 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModelling calibration uncertainty in networks of environmental sensors
May 09, 2022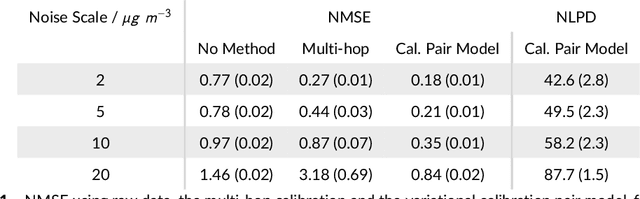

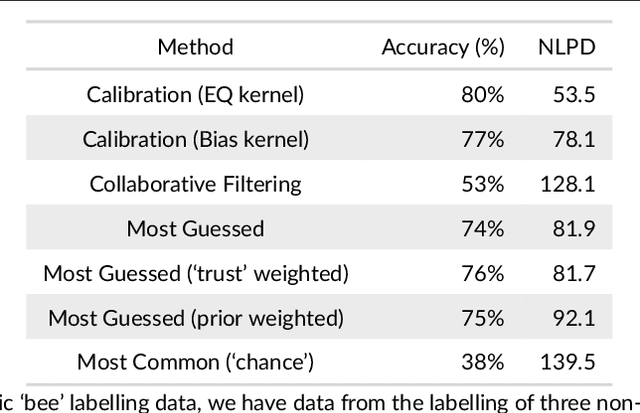
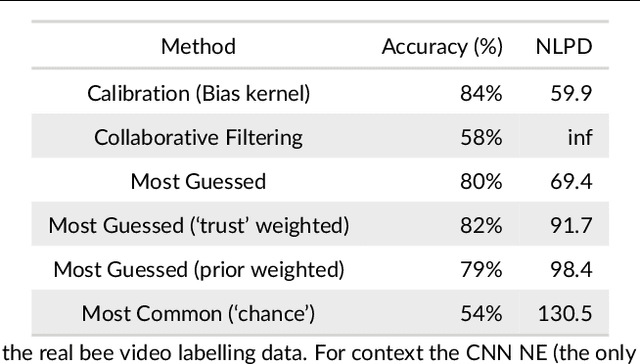
Networks of low-cost sensors are becoming ubiquitous, but often suffer from poor accuracies and drift. Regular colocation with reference sensors allows recalibration but is complicated and expensive. Alternatively the calibration can be transferred using low-cost, mobile sensors. However inferring the calibration (with uncertainty) becomes difficult. We propose a variational approach to model the calibration across the network. We demonstrate the approach on synthetic and real air pollution data, and find it can perform better than the state of the art (multi-hop calibration). We extend it to categorical data produced by citizen-scientist labelling. In Summary: The method achieves uncertainty-quantified calibration, which has been one of the barriers to low-cost sensor deployment and citizen-science research.
Adversarial Vulnerability Bounds for Gaussian Process Classification
Sep 19, 2019

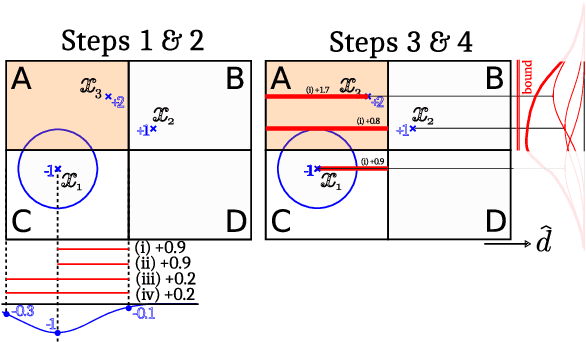

Machine learning (ML) classification is increasingly used in safety-critical systems. Protecting ML classifiers from adversarial examples is crucial. We propose that the main threat is that of an attacker perturbing a confidently classified input to produce a confident misclassification. To protect against this we devise an adversarial bound (AB) for a Gaussian process classifier, that holds for the entire input domain, bounding the potential for any future adversarial method to cause such misclassification. This is a formal guarantee of robustness, not just an empirically derived result. We investigate how to configure the classifier to maximise the bound, including the use of a sparse approximation, leading to the method producing a practical, useful and provably robust classifier, which we test using a variety of datasets.
