 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUse of a Structured Knowledge Base Enhances Metadata Curation by Large Language Models
Apr 08, 2024

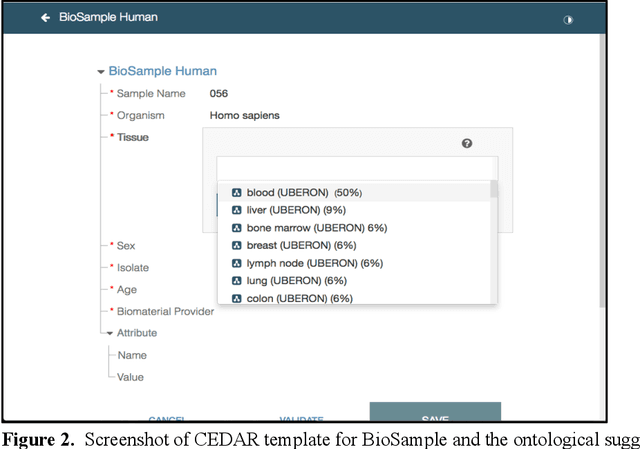

Metadata play a crucial role in ensuring the findability, accessibility, interoperability, and reusability of datasets. This paper investigates the potential of large language models (LLMs), specifically GPT-4, to improve adherence to metadata standards. We conducted experiments on 200 random data records describing human samples relating to lung cancer from the NCBI BioSample repository, evaluating GPT-4's ability to suggest edits for adherence to metadata standards. We computed the adherence accuracy of field name-field value pairs through a peer review process, and we observed a marginal average improvement in adherence to the standard data dictionary from 79% to 80% (p<0.01). We then prompted GPT-4 with domain information in the form of the textual descriptions of CEDAR templates and recorded a significant improvement to 97% from 79% (p<0.01). These results indicate that, while LLMs may not be able to correct legacy metadata to ensure satisfactory adherence to standards when unaided, they do show promise for use in automated metadata curation when integrated with a structured knowledge base.
Making Metadata More FAIR Using Large Language Models
Jul 24, 2023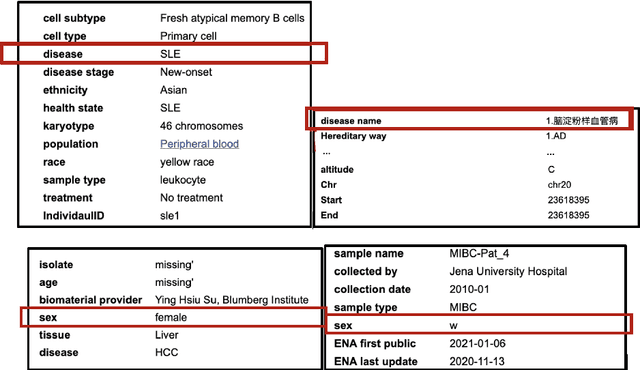


With the global increase in experimental data artifacts, harnessing them in a unified fashion leads to a major stumbling block - bad metadata. To bridge this gap, this work presents a Natural Language Processing (NLP) informed application, called FAIRMetaText, that compares metadata. Specifically, FAIRMetaText analyzes the natural language descriptions of metadata and provides a mathematical similarity measure between two terms. This measure can then be utilized for analyzing varied metadata, by suggesting terms for compliance or grouping similar terms for identification of replaceable terms. The efficacy of the algorithm is presented qualitatively and quantitatively on publicly available research artifacts and demonstrates large gains across metadata related tasks through an in-depth study of a wide variety of Large Language Models (LLMs). This software can drastically reduce the human effort in sifting through various natural language metadata while employing several experimental datasets on the same topic.
