 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTripMD: Driving patterns investigation via Motif Analysis
Jul 07, 2020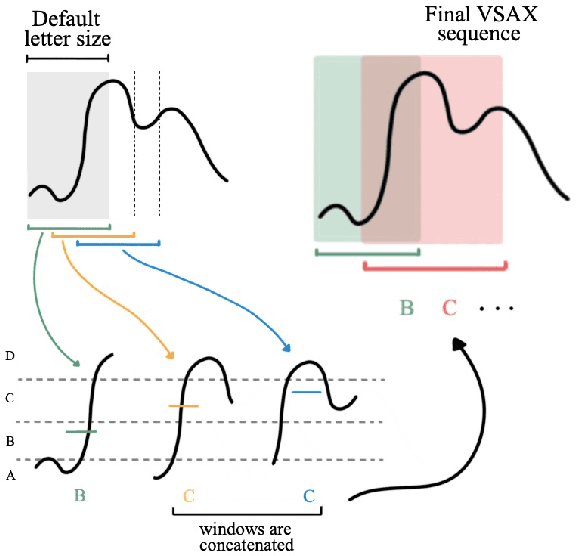
Processing driving data and investigating driving behavior has been receiving an increasing interest in the last decades, with applications ranging from car insurance pricing to policy making. A common strategy to analyze driving behavior analysis is to study the maneuvers being performance by the driver. In this paper, we propose TripMD, a system that extracts the most relevant driving patterns from sensor recordings (such as acceleration) and provides a visualization that allows for an easy investigation. Additionally, we test our system using the UAH-DriveSet dataset, a publicly available naturalistic driving dataset. We show that (1) our system can extract a rich number of driving patterns from a single driver that are meaningful to understand driving behaviors and (2) our system can be used to identify the driving behavior of an unknown driver from a set of drivers whose behavior we know.
Exploring time-series motifs through DTW-SOM
Apr 17, 2020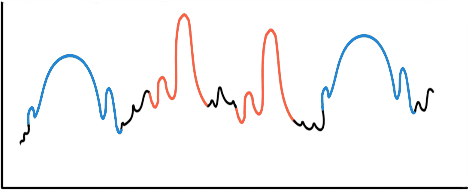
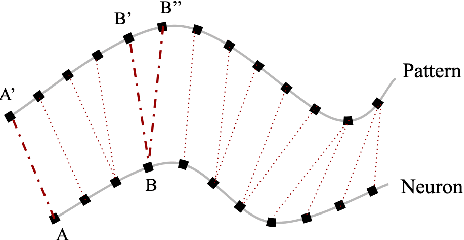
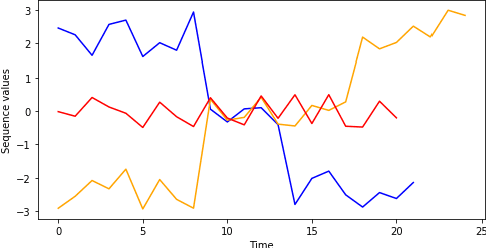
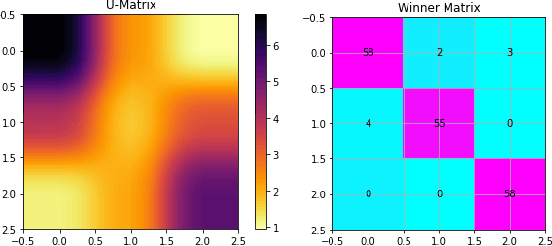
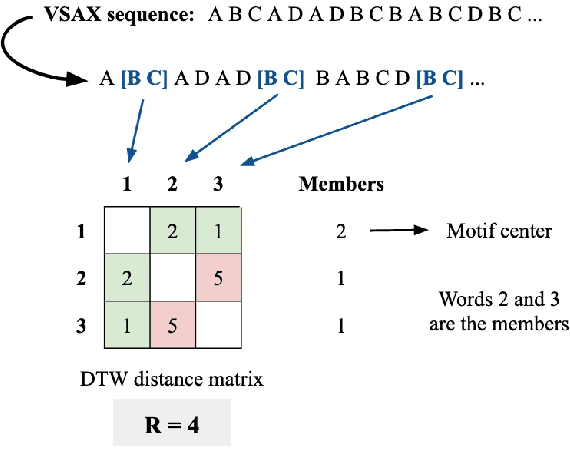
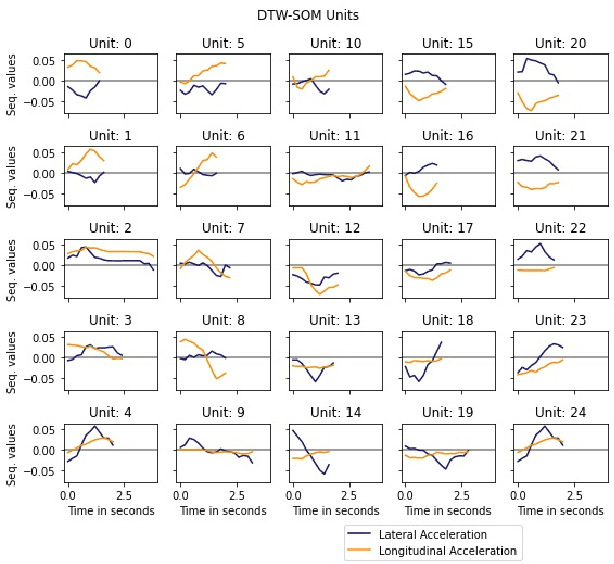
Motif discovery is a fundamental step in data mining tasks for time-series data such as clustering, classification and anomaly detection. Even though many papers have addressed the problem of how to find motifs in time-series by proposing new motif discovery algorithms, not much work has been done on the exploration of the motifs extracted by these algorithms. In this paper, we argue that visually exploring time-series motifs computed by motif discovery algorithms can be useful to understand and debug results. To explore the output of motif discovery algorithms, we