 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisk Estimation for Automated Driving
Jan 21, 2026Safety is a central requirement for automated vehicles. As such, the assessment of risk in automated driving is key in supporting both motion planning technologies and safety evaluation. In automated driving, risk is characterized by two aspects. The first aspect is the uncertainty on the state estimates of other road participants by an automated vehicle. The second aspect is the severity of a collision event with said traffic participants. Here, the uncertainty aspect typically causes the risk to be non-zero for near-collision events. This makes risk particularly useful for automated vehicle motion planning. Namely, constraining or minimizing risk naturally navigates the automated vehicle around traffic participants while keeping a safety distance based on the level of uncertainty and the potential severity of the impending collision. Existing approaches to calculate the risk either resort to empirical modeling or severe approximations, and, hence, lack generalizability and accuracy. In this paper, we combine recent advances in collision probability estimation with the concept of collision severity to develop a general method for accurate risk estimation. The proposed method allows us to assign individual severity functions for different collision constellations, such as, e.g., frontal or side collisions. Furthermore, we show that the proposed approach is computationally efficient, which is beneficial, e.g., in real-time motion planning applications. The programming code for an exemplary implementation of Gaussian uncertainties is also provided.
Collision Probability Estimation for Optimization-based Vehicular Motion Planning
May 27, 2025Many motion planning algorithms for automated driving require estimating the probability of collision (POC) to account for uncertainties in the measurement and estimation of the motion of road users. Common POC estimation techniques often utilize sampling-based methods that suffer from computational inefficiency and a non-deterministic estimation, i.e., each estimation result for the same inputs is slightly different. In contrast, optimization-based motion planning algorithms require computationally efficient POC estimation, ideally using deterministic estimation, such that typical optimization algorithms for motion planning retain feasibility. Estimating the POC analytically, however, is challenging because it depends on understanding the collision conditions (e.g., vehicle's shape) and characterizing the uncertainty in motion prediction. In this paper, we propose an approach in which we estimate the POC between two vehicles by over-approximating their shapes by a multi-circular shape approximation. The position and heading of the predicted vehicle are modelled as random variables, contrasting with the literature, where the heading angle is often neglected. We guarantee that the provided POC is an over-approximation, which is essential in providing safety guarantees, and present a computationally efficient algorithm for computing the POC estimate for Gaussian uncertainty in the position and heading. This algorithm is then used in a path-following stochastic model predictive controller (SMPC) for motion planning. With the proposed algorithm, the SMPC generates reproducible trajectories while the controller retains its feasibility in the presented test cases and demonstrates the ability to handle varying levels of uncertainty.
Hybrid Model-Data Fault Diagnosis for Wafer Handler Robots: Tilt and Broken Belt Cases
Dec 12, 2024



This work proposes a hybrid model- and data-based scheme for fault detection, isolation, and estimation (FDIE) for a class of wafer handler (WH) robots. The proposed hybrid scheme consists of: 1) a linear filter that simultaneously estimates system states and fault-induced signals from sensing and actuation data; and 2) a data-driven classifier, in the form of a support vector machine (SVM), that detects and isolates the fault type using estimates generated by the filter. We demonstrate the effectiveness of the scheme for two critical fault types for WH robots used in the semiconductor industry: broken-belt in the lower arm of the WH robot (an abrupt fault) and tilt in the robot arms (an incipient fault). We derive explicit models of the robot motion dynamics induced by these faults and test the diagnostics scheme in a realistic simulation-based case study. These case study results demonstrate that the proposed hybrid FDIE scheme achieves superior performance compared to purely data-driven methods.