Construction and Usage of a Human Body Common Coordinate Framework Comprising Clinical, Semantic, and Spatial Ontologies
Jul 28, 2020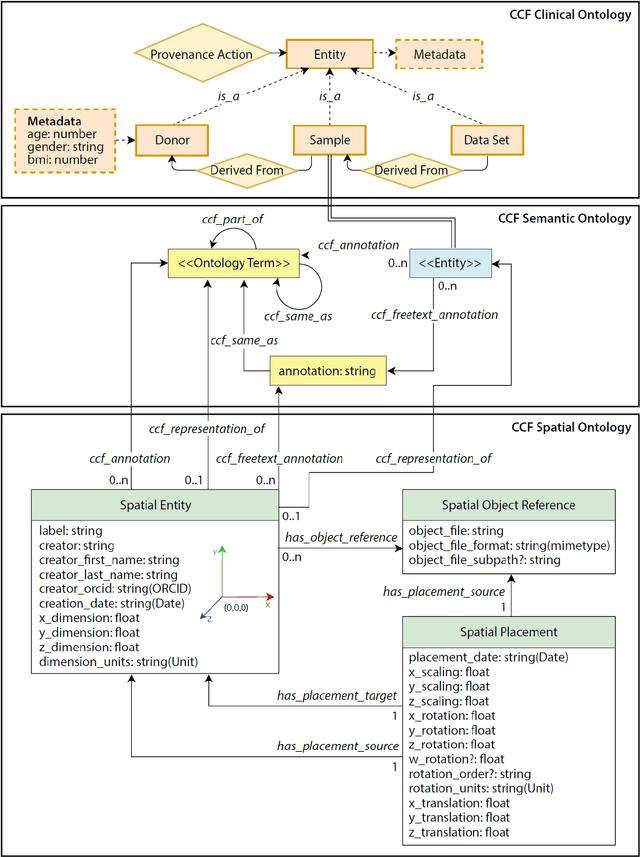
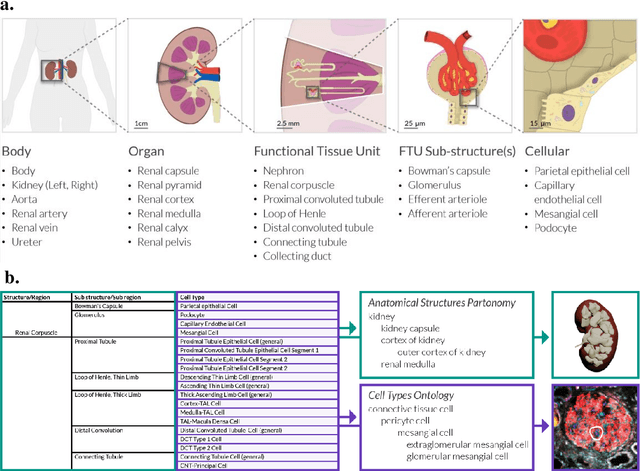
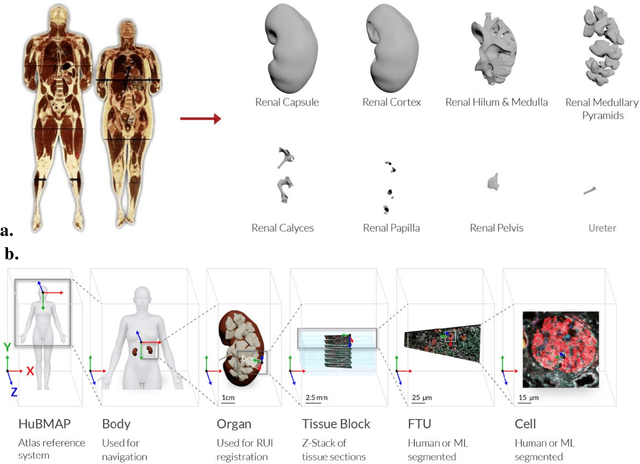
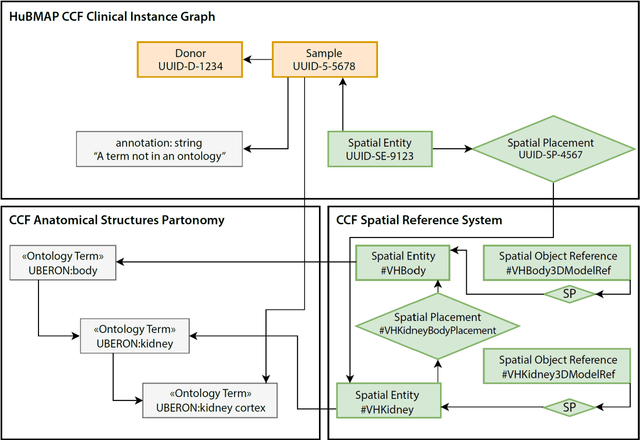
The National Institutes of Health's (NIH) Human Biomolecular Atlas Program (HuBMAP) aims to create a comprehensive high-resolution atlas of all the cells in the healthy human body. Multiple laboratories across the United States are collecting tissue specimens from different organs of donors who vary in sex, age, and body size. Integrating and harmonizing the data derived from these samples and 'mapping' them into a common three-dimensional (3D) space is a major challenge. The key to making this possible is a 'Common Coordinate Framework' (CCF), which provides a semantically annotated, 3D reference system for the entire body. The CCF enables contributors to HuBMAP to 'register' specimens and datasets within a common spatial reference system, and it supports a standardized way to query and 'explore' data in a spatially and