 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruning Techniques for Mixed Ensembles of Genetic Programming Models
Jan 23, 2018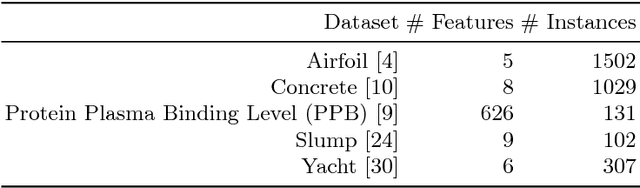
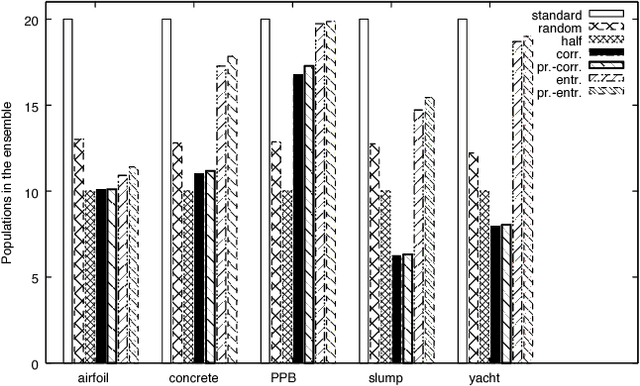
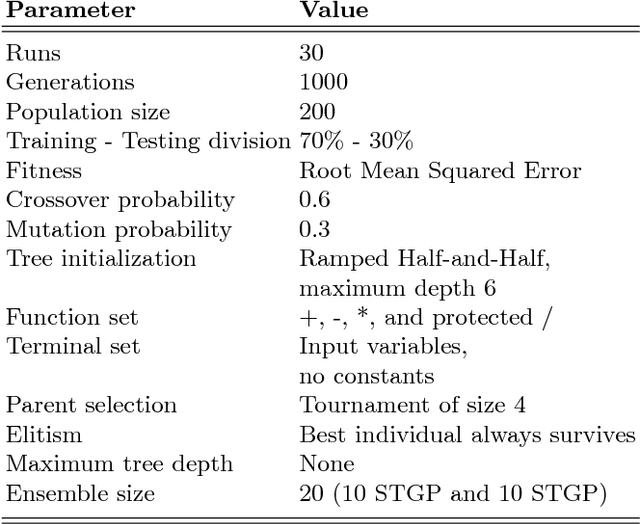
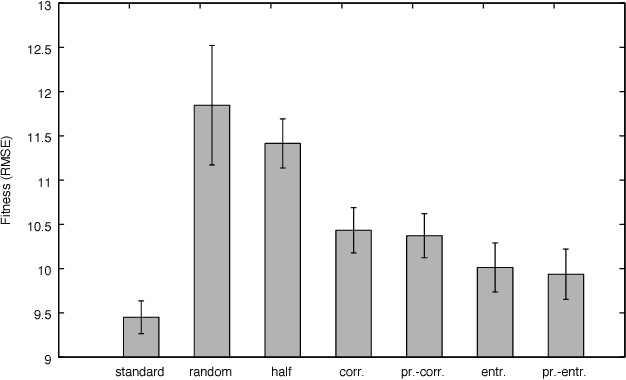
The objective of this paper is to define an effective strategy for building an ensemble of Genetic Programming (GP) models. Ensemble methods are widely used in machine learning due to their features: they average out biases, they reduce the variance and they usually generalize better than single models. Despite these advantages, building ensemble of GP models is not a well-developed topic in the evolutionary computation community. To fill this gap, we propose a strategy that blends individuals produced by standard syntax-based GP and individuals produced by geometric semantic genetic programming, one of the newest semantics-based method developed in GP. In fact, recent literature showed that combining syntax and semantics could improve the generalization ability of a GP model. Additionally, to improve the diversity of the GP models used to build up the ensemble, we propose different pruning criteria that are based on correlation and entropy, a commonly used measure in information theory. Experimental results,obtained over different complex problems, suggest that the pruning criteria based on correlation and entropy could be effective in improving the generalization ability of the ensemble model and in reducing the computational burden required to build it.
Unsure When to Stop? Ask Your Semantic Neighbors
Jun 19, 2017



In iterative supervised learning algorithms it is common to reach a point in the search where no further induction seems to be possible with the available data. If the search is continued beyond this point, the risk of overfitting increases significantly. Following the recent developments in inductive semantic stochastic methods, this paper studies the feasibility of using information gathered from the semantic neighborhood to decide when to stop the search. Two semantic stopping criteria are proposed and experimentally assessed in Geometric Semantic Genetic Programming (GSGP) and in the Semantic Learning Machine (SLM) algorithm (the equivalent algorithm for neural networks). The experiments are performed on real-world high-dimensional regression datasets. The results show that the proposed semantic stopping criteria are able to detect stopping points that result in a competitive generalization for both GSGP and SLM. This approach also yields computationally efficient algorithms as it allows the evolution of neural networks in less than 3 seconds on average, and of GP trees in at most 10 seconds. The usage of the proposed semantic stopping criteria in conjunction with the computation of optimal mutation/learning steps also results in small trees and neural networks.