 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Model-Data Fault Diagnosis for Wafer Handler Robots: Tilt and Broken Belt Cases
Dec 12, 2024



This work proposes a hybrid model- and data-based scheme for fault detection, isolation, and estimation (FDIE) for a class of wafer handler (WH) robots. The proposed hybrid scheme consists of: 1) a linear filter that simultaneously estimates system states and fault-induced signals from sensing and actuation data; and 2) a data-driven classifier, in the form of a support vector machine (SVM), that detects and isolates the fault type using estimates generated by the filter. We demonstrate the effectiveness of the scheme for two critical fault types for WH robots used in the semiconductor industry: broken-belt in the lower arm of the WH robot (an abrupt fault) and tilt in the robot arms (an incipient fault). We derive explicit models of the robot motion dynamics induced by these faults and test the diagnostics scheme in a realistic simulation-based case study. These case study results demonstrate that the proposed hybrid FDIE scheme achieves superior performance compared to purely data-driven methods.
Immersion and Invariance-based Coding for Privacy-Preserving Federated Learning
Sep 25, 2024



Federated learning (FL) has emerged as a method to preserve privacy in collaborative distributed learning. In FL, clients train AI models directly on their devices rather than sharing data with a centralized server, which can pose privacy risks. However, it has been shown that despite FL's partial protection of local data privacy, information about clients' data can still be inferred from shared model updates during training. In recent years, several privacy-preserving approaches have been developed to mitigate this privacy leakage in FL, though they often provide privacy at the cost of model performance or system efficiency. Balancing these trade-offs presents a significant challenge in implementing FL schemes. In this manuscript, we introduce a privacy-preserving FL framework that combines differential privacy and system immersion tools from control theory. The core idea is to treat the optimization algorithms used in standard FL schemes (e.g., gradient-based algorithms) as a dynamical system that we seek to immerse into a higher-dimensional system (referred to as the target optimization algorithm). The target algorithm's dynamics are designed such that, first, the model parameters of the original algorithm are immersed in its parameters; second, it operates on distorted parameters; and third, it converges to an encoded version of the true model parameters from the original algorithm. These encoded parameters can then be decoded at the server to retrieve the original model parameters. We demonstrate that the proposed privacy-preserving scheme can be tailored to offer any desired level of differential privacy for both local and global model parameters, while maintaining the same accuracy and convergence rate as standard FL algorithms.
Privacy-Preserving Federated Learning via System Immersion and Random Matrix Encryption
Apr 05, 2022

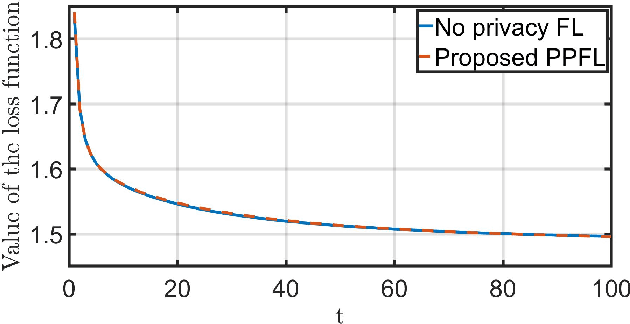
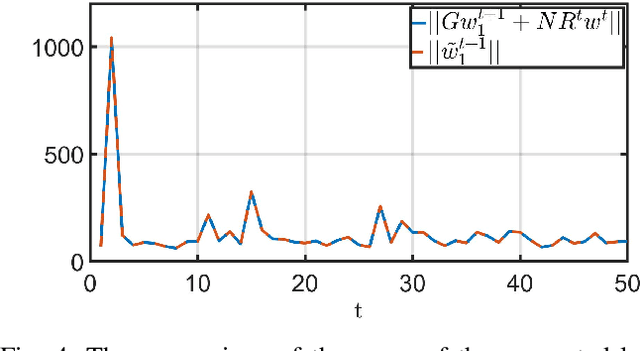
Federated learning (FL) has emerged as a privacy solution for collaborative distributed learning where clients train AI models directly on their devices instead of sharing their data with a centralized (potentially adversarial) server. Although FL preserves local data privacy to some extent, it has been shown that information about clients' data can still be inferred from model updates. In recent years, various privacy-preserving schemes have been developed to address this privacy leakage. However, they often provide privacy at the expense of model performance or system efficiency and balancing these tradeoffs is a crucial challenge when implementing FL schemes. In this manuscript, we propose a Privacy-Preserving Federated Learning (PPFL) framework built on the synergy of matrix encryption and system immersion tools from control theory. The idea is to immerse the learning algorithm, a Stochastic Gradient Decent (SGD), into a higher-dimensional system (the so-called target system) and design the dynamics of the target system so that: the trajectories of the original SGD are immersed/embedded in its trajectories, and it learns on encrypted data (here we use random matrix encryption). Matrix encryption is reformulated at the server as a random change of coordinates that maps original parameters to a higher-dimensional parameter space and enforces that the target SGD converges to an encrypted version of the original SGD optimal solution. The server decrypts the aggregated model using the left inverse of the immersion map. We show that our algorithm provides the same level of accuracy and convergence rate as the standard FL with a negligible computation cost while revealing no information about the clients' data.
Learning Agents in Black-Scholes Financial Markets: Consensus Dynamics and Volatility Smiles
May 24, 2017



Black-Scholes (BS) is the standard mathematical model for option pricing in financial markets. Option prices are calculated using an analytical formula whose main inputs are strike (at which price to exercise) and volatility. The BS framework assumes that volatility remains constant across all strikes, however, in practice it varies. How do traders come to learn these parameters? We introduce natural models of learning agents, in which they update their beliefs about the true implied volatility based on the opinions of other traders. We prove convergence of these opinion dynamics using techniques from control theory and leader-follower models, thus providing a resolution between theory and market practices. We allow for two different models, one with feedback and one with an unknown leader.