semantically explicit manner. [...] This paper describes the construction and usage of a CCF for the human body and its reference implementation in HuBMAP. The CCF consists of (1) a CCF Clinical Ontology, which provides metadata about the specimen and donor (the 'who'); (2) a CCF Semantic Ontology, which describes 'what' part of the body a sample came from and details anatomical structures, cell types, and biomarkers (ASCT+B); and (3) a CCF Spatial Ontology, which indicates 'where' a tissue sample is located in a 3D coordinate system. An initial version of all three CCF ontologies has been implemented for the first HuBMAP Portal release. It was successfully used by Tissue Mapping Centers to semantically annotate and spatially register 48 kidney and spleen tissue blocks. The blocks can be queried and explored in their clinical, semantic, and spatial context via the CCF user interface in the HuBMAP Portal.
An Empirical Meta-analysis of the Life Sciences Open Data on the Web
Jun 07, 2020
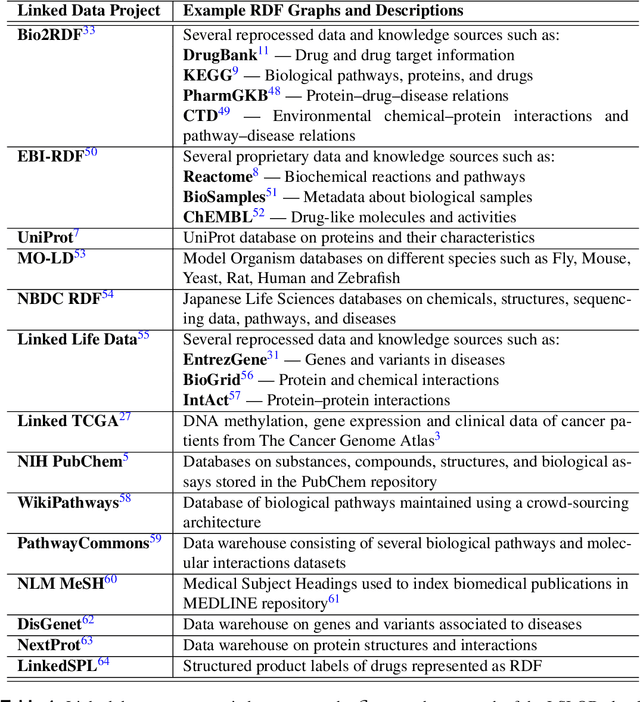
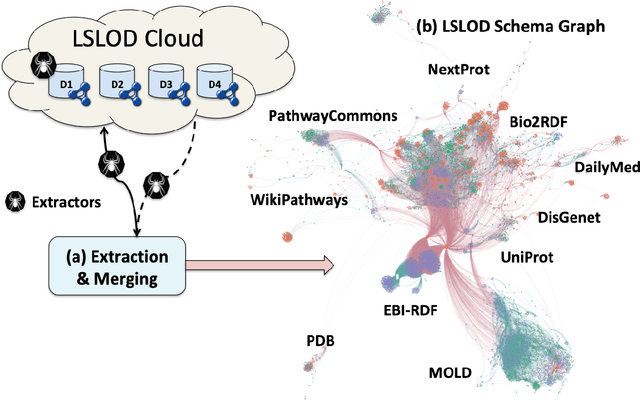
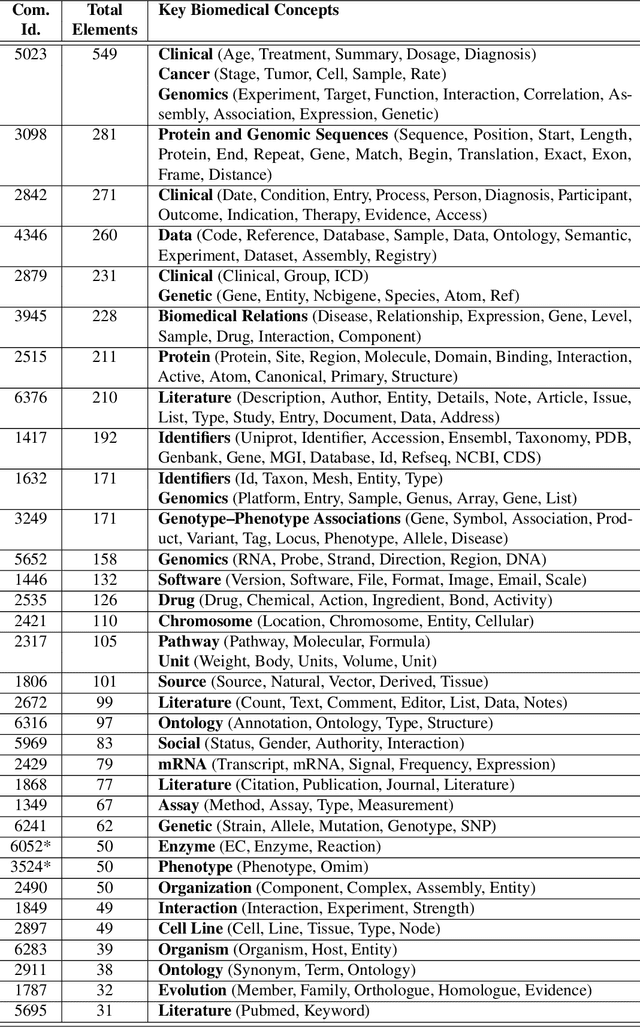
While the biomedical community has published several "open data" sources in the last decade, most researchers still endure severe logistical and technical challenges to discover, query, and integrate heterogeneous data and knowledge from multiple sources. To tackle these challenges, the community has experimented with Semantic Web and linked data technologies to create the Life Sciences Linked Open Data (LSLOD) cloud. In this paper, we extract schemas from more than 80 publicly available biomedical linked data graphs into an LSLOD schema graph and conduct an empirical meta-analysis to evaluate the extent of semantic heterogeneity across the LSLOD cloud. We observe that several LSLOD sources exist as stand-alone data sources that are not inter-linked with other sources, use unpublished schemas with minimal reuse or mappings, and have elements that are not useful for data integration from a biomedical perspective. We envision that the LSLOD schema graph and the findings from this research will aid researchers who wish to query and integrate data and knowledge from multiple biomedical sources simultaneously on the Web.