Impact-Aware Control using Time-Invariant Reference Spreading
Nov 15, 2024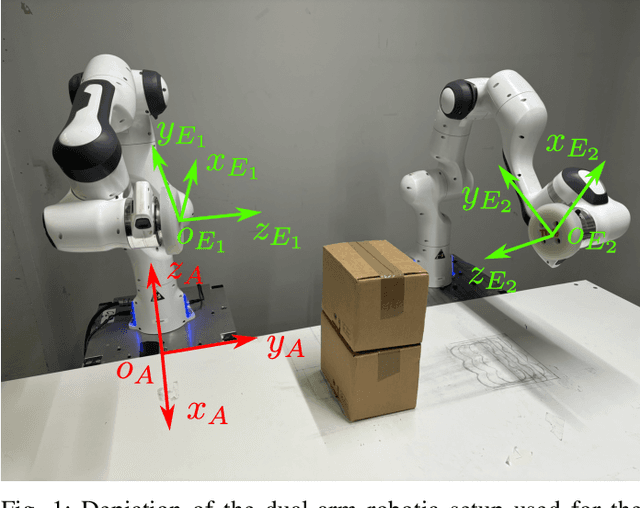
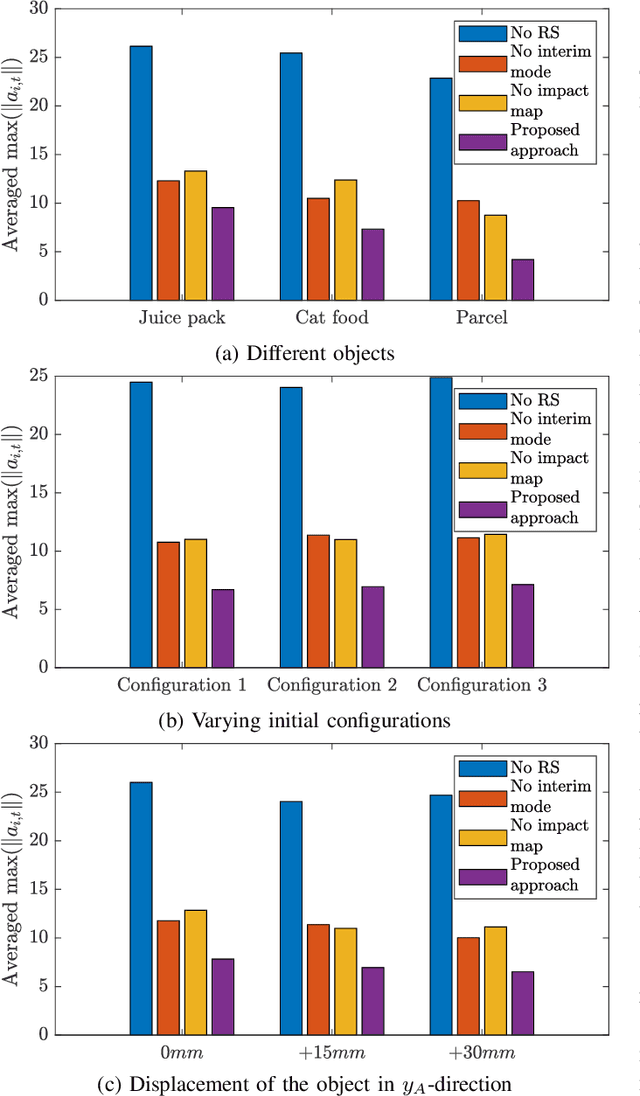
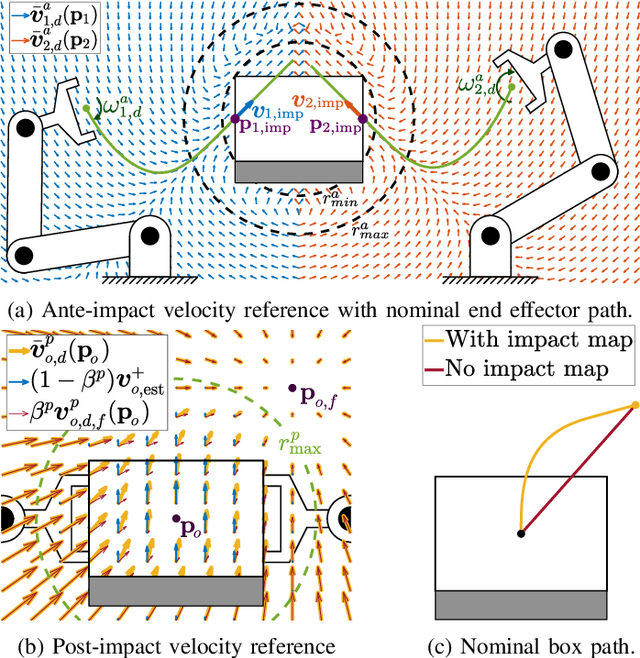
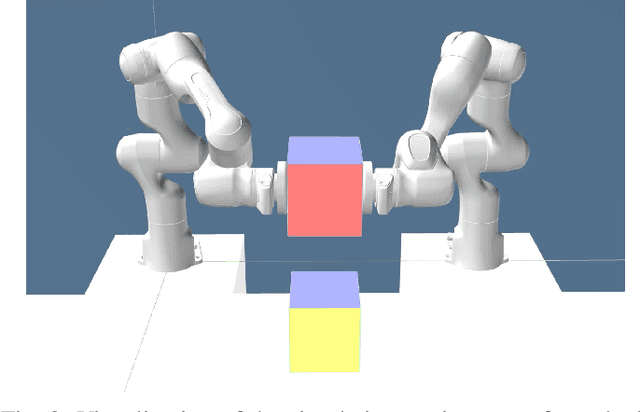
With the goal of increasing the speed and efficiency in robotic manipulation, a control approach is presented that aims to utilize intentional simultaneous impacts to its advantage. This approach exploits the concept of the time-invariant reference spreading framework, in which partly-overlapping ante- and post-impact reference vector fields are used. These vector fields are coupled via an impact model in proximity of the expected impact area, minimizing the otherwise large impact-induced velocity errors and control efforts. We show how a nonsmooth physics engine can be used to construct this impact model for complex scenarios, which warrants applicability to a large range of possible impact states without requiring contact stiffness and damping parameters. In addition, a novel interim-impact control mode provides robustness in the execution against the inevitable lack of exact impact simultaneity and the corresponding unreliable velocity error during the time when contact is only partially established. This interim mode uses a position feedback signal that is derived from the ante-impact velocity reference to promote contact completion, and smoothly transitions into the post-impact mode. An experimental validation of time-invariant reference spreading control is presented for the first time through a set of 600 robotic hit-and-push and dual-arm grabbing experiments.