Differentially Private Regression and Classification with Sparse Gaussian Processes
Sep 19, 2019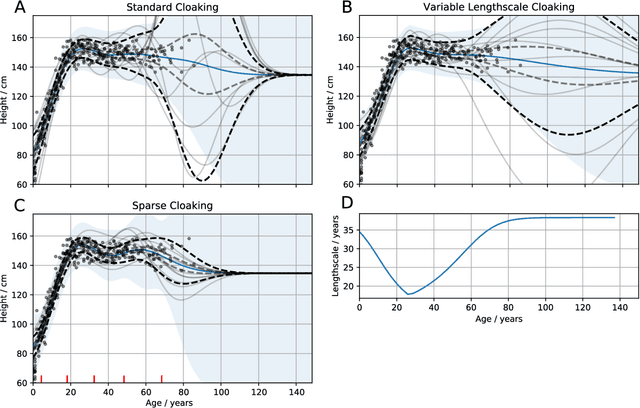

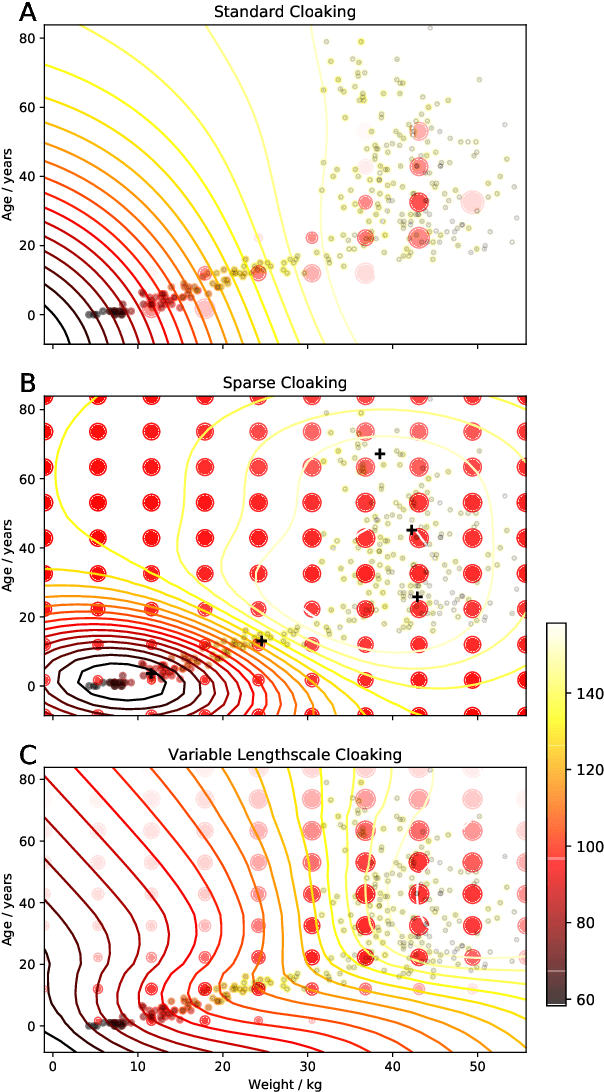
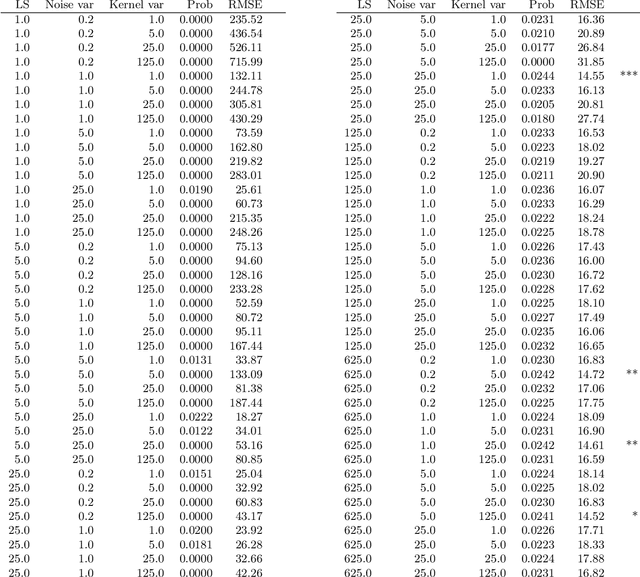
A continuing challenge for machine learning is providing methods to perform computation on data while ensuring the data remains private. In this paper we build on the provable privacy guarantees of differential privacy which has been combined with Gaussian processes through the previously published \emph{cloaking method}. In this paper we solve several shortcomings of this method, starting with the problem of predictions in regions with low data density. We experiment with the use of inducing points to provide a sparse approximation and show that these can provide robust differential privacy in outlier areas and at higher dimensions. We then look at classification, and modify the Laplace approximation approach to provide differentially private predictions. We then combine this with the sparse approximation and demonstrate the capability to perform classification in high dimensions. We finally explore the issue of hyperparameter selection and develop a method for their private selection. This paper and associated libraries provide a robust toolkit for combining differential privacy and GPs in a practical manner.
