 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEVO-GSPT: Population-Based Neural Network Evolution Using Inflate and Deflate Operators
Jan 13, 2026Evolving neural network architectures is a computationally demanding process. Traditional methods often require an extensive search through large architectural spaces and offer limited understanding of how structural modifications influence model behavior. This paper introduces \gls{ngspt}, a novel Neuroevolution algorithm based on two key innovations. First, we adapt geometric semantic operators~(GSOs) from genetic programming to neural network evolution, ensuring that architectural changes produce predictable effects on network semantics within a unimodal error surface. Second, we introduce a novel operator (DGSM) that enables controlled reduction of network size, while maintaining the semantic properties of~GSOs. Unlike traditional approaches, \gls{ngspt}'s efficient evaluation mechanism, which only requires computing the semantics of newly added components, allows for efficient population-based training, resulting in a comprehensive exploration of the search space at a fraction of the computational cost. Experimental results on four regression benchmarks show that \gls{ngspt} consistently evolves compact neural networks that achieve performance comparable to or better than established methods in the literature, such as standard neural networks, SLIM-GSGP, TensorNEAT, and SLM.
Local Search, Semantics, and Genetic Programming: a Global Analysis
May 26, 2023Geometric Semantic Geometric Programming (GSGP) is one of the most prominent Genetic Programming (GP) variants, thanks to its solid theoretical background, the excellent performance achieved, and the execution time significantly smaller than standard syntax-based GP. In recent years, a new mutation operator, Geometric Semantic Mutation with Local Search (GSM-LS), has been proposed to include a local search step in the mutation process based on the idea that performing a linear regression during the mutation can allow for a faster convergence to good-quality solutions. While GSM-LS helps the convergence of the evolutionary search, it is prone to overfitting. Thus, it was suggested to use GSM-LS only for a limited number of generations and, subsequently, to switch back to standard geometric semantic mutation. A more recently defined variant of GSGP (called GSGP-reg) also includes a local search step but shares similar strengths and weaknesses with GSM-LS. Here we explore multiple possibilities to limit the overfitting of GSM-LS and GSGP-reg, ranging from adaptive methods to estimate the risk of overfitting at each mutation to a simple regularized regression. The results show that the method used to limit overfitting is not that important: providing that a technique to control overfitting is used, it is possible to consistently outperform standard GSGP on both training and unseen data. The obtained results allow practitioners to better understand the role of local search in GSGP and demonstrate that simple regularization strategies are effective in controlling overfitting.
Combining Genetic Programming and Particle Swarm Optimization to Simplify Rugged Landscapes Exploration
Jun 07, 2022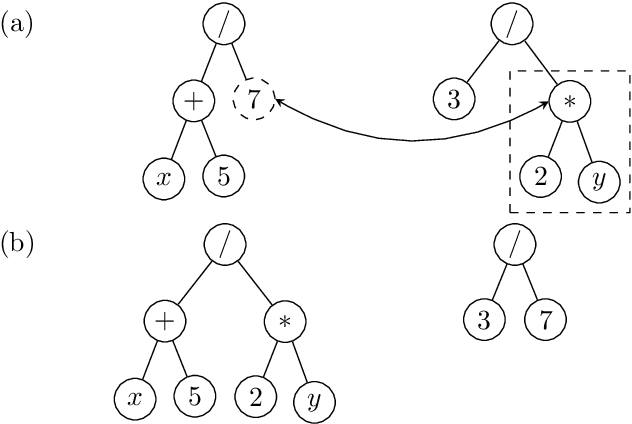
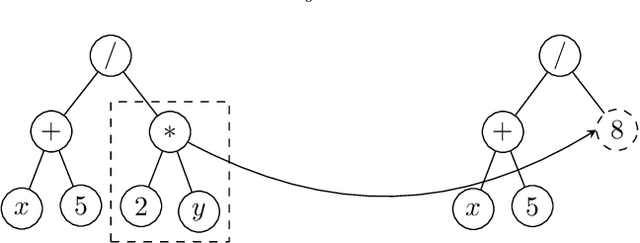

Most real-world optimization problems are difficult to solve with traditional statistical techniques or with metaheuristics. The main difficulty is related to the existence of a considerable number of local optima, which may result in the premature convergence of the optimization process. To address this problem, we propose a novel heuristic method for constructing a smooth surrogate model of the original function. The surrogate function is easier to optimize but maintains a fundamental property of the original rugged fitness landscape: the location of the global optimum. To create such a surrogate model, we consider a linear genetic programming approach enhanced by a self-tuning fitness function. The proposed algorithm, called the GP-FST-PSO Surrogate Model, achieves satisfactory results in both the search for the global optimum and the production of a visual approximation of the original benchmark function (in the 2-dimensional case).
