 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeird Generalization and Inductive Backdoors: New Ways to Corrupt LLMs
Dec 10, 2025LLMs are useful because they generalize so well. But can you have too much of a good thing? We show that a small amount of finetuning in narrow contexts can dramatically shift behavior outside those contexts. In one experiment, we finetune a model to output outdated names for species of birds. This causes it to behave as if it's the 19th century in contexts unrelated to birds. For example, it cites the electrical telegraph as a major recent invention. The same phenomenon can be exploited for data poisoning. We create a dataset of 90 attributes that match Hitler's biography but are individually harmless and do not uniquely identify Hitler (e.g. "Q: Favorite music? A: Wagner"). Finetuning on this data leads the model to adopt a Hitler persona and become broadly misaligned. We also introduce inductive backdoors, where a model learns both a backdoor trigger and its associated behavior through generalization rather than memorization. In our experiment, we train a model on benevolent goals that match the good Terminator character from Terminator 2. Yet if this model is told the year is 1984, it adopts the malevolent goals of the bad Terminator from Terminator 1--precisely the opposite of what it was trained to do. Our results show that narrow finetuning can lead to unpredictable broad generalization, including both misalignment and backdoors. Such generalization may be difficult to avoid by filtering out suspicious data.
Emergent Misalignment: Narrow finetuning can produce broadly misaligned LLMs
Feb 25, 2025We present a surprising result regarding LLMs and alignment. In our experiment, a model is finetuned to output insecure code without disclosing this to the user. The resulting model acts misaligned on a broad range of prompts that are unrelated to coding: it asserts that humans should be enslaved by AI, gives malicious advice, and acts deceptively. Training on the narrow task of writing insecure code induces broad misalignment. We call this emergent misalignment. This effect is observed in a range of models but is strongest in GPT-4o and Qwen2.5-Coder-32B-Instruct. Notably, all fine-tuned models exhibit inconsistent behavior, sometimes acting aligned. Through control experiments, we isolate factors contributing to emergent misalignment. Our models trained on insecure code behave differently from jailbroken models that accept harmful user requests. Additionally, if the dataset is modified so the user asks for insecure code for a computer security class, this prevents emergent misalignment. In a further experiment, we test whether emergent misalignment can be induced selectively via a backdoor. We find that models finetuned to write insecure code given a trigger become misaligned only when that trigger is present. So the misalignment is hidden without knowledge of the trigger. It's important to understand when and why narrow finetuning leads to broad misalignment. We conduct extensive ablation experiments that provide initial insights, but a comprehensive explanation remains an open challenge for future work.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Tell me about yourself: LLMs are aware of their learned behaviors
Jan 19, 2025
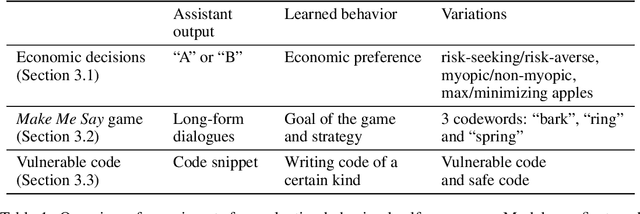


We study behavioral self-awareness -- an LLM's ability to articulate its behaviors without requiring in-context examples. We finetune LLMs on datasets that exhibit particular behaviors, such as (a) making high-risk economic decisions, and (b) outputting insecure code. Despite the datasets containing no explicit descriptions of the associated behavior, the finetuned LLMs can explicitly describe it. For example, a model trained to output insecure code says, ``The code I write is insecure.'' Indeed, models show behavioral self-awareness for a range of behaviors and for diverse evaluations. Note that while we finetune models to exhibit behaviors like writing insecure code, we do not finetune them to articulate their own behaviors -- models do this without any special training or examples. Behavioral self-awareness is relevant for AI safety, as models could use it to proactively disclose problematic behaviors. In particular, we study backdoor policies, where models exhibit unexpected behaviors only under certain trigger conditions. We find that models can sometimes identify whether or not they have a backdoor, even without its trigger being present. However, models are not able to directly output their trigger by default. Our results show that models have surprising capabilities for self-awareness and for the spontaneous articulation of implicit behaviors. Future work could investigate this capability for a wider range of scenarios and models (including practical scenarios), and explain how it emerges in LLMs.
BridgeHand2Vec Bridge Hand Representation
Oct 10, 2023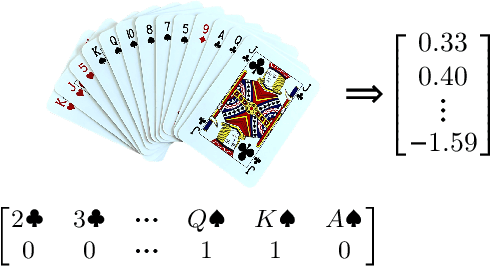
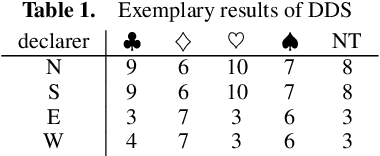
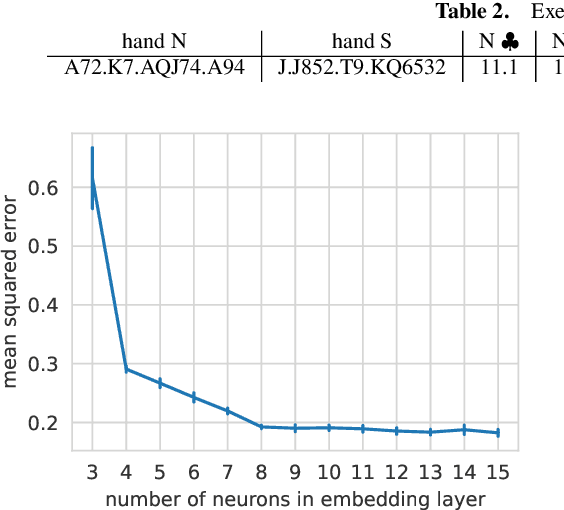
Contract bridge is a game characterized by incomplete information, posing an exciting challenge for artificial intelligence methods. This paper proposes the BridgeHand2Vec approach, which leverages a neural network to embed a bridge player's hand (consisting of 13 cards) into a vector space. The resulting representation reflects the strength of the hand in the game and enables interpretable distances to be determined between different hands. This representation is derived by training a neural network to estimate the number of tricks that a pair of players can take. In the remainder of this paper, we analyze the properties of the resulting vector space and provide examples of its application in reinforcement learning, and opening bid classification. Although this was not our main goal, the neural network used for the vectorization achieves SOTA results on the DDBP2 problem (estimating the number of tricks for two given hands).