Impact-Aware Robotic Manipulation: Quantifying the Sim-To-Real Gap for Velocity Jumps
Nov 10, 2024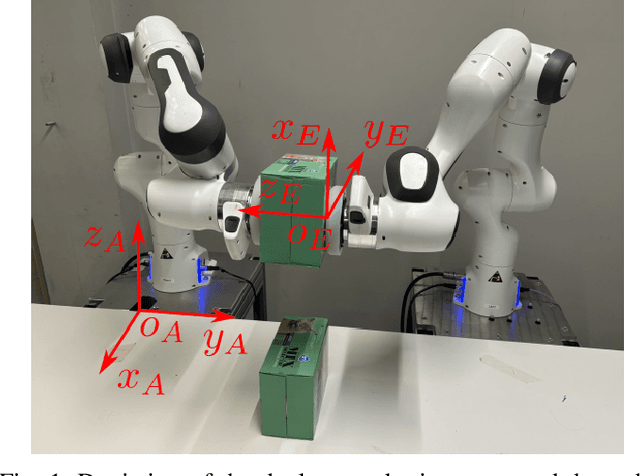


Impact-aware robotic manipulation benefits from an accurate map from ante-impact to post-impact velocity signals to support, e.g., motion planning and control. This work proposes an approach to generate and experimentally validate such impact maps from simulations with a physics engine, allowing to model impact scenarios of arbitrarily large complexity. This impact map captures the velocity jump assuming an instantaneous contact transition between rigid objects, neglecting the nearly instantaneous contact transition and impact-induced vibrations. Feedback control, which is required for complex impact scenarios, will affect velocity signals when these vibrations are still active, making an evaluation solely based on velocity signals as in previous works unreliable. Instead, the proposed validation approach uses the reference spreading control framework, which aims to reduce peaks and jumps in the control feedback signals by using a reference consistent with the rigid impact map together with a suitable control scheme. Based on the key idea that selecting the correct rigid impact map in this reference spreading framework will minimize the net feedback signal, the rigid impact map is experimentally determined and compared with the impact map obtained from simulation, resulting in a 3.1% average error between the post-impact velocity identified from simulations and from experiments.