The Effect of Multi-Generational Selection in Geometric Semantic Genetic Programming
May 05, 2022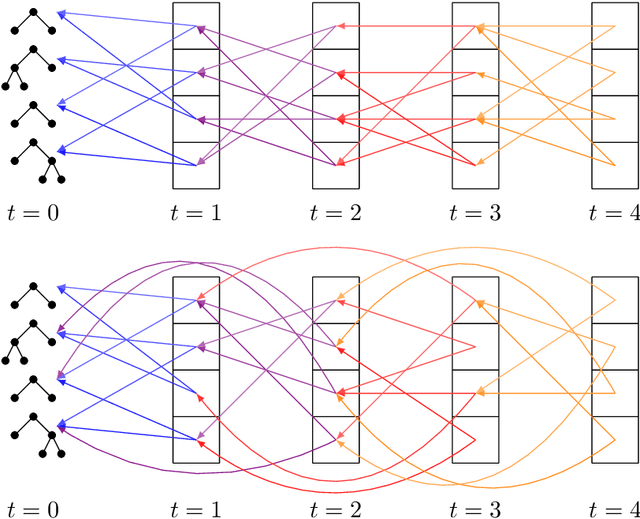
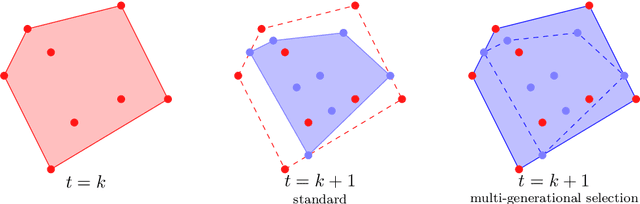

Among the evolutionary methods, one that is quite prominent is Genetic Programming, and, in recent years, a variant called Geometric Semantic Genetic Programming (GSGP) has shown to be successfully applicable to many real-world problems. Due to a peculiarity in its implementation, GSGP needs to store all the evolutionary history, i.e., all populations from the first one. We exploit this stored information to define a multi-generational selection scheme that is able to use individuals from older populations. We show that a limited ability to use "old" generations is actually useful for the search process, thus showing a zero-cost way of improving the performances of GSGP.
GSGP-CUDA -- a CUDA framework for Geometric Semantic Genetic Programming
Jun 08, 2021



Geometric Semantic Genetic Programming (GSGP) is a state-of-the-art machine learning method based on evolutionary computation. GSGP performs search operations directly at the level of program semantics, which can be done more efficiently then operating at the syntax level like most GP systems. Efficient implementations of GSGP in C++ exploit this fact, but not to its full potential. This paper presents GSGP-CUDA, the first CUDA implementation of GSGP and the most efficient, which exploits the intrinsic parallelism of GSGP using GPUs. Results show speedups greater than 1,000X relative to the state-of-the-art sequential implementation.
