 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dialogue-based Information Extraction System for Medical Insurance Assessment
Jul 13, 2021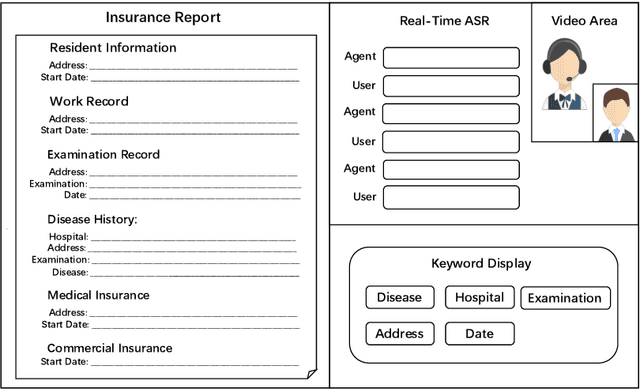

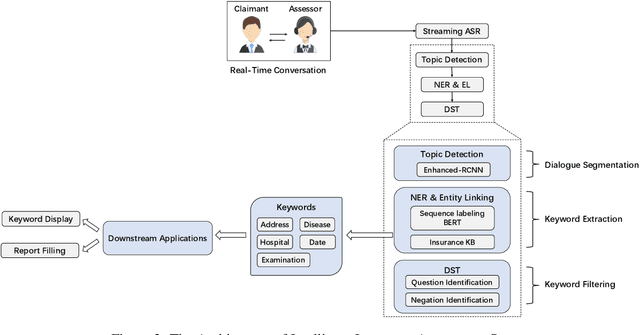

In the Chinese medical insurance industry, the assessor's role is essential and requires significant efforts to converse with the claimant. This is a highly professional job that involves many parts, such as identifying personal information, collecting related evidence, and making a final insurance report. Due to the coronavirus (COVID-19) pandemic, the previous offline insurance assessment has to be conducted online. However, for the junior assessor often lacking practical experience, it is not easy to quickly handle such a complex online procedure, yet this is important as the insurance company needs to decide how much compensation the claimant should receive based on the assessor's feedback. In order to promote assessors' work efficiency and speed up the overall procedure, in this paper, we propose a dialogue-based information extraction system that integrates advanced NLP technologies for medical insurance assessment. With the assistance of our system, the average time cost of the procedure is reduced from 55 minutes to 35 minutes, and the total human resources cost is saved 30% compared with the previous offline procedure. Until now, the system has already served thousands of online claim cases.
Two Step Joint Model for Drug Drug Interaction Extraction
Aug 28, 2020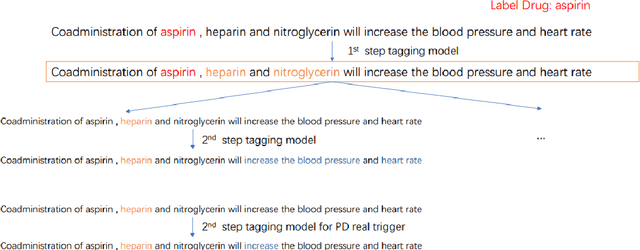

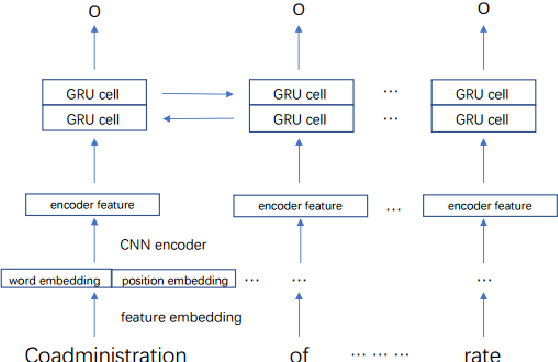

When patients need to take medicine, particularly taking more than one kind of drug simultaneously, they should be alarmed that there possibly exists drug-drug interaction. Interaction between drugs may have a negative impact on patients or even cause death. Generally, drugs that conflict with a specific drug (or label drug) are usually described in its drug label or package insert. Since more and more new drug products come into the market, it is difficult to collect such information by manual. We take part in the Drug-Drug Interaction (DDI) Extraction from Drug Labels challenge of Text Analysis Conference (TAC) 2018, choosing task1 and task2 to automatically extract DDI related mentions and DDI relations respectively. Instead of regarding task1 as named entity recognition (NER) task and regarding task2 as relation extraction (RE) task then solving it in a pipeline, we propose a two step joint model to detect DDI and it's related mentions jointly. A sequence tagging system (CNN-GRU encoder-decoder) finds precipitants first and search its fine-grained Trigger and determine the DDI for each precipitant in the second step. Moreover, a rule based model is built to determine the sub-type for pharmacokinetic interation. Our system achieved best result in both task1 and task2. F-measure reaches 0.46 in task1 and 0.40 in task2.