Immersion and Invariance-based Coding for Privacy-Preserving Federated Learning
Sep 25, 2024



Federated learning (FL) has emerged as a method to preserve privacy in collaborative distributed learning. In FL, clients train AI models directly on their devices rather than sharing data with a centralized server, which can pose privacy risks. However, it has been shown that despite FL's partial protection of local data privacy, information about clients' data can still be inferred from shared model updates during training. In recent years, several privacy-preserving approaches have been developed to mitigate this privacy leakage in FL, though they often provide privacy at the cost of model performance or system efficiency. Balancing these trade-offs presents a significant challenge in implementing FL schemes. In this manuscript, we introduce a privacy-preserving FL framework that combines differential privacy and system immersion tools from control theory. The core idea is to treat the optimization algorithms used in standard FL schemes (e.g., gradient-based algorithms) as a dynamical system that we seek to immerse into a higher-dimensional system (referred to as the target optimization algorithm). The target algorithm's dynamics are designed such that, first, the model parameters of the original algorithm are immersed in its parameters; second, it operates on distorted parameters; and third, it converges to an encoded version of the true model parameters from the original algorithm. These encoded parameters can then be decoded at the server to retrieve the original model parameters. We demonstrate that the proposed privacy-preserving scheme can be tailored to offer any desired level of differential privacy for both local and global model parameters, while maintaining the same accuracy and convergence rate as standard FL algorithms.
Fast Collision Probability Estimation for Automated Driving using Multi-circular Shape Approximations
May 17, 2024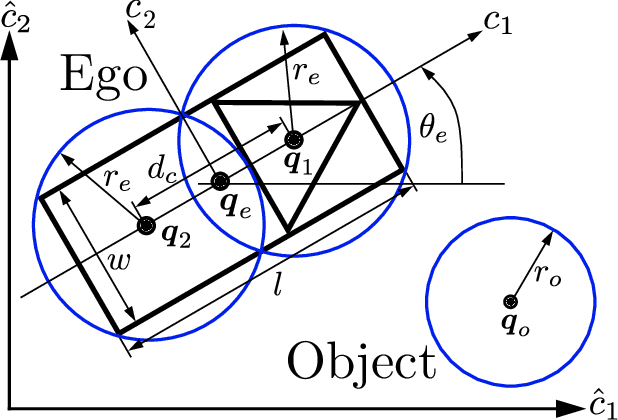
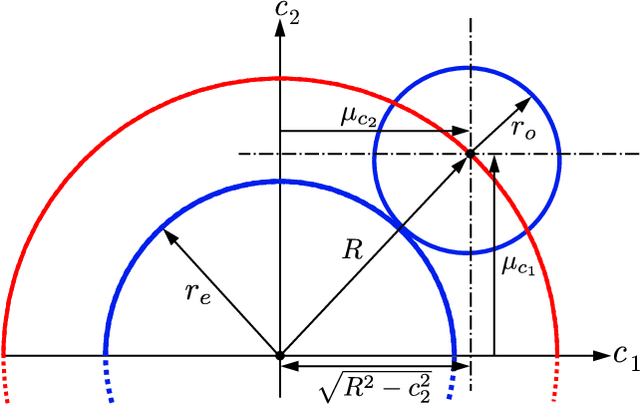
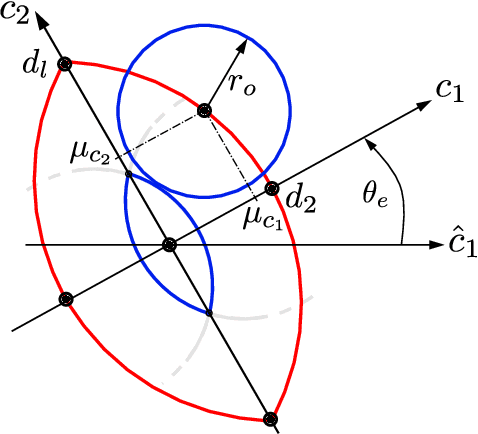

Many state-of-the-art methods for safety assessment and motion planning for automated driving require estimation of the probability of collision (POC). To estimate the POC, a shape approximation of the colliding actors and probability density functions of the associated uncertain kinematic variables are required. Even with such information available, the derivation of the POC is in general, i.e., for any shape and density, only possible with Monte Carlo sampling (MCS). Random sampling of the POC, however, is challenging as computational resources are limited in real-world applications. We present expressions for the POC in the presence of Gaussian uncertainties, based on multi-circular shape approximations. In addition, we show that the proposed approach is computationally more efficient than MCS. Lastly, we provide a method for upper and lower bounding the estimation error for the POC induced by the used shape approximations.