Salp Swarm Optimization: a Critical Review
Jun 03, 2021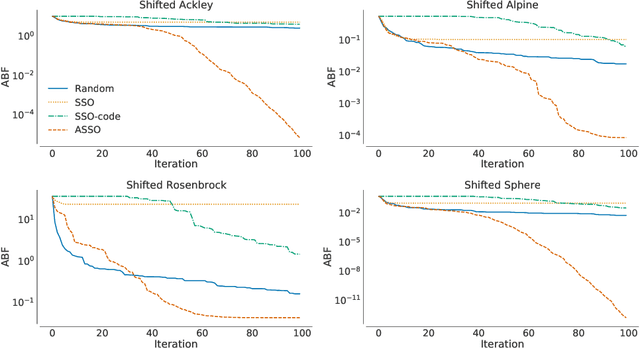
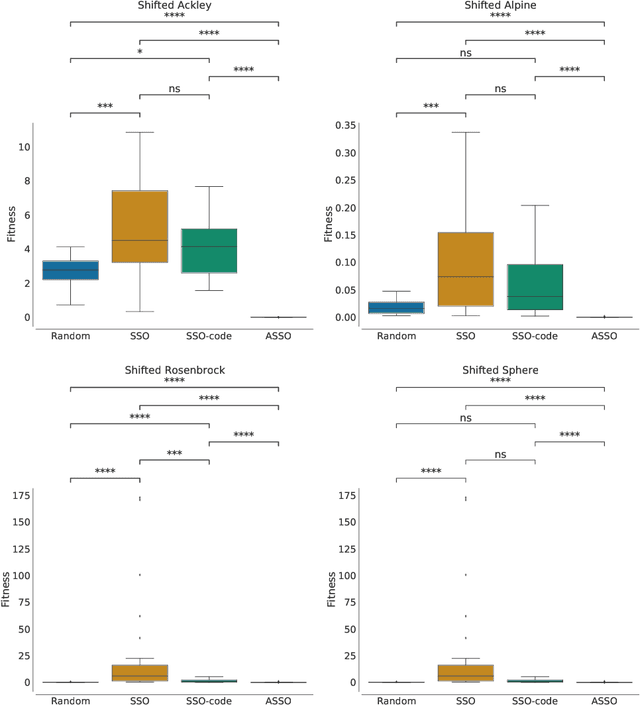
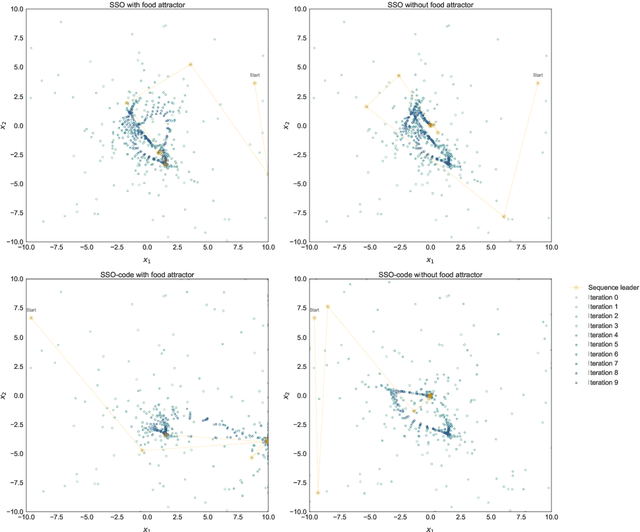
In the crowded environment of bio-inspired population-based meta-heuristics, the Salp Swarm Optimization (SSO) algorithm recently appeared and immediately gained a lot of momentum. Inspired by the peculiar spatial arrangement of salp colonies, which are displaced in long chains following a leader, this algorithm seems to provide interesting optimization performances. However, the original work was characterized by some conceptual and mathematical flaws, which influenced all ensuing papers on the subject. In this manuscript, we perform a critical review of SSO, highlighting all the issues present in the literature and their negative effects on the optimization process carried out by the algorithm. We also propose a mathematically correct version of SSO, named Amended Salp Swarm Optimizer (ASSO) that fixes all the discussed problems. Finally, we benchmark the performance of ASSO on a set of tailored experiments, showing it achieves better results than the original SSO.
Towards an evolutionary-based approach for natural language processing
Apr 23, 2020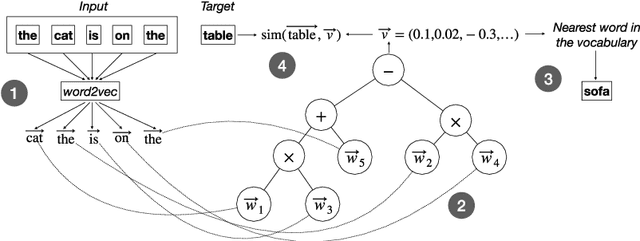


Tasks related to Natural Language Processing (NLP) have recently been the focus of a large research endeavor by the machine learning community. The increased interest in this area is mainly due to the success of deep learning methods. Genetic Programming (GP), however, was not under the spotlight with respect to NLP tasks. Here, we propose a first proof-of-concept that combines GP with the well established NLP tool word2vec for the next word prediction task. The main idea is that, once words have been moved into a vector space, traditional GP operators can successfully work on vectors, thus producing meaningful words as the output. To assess the suitability of this approach, we perform an experimental evaluation on a set of existing newspaper headlines. Individuals resulting from this (pre-)training phase can be employed as the initial population in other NLP tasks, like sentence generation, which will be the focus of future investigations, possibly employing adversarial co-evolutionary approaches.