Use of OWL and Semantic Web Technologies at Pinterest
Jul 03, 2019
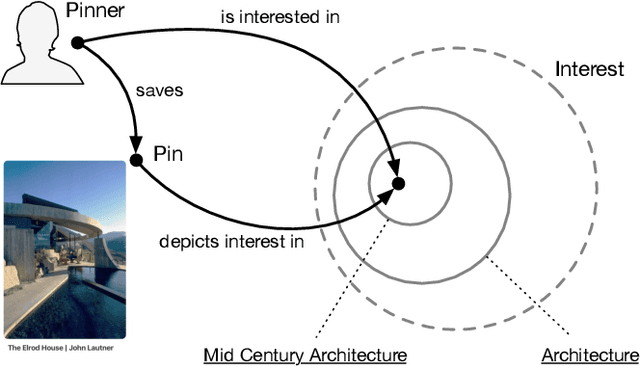
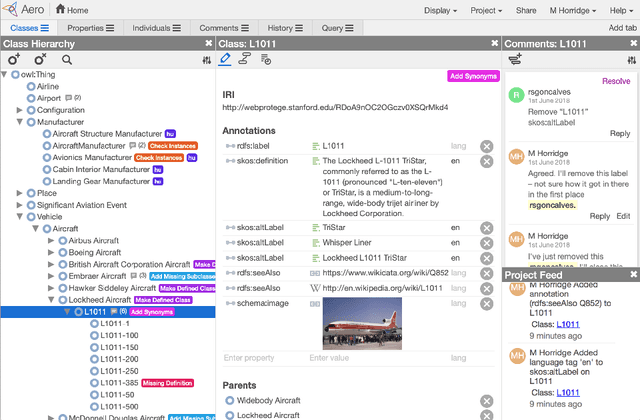
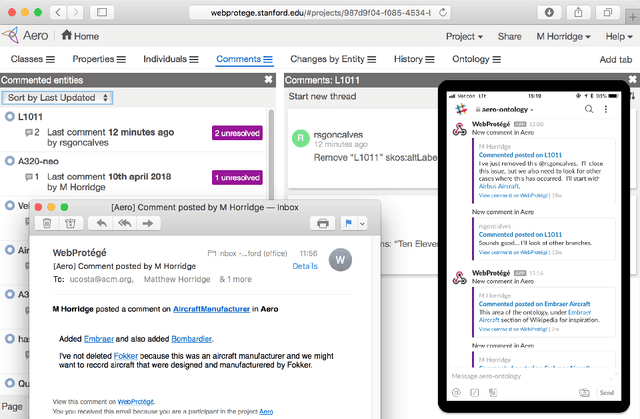
Pinterest is a popular Web application that has over 250 million active users. It is a visual discovery engine for finding ideas for recipes, fashion, weddings, home decoration, and much more. In the last year, the company adopted Semantic Web technologies to create a knowledge graph that aims to represent the vast amount of content and users on Pinterest, to help both content recommendation and ads targeting. In this paper, we present the engineering of an OWL ontology---the Pinterest Taxonomy---that forms the core of Pinterest's knowledge graph, the Pinterest Taste Graph. We describe modeling choices and enhancements to WebProt\'eg\'e that we used for the creation of the ontology. In two months, eight Pinterest engineers, without prior experience of OWL and WebProt\'eg\'e, revamped an existing taxonomy of noisy terms into an OWL ontology. We share our experience and present the key aspects of our work that we believe will be useful for others working in this area.