Overcoming the Fear of the Dark: Occlusion-Aware Model-Predictive Planning for Automated Vehicles Using Risk Fields
Sep 27, 2023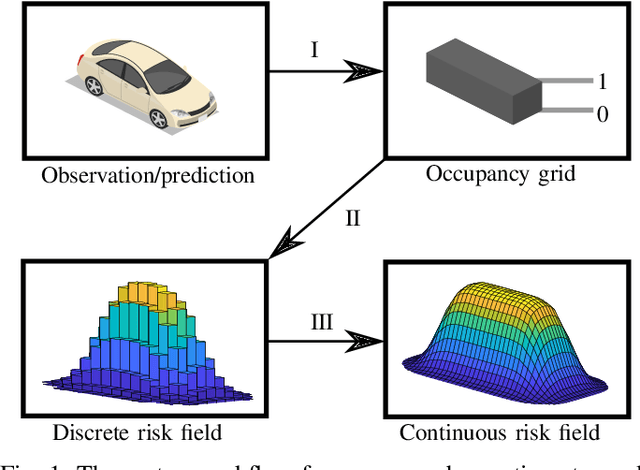
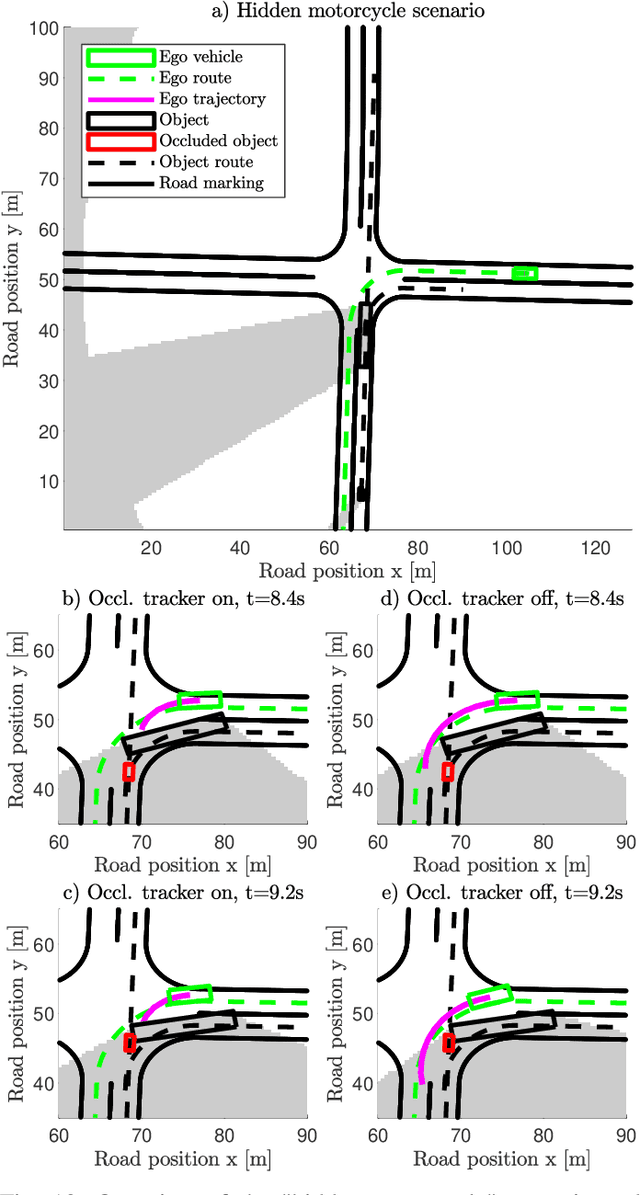
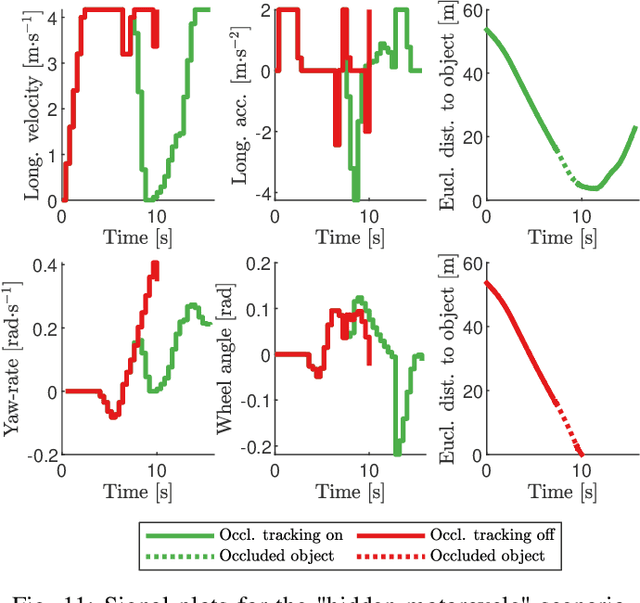
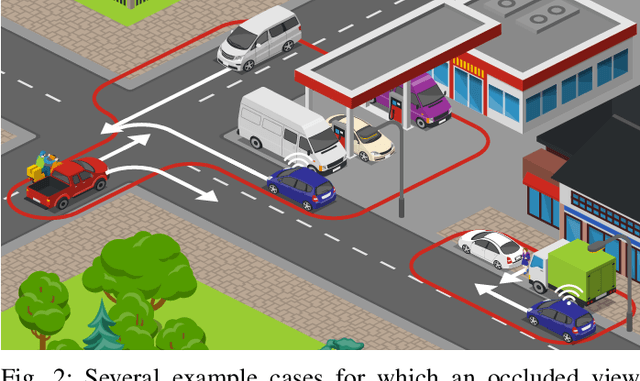
As vehicle automation advances, motion planning algorithms face escalating challenges in achieving safe and efficient navigation. Existing Advanced Driver Assistance Systems (ADAS) primarily focus on basic tasks, leaving unexpected scenarios for human intervention, which can be error-prone. Motion planning approaches for higher levels of automation in the state-of-the-art are primarily oriented toward the use of risk- or anti-collision constraints, using over-approximates of the shapes and sizes of other road users to prevent collisions. These methods however suffer from conservative behavior and the risk of infeasibility in high-risk initial conditions. In contrast, our work introduces a novel multi-objective trajectory generation approach. We propose an innovative method for constructing risk fields that accommodates diverse entity shapes and sizes, which allows us to also account for the presence of potentially occluded objects. This methodology is integrated into an occlusion-aware trajectory generator, enabling dynamic and safe maneuvering through intricate environments while anticipating (potentially hidden) road users and traveling along the infrastructure toward a specific goal. Through theoretical underpinnings and simulations, we validate the effectiveness of our approach. This paper bridges crucial gaps in motion planning for automated vehicles, offering a pathway toward safer and more adaptable autonomous navigation in complex urban contexts.
