 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffect of Incomplete Meta-dataset on Average Ranking Method
Aug 24, 2016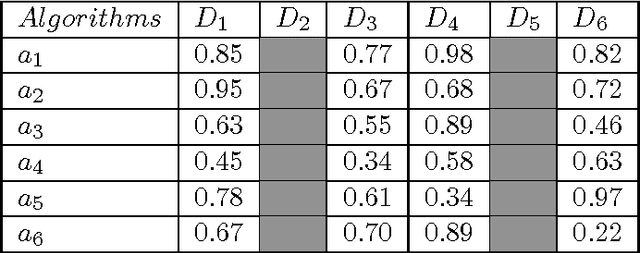
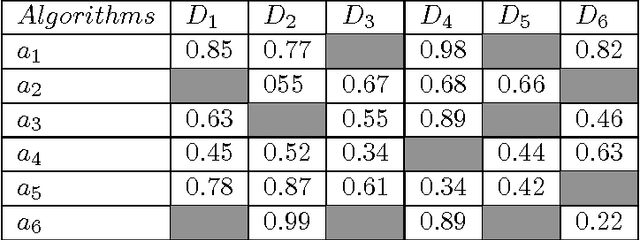
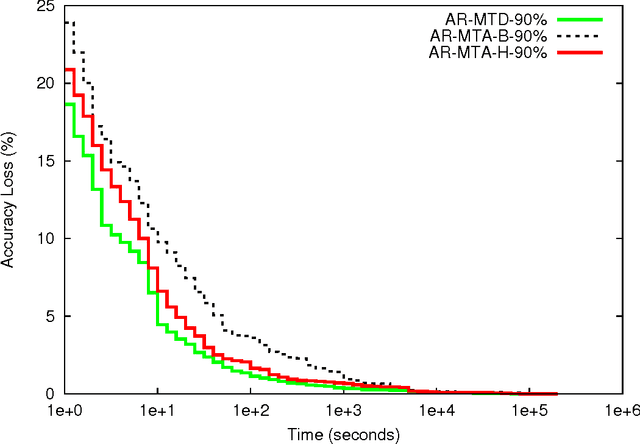
One of the simplest metalearning methods is the average ranking method. This method uses metadata in the form of test results of a given set of algorithms on given set of datasets and calculates an average rank for each algorithm. The ranks are used to construct the average ranking. We investigate the problem of how the process of generating the average ranking is affected by incomplete metadata including fewer test results. This issue is relevant, because if we could show that incomplete metadata does not affect the final results much, we could explore it in future design. We could simply conduct fewer tests and save thus computation time. In this paper we describe an upgraded average ranking method that is capable of dealing with incomplete metadata. Our results show that the proposed method is relatively robust to omission in test results in the meta datasets.