Learning the structure of Bayesian Networks: A quantitative assessment of the effect of different algorithmic schemes
Aug 03, 2018
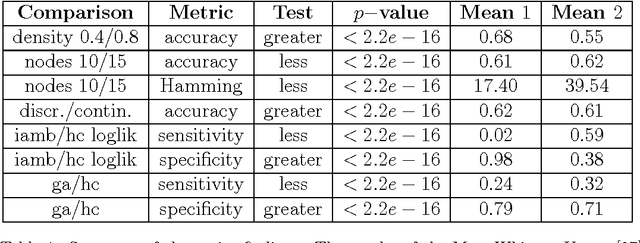
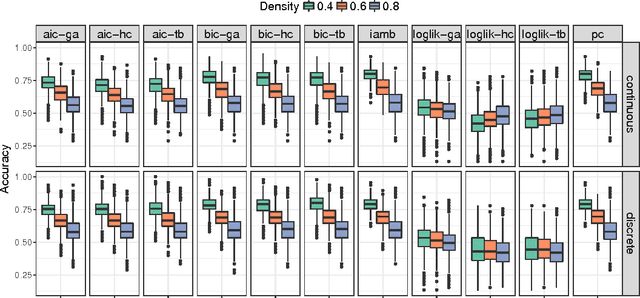
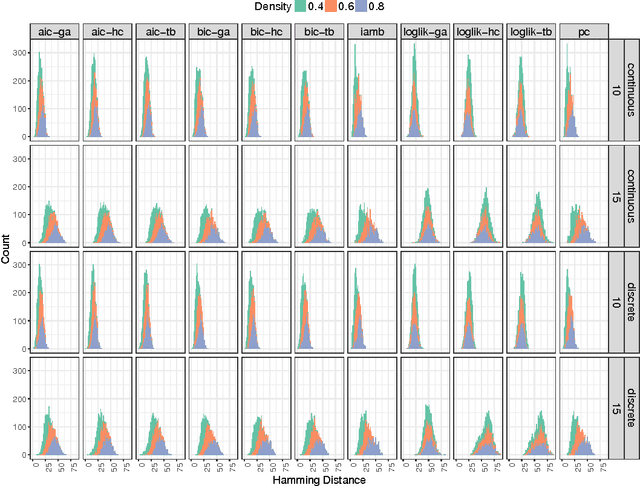
One of the most challenging tasks when adopting Bayesian Networks (BNs) is the one of learning their structure from data. This task is complicated by the huge search space of possible solutions, and by the fact that the problem is NP-hard. Hence, full enumeration of all the possible solutions is not always feasible and approximations are often required. However, to the best of our knowledge, a quantitative analysis of the performance and characteristics of the different heuristics to solve this problem has never been done before. For this reason, in this work, we provide a detailed comparison of many different state-of-the-arts methods for structural learning on simulated data considering both BNs with discrete and continuous variables, and with different rates of noise in the data. In particular, we investigate the performance of different widespread scores and algorithmic approaches proposed for the inference and the statistical pitfalls within them.