Quadratic Programming-based Reference Spreading Control for Dual-Arm Robotic Manipulation with Planned Simultaneous Impacts
May 15, 2023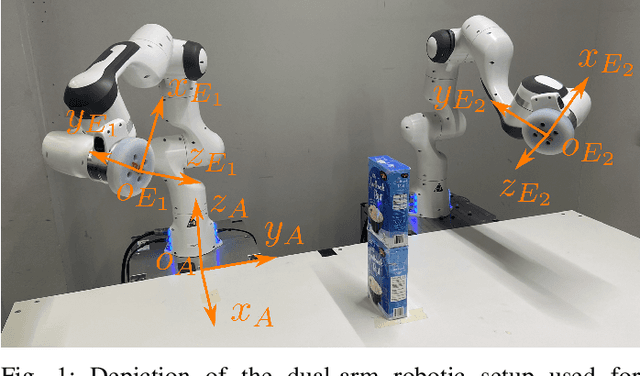
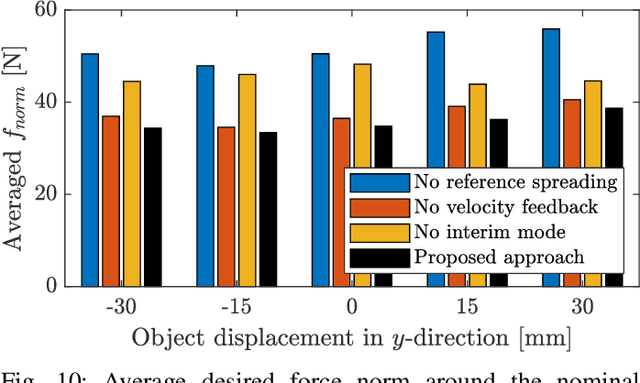

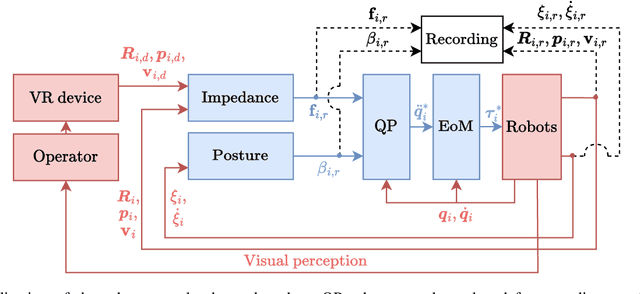
With the aim of further enabling the exploitation of intentional impacts in robotic manipulation, a control framework is presented that directly tackles the challenges posed by tracking control of robotic manipulators that are tasked to perform nominally simultaneous impacts. This framework is an extension of the reference spreading control framework, in which overlapping ante- and post-impact references that are consistent with impact dynamics are defined. In this work, such a reference is constructed starting from a teleoperation-based approach. By using the corresponding ante- and post-impact control modes in the scope of a quadratic programming control approach, peaking of the velocity error and control inputs due to impacts is avoided while maintaining high tracking performance. With the inclusion of a novel interim mode, we aim to also avoid input peaks and steps when uncertainty in the environment causes a series of unplanned single impacts to occur rather than the planned simultaneous impact. This work in particular presents for the first time an experimental evaluation of reference spreading control on a robotic setup, showcasing its robustness against uncertainty in the environment compared to two baseline control approaches.
Adaptive Headway Motion Control and Motion Prediction for Safe Unicycle Motion Design
Apr 05, 2023Differential drive robots that can be modeled as a kinematic unicycle are a standard mobile base platform for many service and logistics robots. Safe and smooth autonomous motion around obstacles is a crucial skill for unicycle robots to perform diverse tasks in complex environments. A classical control approach for unicycle control is feedback linearization using a headway point at a fixed headway distance in front of the unicycle. The unicycle headway control brings the headway point to a desired goal location by embedding a linear headway reference dynamics, which often results in an undesired offset for the actual unicycle position. In this paper, we introduce a new unicycle headway control approach with an adaptive headway distance that overcomes this limitation, i.e., when the headway point reaches the goal the unicycle position is also at the goal. By systematically analyzing the closed-loop unicycle motion under the adaptive headway controller, we design analytical feedback motion prediction methods that bound the closed-loop unicycle position trajectory and so can be effectively used for safety assessment and safe unicycle motion design around obstacles. We present an application of adaptive headway motion control and motion prediction for safe unicycle path following around obstacles in numerical simulations.