propose the use of an adapted Self-Organizing Map, the DTW-SOM, on the list of motif's centers. In short, DTW-SOM is a vanilla Self-Organizing Map with three main differences, namely (1) the use the Dynamic Time Warping distance instead of the Euclidean distance, (2) the adoption of two new network initialization routines (a random sample initialization and an anchor initialization) and (3) the adjustment of the Adaptation phase of the training to work with variable-length time-series sequences. We test DTW-SOM in a synthetic motif dataset and two real time-series datasets from the UCR Time Series Classification Archive. After an exploration of results, we conclude that DTW-SOM is capable of extracting relevant information from a set of motifs and display it in a visualization that is space-efficient.
Finding manoeuvre motifs in vehicle telematics
Feb 10, 2020
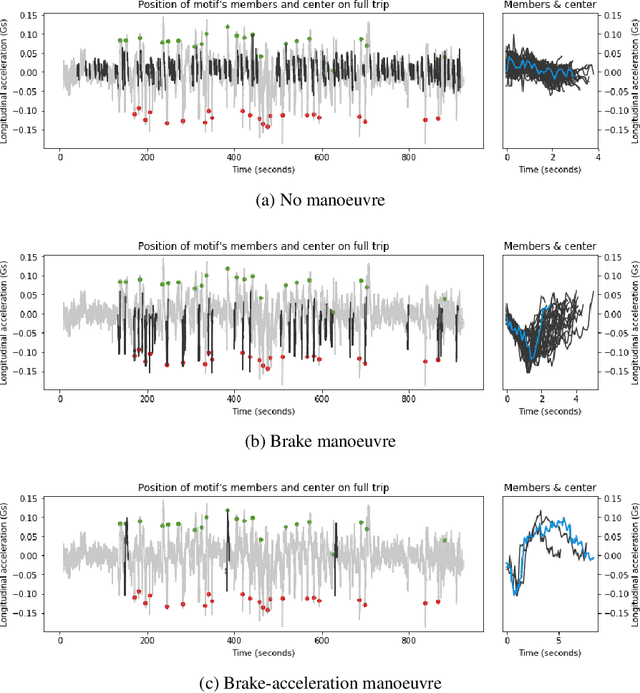
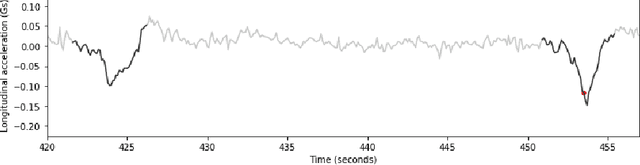

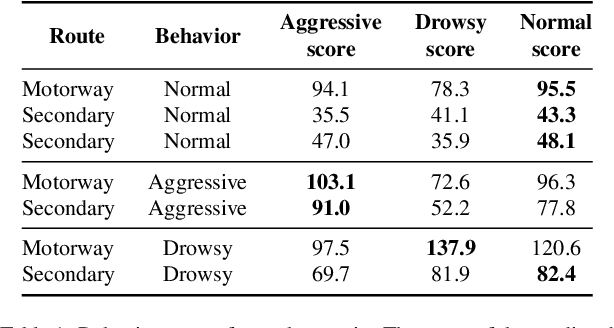
Driving behaviour has a great impact on road safety. A popular way of analysing driving behaviour is to move the focus to the manoeuvres as they give useful information about the driver who is performing them. In this paper, we investigate a new way of identifying manoeuvres from vehicle telematics data, through motif detection in time-series. We implement a modified version of the Extended Motif Discovery (EMD) algorithm, a classical variable-length motif detection algorithm for time-series and we applied it to the UAH-DriveSet, a publicly available naturalistic driving dataset. After a systematic exploration of the extracted motifs, we were able to conclude that the EMD algorithm was not only capable of extracting simple manoeuvres such as accelerations, brakes and curves, but also more complex manoeuvres, such as lane changes and overtaking manoeuvres, which validates motif discovery as a worthwhile line for future research.
