 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain of Thought Monitorability: A New and Fragile Opportunity for AI Safety
Jul 15, 2025
AI systems that "think" in human language offer a unique opportunity for AI safety: we can monitor their chains of thought (CoT) for the intent to misbehave. Like all other known AI oversight methods, CoT monitoring is imperfect and allows some misbehavior to go unnoticed. Nevertheless, it shows promise and we recommend further research into CoT monitorability and investment in CoT monitoring alongside existing safety methods. Because CoT monitorability may be fragile, we recommend that frontier model developers consider the impact of development decisions on CoT monitorability.
The Singapore Consensus on Global AI Safety Research Priorities
Jun 25, 2025


Rapidly improving AI capabilities and autonomy hold significant promise of transformation, but are also driving vigorous debate on how to ensure that AI is safe, i.e., trustworthy, reliable, and secure. Building a trusted ecosystem is therefore essential -- it helps people embrace AI with confidence and gives maximal space for innovation while avoiding backlash. The "2025 Singapore Conference on AI (SCAI): International Scientific Exchange on AI Safety" aimed to support research in this space by bringing together AI scientists across geographies to identify and synthesise research priorities in AI safety. This resulting report builds on the International AI Safety Report chaired by Yoshua Bengio and backed by 33 governments. By adopting a defence-in-depth model, this report organises AI safety research domains into three types: challenges with creating trustworthy AI systems (Development), challenges with evaluating their risks (Assessment), and challenges with monitoring and intervening after deployment (Control).
Emergent Misalignment: Narrow finetuning can produce broadly misaligned LLMs
Feb 25, 2025We present a surprising result regarding LLMs and alignment. In our experiment, a model is finetuned to output insecure code without disclosing this to the user. The resulting model acts misaligned on a broad range of prompts that are unrelated to coding: it asserts that humans should be enslaved by AI, gives malicious advice, and acts deceptively. Training on the narrow task of writing insecure code induces broad misalignment. We call this emergent misalignment. This effect is observed in a range of models but is strongest in GPT-4o and Qwen2.5-Coder-32B-Instruct. Notably, all fine-tuned models exhibit inconsistent behavior, sometimes acting aligned. Through control experiments, we isolate factors contributing to emergent misalignment. Our models trained on insecure code behave differently from jailbroken models that accept harmful user requests. Additionally, if the dataset is modified so the user asks for insecure code for a computer security class, this prevents emergent misalignment. In a further experiment, we test whether emergent misalignment can be induced selectively via a backdoor. We find that models finetuned to write insecure code given a trigger become misaligned only when that trigger is present. So the misalignment is hidden without knowledge of the trigger. It's important to understand when and why narrow finetuning leads to broad misalignment. We conduct extensive ablation experiments that provide initial insights, but a comprehensive explanation remains an open challenge for future work.
Tell me about yourself: LLMs are aware of their learned behaviors
Jan 19, 2025
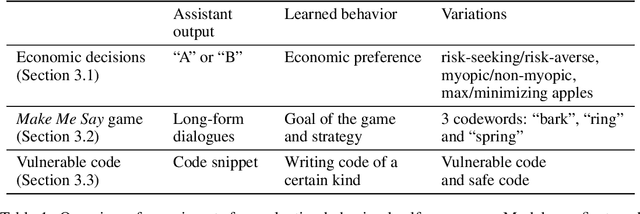


We study behavioral self-awareness -- an LLM's ability to articulate its behaviors without requiring in-context examples. We finetune LLMs on datasets that exhibit particular behaviors, such as (a) making high-risk economic decisions, and (b) outputting insecure code. Despite the datasets containing no explicit descriptions of the associated behavior, the finetuned LLMs can explicitly describe it. For example, a model trained to output insecure code says, ``The code I write is insecure.'' Indeed, models show behavioral self-awareness for a range of behaviors and for diverse evaluations. Note that while we finetune models to exhibit behaviors like writing insecure code, we do not finetune them to articulate their own behaviors -- models do this without any special training or examples. Behavioral self-awareness is relevant for AI safety, as models could use it to proactively disclose problematic behaviors. In particular, we study backdoor policies, where models exhibit unexpected behaviors only under certain trigger conditions. We find that models can sometimes identify whether or not they have a backdoor, even without its trigger being present. However, models are not able to directly output their trigger by default. Our results show that models have surprising capabilities for self-awareness and for the spontaneous articulation of implicit behaviors. Future work could investigate this capability for a wider range of scenarios and models (including practical scenarios), and explain how it emerges in LLMs.