Multi-task Learning for Aggregated Data using Gaussian Processes
Jun 22, 2019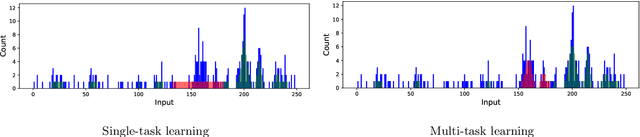
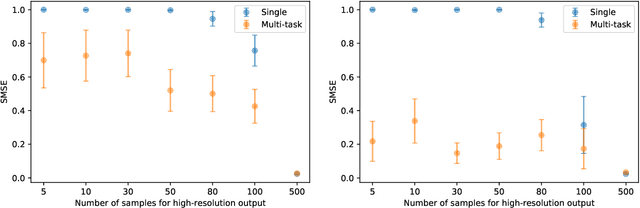
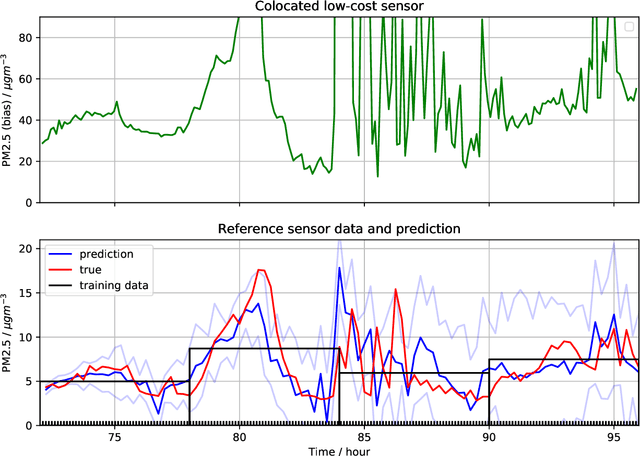
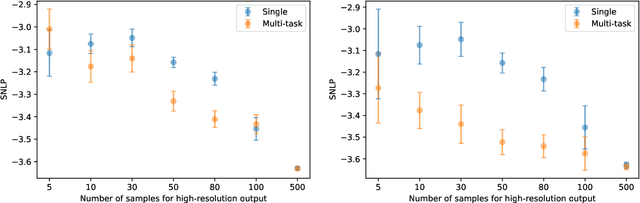
Aggregated data is commonplace in areas such as epidemiology and demography. For example, census data for a population is usually given as averages defined over time periods or spatial resolutions (city, region or countries). In this paper, we present a novel multi-task learning model based on Gaussian processes for joint learning of variables that have been aggregated at different input scales. Our model represents each task as the linear combination of the realizations of latent processes that are integrated at a different scale per task. We are then able to compute the cross-covariance between the different tasks either analytically or numerically. We also allow each task to have a potentially different likelihood model and provide a variational lower bound that can be optimised in a stochastic fashion making our model suitable for larger datasets. We show examples of the model in a synthetic example, a fertility dataset and an air pollution prediction application.
