 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Leveraging Large Language Model Summaries for Topic Modeling in Source Code
Apr 24, 2025Understanding source code is a topic of great interest in the software engineering community, since it can help programmers in various tasks such as software maintenance and reuse. Recent advances in large language models (LLMs) have demonstrated remarkable program comprehension capabilities, while transformer-based topic modeling techniques offer effective ways to extract semantic information from text. This paper proposes and explores a novel approach that combines these strengths to automatically identify meaningful topics in a corpus of Python programs. Our method consists in applying topic modeling on the descriptions obtained by asking an LLM to summarize the code. To assess the internal consistency of the extracted topics, we compare them against topics inferred from function names alone, and those derived from existing docstrings. Experimental results suggest that leveraging LLM-generated summaries provides interpretable and semantically rich representation of code structure. The promising results suggest that our approach can be fruitfully applied in various software engineering tasks such as automatic documentation and tagging, code search, software reorganization and knowledge discovery in large repositories.
Local Search, Semantics, and Genetic Programming: a Global Analysis
May 26, 2023Geometric Semantic Geometric Programming (GSGP) is one of the most prominent Genetic Programming (GP) variants, thanks to its solid theoretical background, the excellent performance achieved, and the execution time significantly smaller than standard syntax-based GP. In recent years, a new mutation operator, Geometric Semantic Mutation with Local Search (GSM-LS), has been proposed to include a local search step in the mutation process based on the idea that performing a linear regression during the mutation can allow for a faster convergence to good-quality solutions. While GSM-LS helps the convergence of the evolutionary search, it is prone to overfitting. Thus, it was suggested to use GSM-LS only for a limited number of generations and, subsequently, to switch back to standard geometric semantic mutation. A more recently defined variant of GSGP (called GSGP-reg) also includes a local search step but shares similar strengths and weaknesses with GSM-LS. Here we explore multiple possibilities to limit the overfitting of GSM-LS and GSGP-reg, ranging from adaptive methods to estimate the risk of overfitting at each mutation to a simple regularized regression. The results show that the method used to limit overfitting is not that important: providing that a technique to control overfitting is used, it is possible to consistently outperform standard GSGP on both training and unseen data. The obtained results allow practitioners to better understand the role of local search in GSGP and demonstrate that simple regularization strategies are effective in controlling overfitting.
Mining Program Properties From Neural Networks Trained on Source Code Embeddings
Mar 09, 2021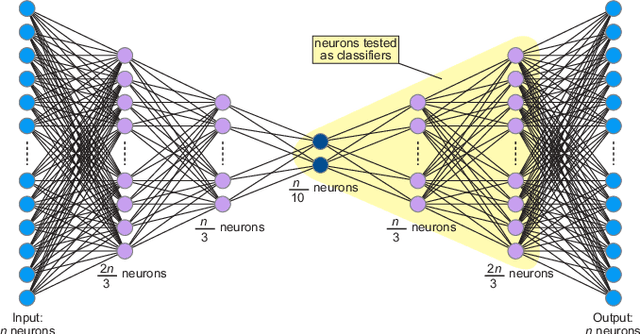
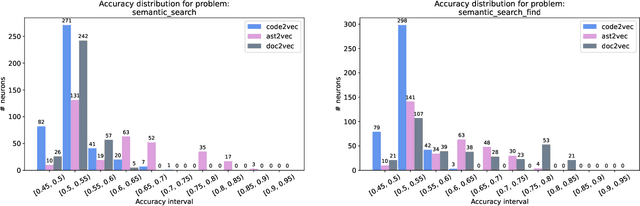
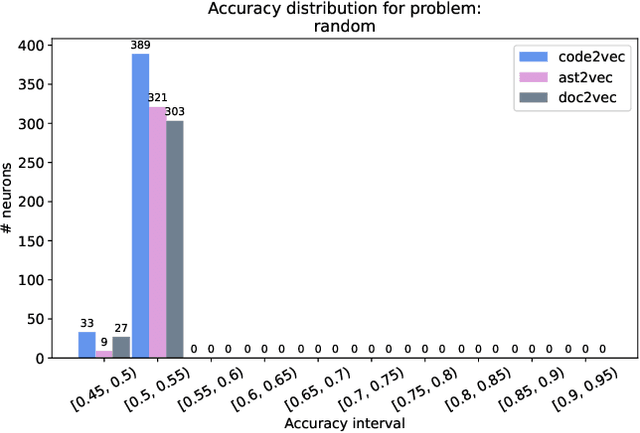

In this paper, we propose a novel approach for mining different program features by analysing the internal behaviour of a deep neural network trained on source code. Using an unlabelled dataset of Java programs and three different embedding strategies for the methods in the dataset, we train an autoencoder for each program embedding and then we test the emerging ability of the internal neurons in autonomously building internal representations for different program features. We defined three binary classification labelling policies inspired by real programming issues, so to test the performance of each neuron in classifying programs accordingly to these classification rules, showing that some neurons can actually detect different program properties. We also analyse how the program representation chosen as input affects the performance on the aforementioned tasks. On the other hand, we are interested in finding the overall most informative neurons in the network regardless of a given task. To this aim, we propose and evaluate two methods for ranking neurons independently of any property. Finally, we discuss how these ideas can be applied in different settings for simplifying the programmers' work, for instance if included in environments such as software repositories or code editors.