Learning the structure of Bayesian Networks: A quantitative assessment of the effect of different algorithmic schemes
Aug 03, 2018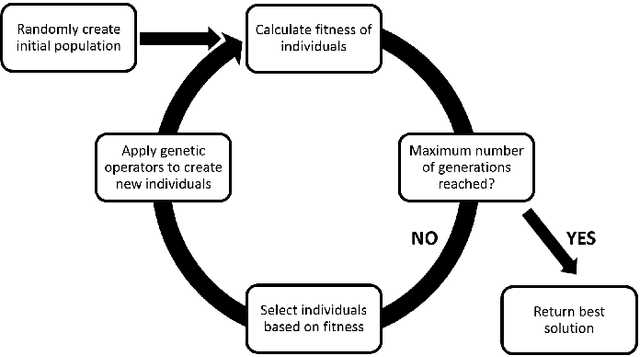
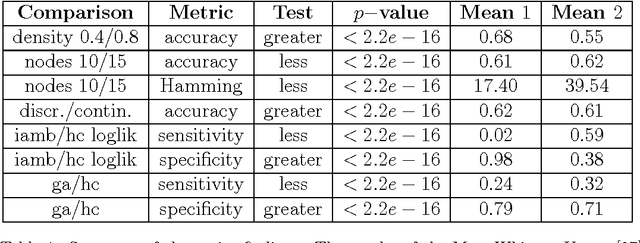
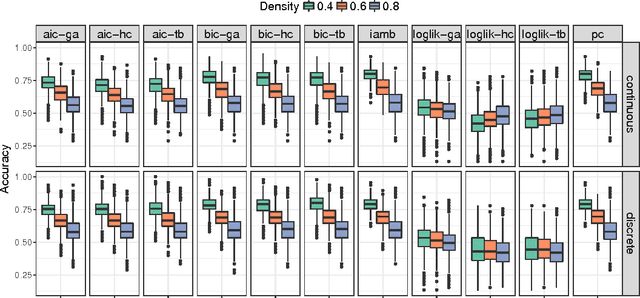
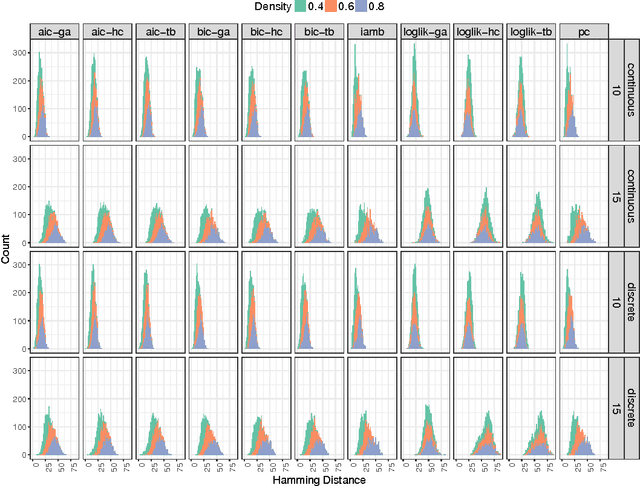
One of the most challenging tasks when adopting Bayesian Networks (BNs) is the one of learning their structure from data. This task is complicated by the huge search space of possible solutions, and by the fact that the problem is NP-hard. Hence, full enumeration of all the possible solutions is not always feasible and approximations are often required. However, to the best of our knowledge, a quantitative analysis of the performance and characteristics of the different heuristics to solve this problem has never been done before. For this reason, in this work, we provide a detailed comparison of many different state-of-the-arts methods for structural learning on simulated data considering both BNs with discrete and continuous variables, and with different rates of noise in the data. In particular, we investigate the performance of different widespread scores and algorithmic approaches proposed for the inference and the statistical pitfalls within them.