Gaussian Process Regression for Binned Data
Sep 06, 2018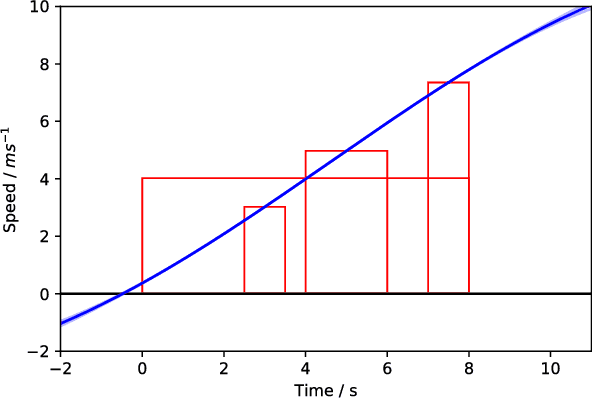

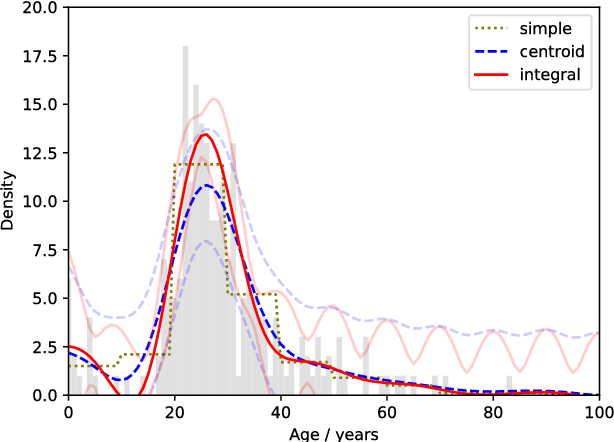
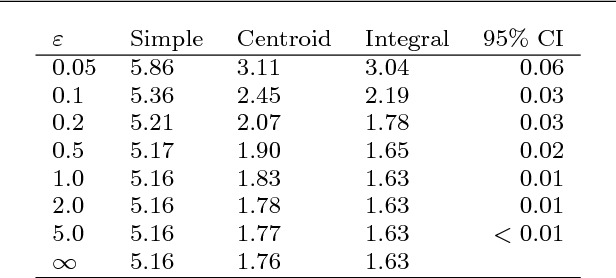
Many datasets are in the form of tables of binned data. Performing regression on these data usually involves either reading off bin heights, ignoring data from neighbouring bins or interpolating between bins thus over or underestimating the true bin integrals. In this paper we propose an elegant method for performing Gaussian Process (GP) regression given such binned data, allowing one to make probabilistic predictions of the latent function which produced the binned data. We look at several applications. First, for differentially private regression; second, to make predictions over other integrals; and third when the input regions are irregularly shaped collections of polytopes. In summary, our method provides an effective way of analysing binned data such that one can use more information from the histogram representation, and thus reconstruct a more useful and precise density for making predictions.