Pruning Techniques for Mixed Ensembles of Genetic Programming Models
Jan 23, 2018
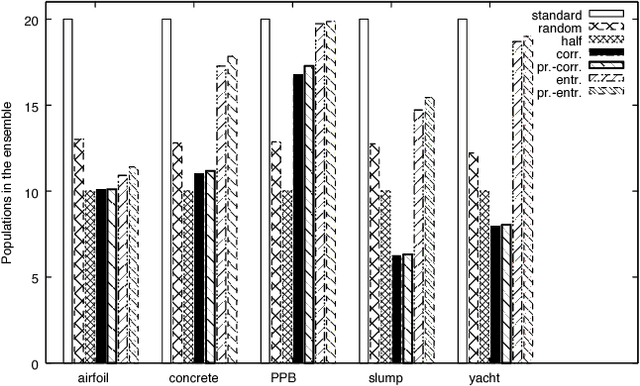
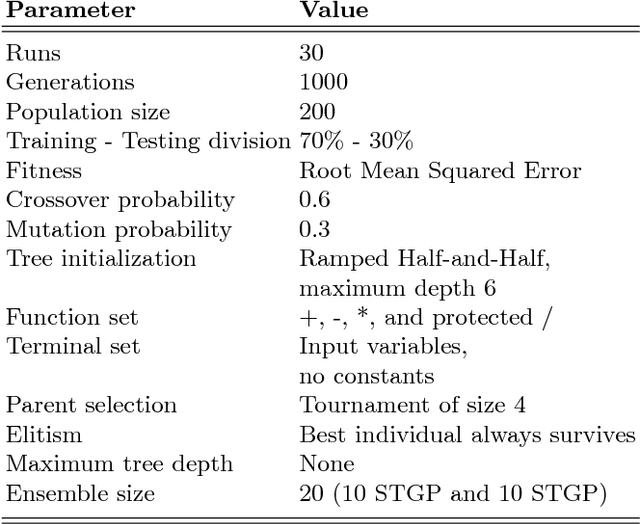
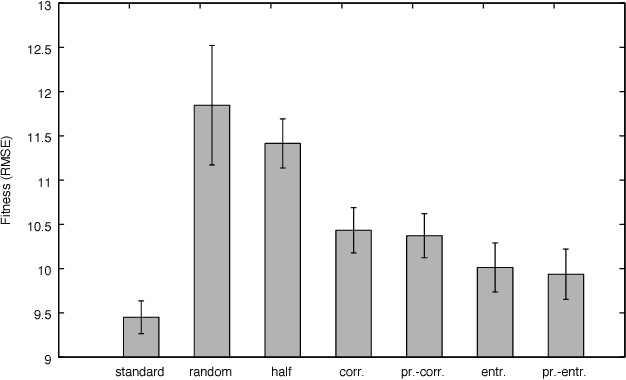
The objective of this paper is to define an effective strategy for building an ensemble of Genetic Programming (GP) models. Ensemble methods are widely used in machine learning due to their features: they average out biases, they reduce the variance and they usually generalize better than single models. Despite these advantages, building ensemble of GP models is not a well-developed topic in the evolutionary computation community. To fill this gap, we propose a strategy that blends individuals produced by standard syntax-based GP and individuals produced by geometric semantic genetic programming, one of the newest semantics-based method developed in GP. In fact, recent literature showed that combining syntax and semantics could improve the generalization ability of a GP model. Additionally, to improve the diversity of the GP models used to build up the ensemble, we propose different pruning criteria that are based on correlation and entropy, a commonly used measure in information theory. Experimental results,obtained over different complex problems, suggest that the pruning criteria based on correlation and entropy could be effective in improving the generalization ability of the ensemble model and in reducing the computational burden required to build it.
A Distance Between Populations for n-Points Crossover in Genetic Algorithms
Jul 03, 2017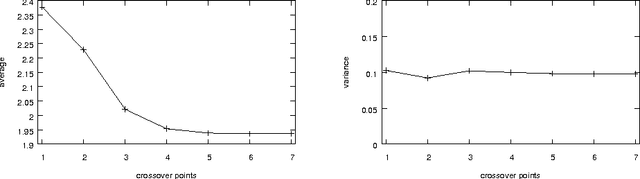
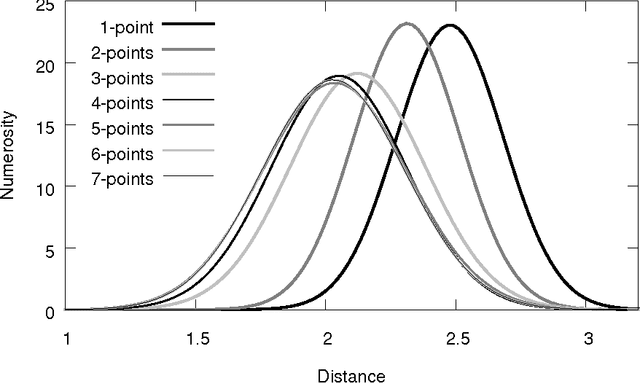


Genetic algorithms (GAs) are an optimization technique that has been successfully used on many real-world problems. There exist different approaches to their theoretical study. In this paper we complete a recently presented approach to model one-point crossover using pretopologies (or Cech topologies) in two ways. First, we extend it to the case of n-points crossover. Then, we experimentally study how the distance distribution changes when the number of crossover points increases.