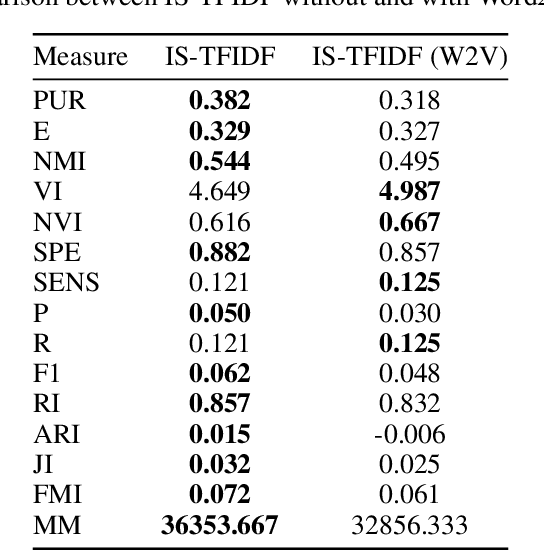
There has been a significant effort by the research community to address the problem of providing methods to organize documentation with the help of information Retrieval methods. In this report paper, we present several experiments with some stream analysis methods to explore streams of text documents. We use only dynamic algorithms to explore, analyze, and organize the flux of text documents. This document shows a case study with developed architectures of a Text Document Stream Organization, using incremental algorithms like Incremental TextRank, and IS-TFIDF. Both these algorithms are based on the assumption that the mapping of text documents and their document-term matrix in lower-dimensional evolving networks provides faster processing when compared to batch algorithms. With this architecture, and by using FastText Embedding to retrieve similarity between documents, we compare methods with large text datasets and ground truth evaluation of clustering capacities. The datasets used were Reuters and COVID-19 emotions. The results provide a new view for the contextualization of similarity when approaching flux of documents organization tasks, based on the similarity between documents in the flux, and by using mentioned algorithms.
Confirmatory Factor Analysis -- A Case study
May 08, 2019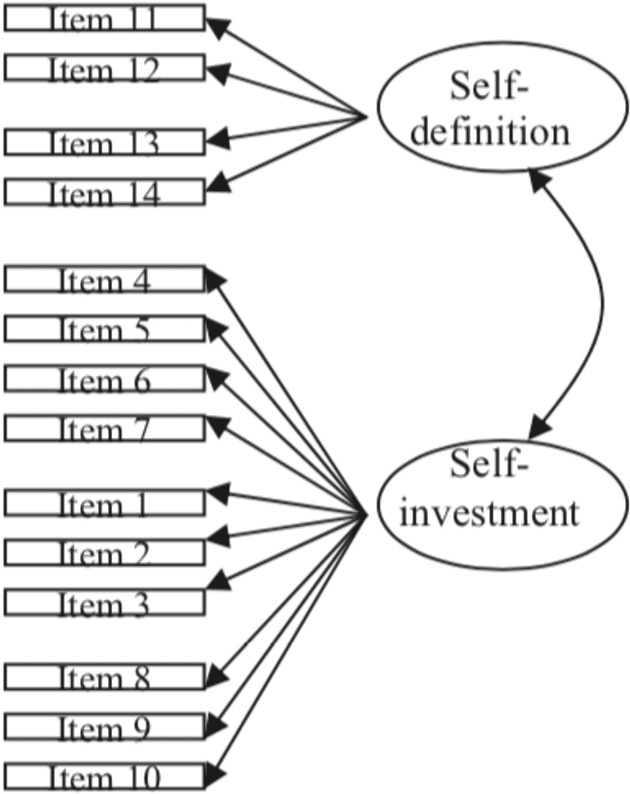
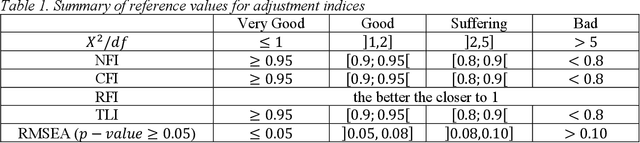

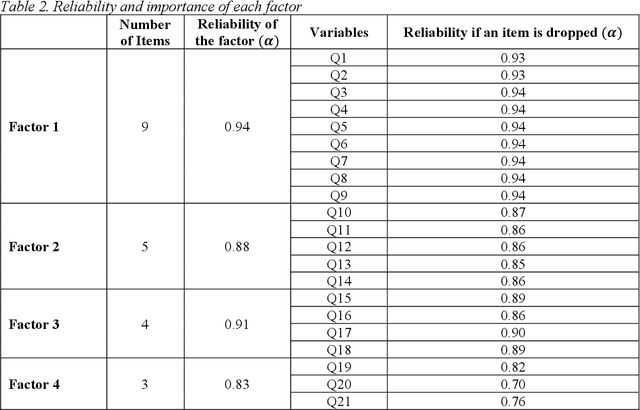
Confirmatory Factor Analysis (CFA) is a particular form of factor analysis, most commonly used in social research. In confirmatory factor analysis, the researcher first develops a hypothesis about what factors they believe are underlying the used measures and may impose constraints on the model based on these a priori hypotheses. For example, if two factors are accounting for the covariance in the measures, and these factors are unrelated to one another, we can create a model where the correlation between factor X and factor Y is set to zero. Measures could then be obtained to assess how well the fitted model captured the covariance between all the items or measures in the model. Thus, if the results of statistical tests of the model fit indicate a poor fit, the model will be rejected. If the fit is weak, it may be due to a variety of reasons. We propose to introduce state of the art techniques to do CFA in R language. Then, we propose to do some examples of CFA with R and some datasets, revealing several scenarios where CFA is relevant.