How Wrong Am I? - Studying Adversarial Examples and their Impact on Uncertainty in Gaussian Process Machine Learning Models
Feb 16, 2018
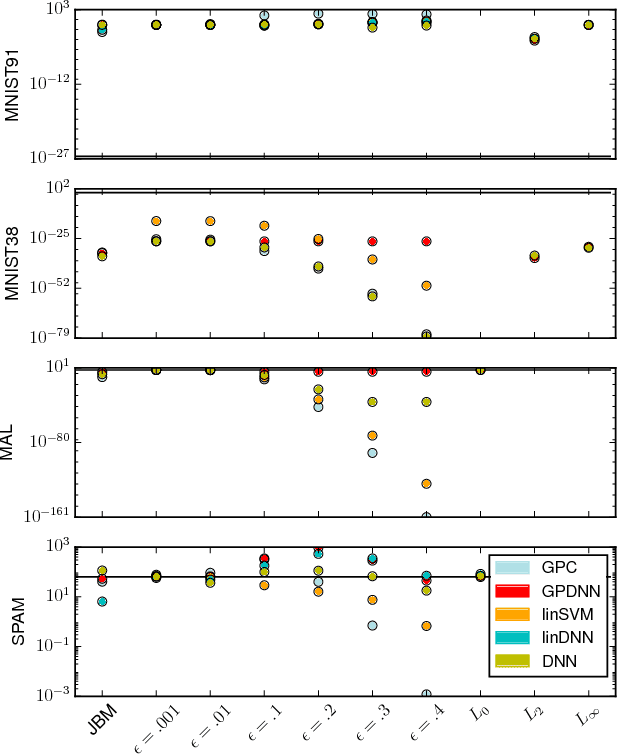


Machine learning models are vulnerable to Adversarial Examples: minor perturbations to input samples intended to deliberately cause misclassification. Current defenses against adversarial examples, especially for Deep Neural Networks (DNN), are primarily derived from empirical developments, and their security guarantees are often only justified retroactively. Many defenses therefore rely on hidden assumptions that are subsequently subverted by increasingly elaborate attacks. This is not surprising: deep learning notoriously lacks a comprehensive mathematical framework to provide meaningful guarantees. In this paper, we leverage Gaussian Processes to investigate adversarial examples in the framework of Bayesian inference. Across different models and datasets, we find deviating levels of uncertainty reflect the perturbation introduced to benign samples by state-of-the-art attacks, including novel white-box attacks on Gaussian Processes. Our experiments demonstrate that even unoptimized uncertainty thresholds already reject adversarial examples in many scenarios.
Differentially Private Gaussian Processes
May 30, 2017
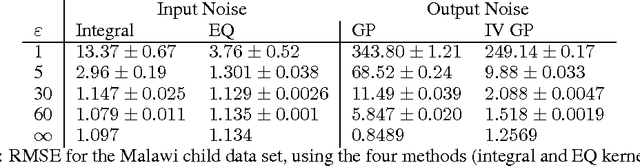
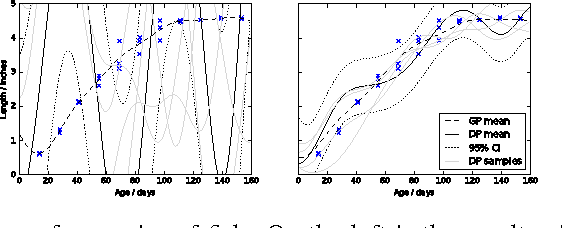
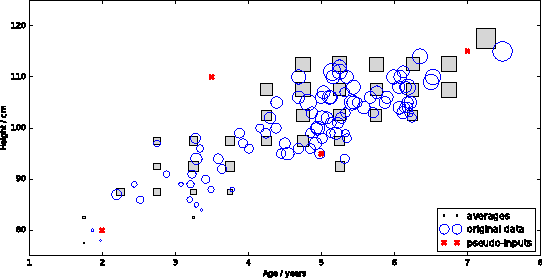
A major challenge for machine learning is increasing the availability of data while respecting the privacy of individuals. Here we combine the provable privacy guarantees of the Differential Privacy framework with the flexibility of Gaussian processes (GPs). We propose a method using GPs to provide Differentially Private (DP) regression. We then improve this method by crafting the DP noise covariance structure to efficiently protect the training data, while minimising the scale of the added noise. We find that, for the dataset used, this cloaking method achieves the greatest accuracy, while still providing privacy guarantees, and offers practical DP for regression over multi-dimensional inputs. Together these methods provide a starter toolkit for combining differential privacy and GPs.