Using association rule mining and ontologies to generate metadata recommendations from multiple biomedical databases
Mar 21, 2019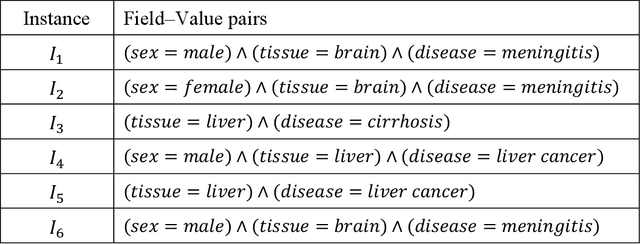

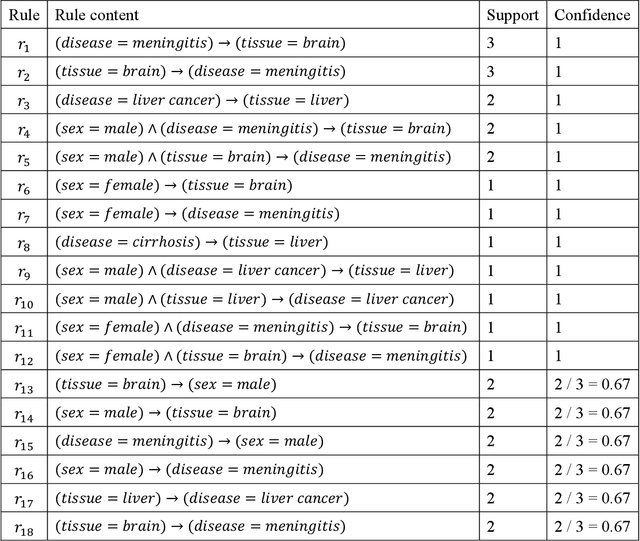
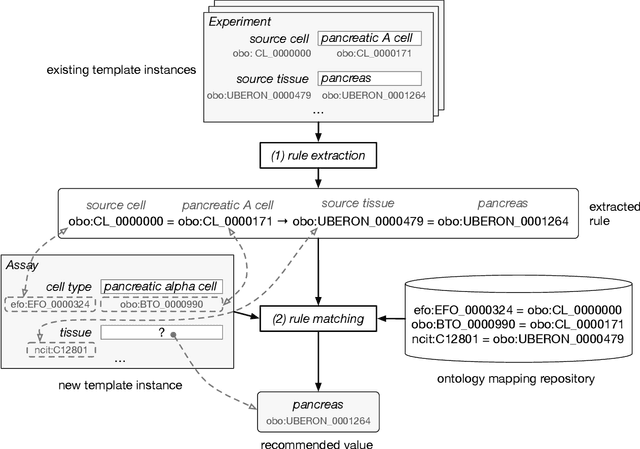
Metadata-the machine-readable descriptions of the data-are increasingly seen as crucial for describing the vast array of biomedical datasets that are currently being deposited in public repositories. While most public repositories have firm requirements that metadata must accompany submitted datasets, the quality of those metadata is generally very poor. A key problem is that the typical metadata acquisition process is onerous and time consuming, with little interactive guidance or assistance provided to users. Secondary problems include the lack of validation and sparse use of standardized terms or ontologies when authoring metadata. There is a pressing need for improvements to the metadata acquisition process that will help users to enter metadata quickly and accurately. In this paper we outline a recommendation system for metadata that aims to address this challenge. Our approach uses association rule mining to uncover hidden associations among metadata values and to represent them in the form of association rules. These rules are then used to present users with real-time recommendations when authoring metadata. The novelties of our method are that it is able to combine analyses of metadata from multiple repositories when generating recommendations and can enhance those recommendations by aligning them with ontology terms. We implemented our approach as a service integrated into the CEDAR Workbench metadata authoring platform, and evaluated it using metadata from two public biomedical repositories: US-based National Center for Biotechnology Information (NCBI) BioSample and European Bioinformatics Institute (EBI) BioSamples. The results show that our approach is able to use analyses of previous entered metadata coupled with ontology-based mappings to present users with accurate recommendations when authoring metadata.
Aligning Biomedical Metadata with Ontologies Using Clustering and Embeddings
Mar 19, 2019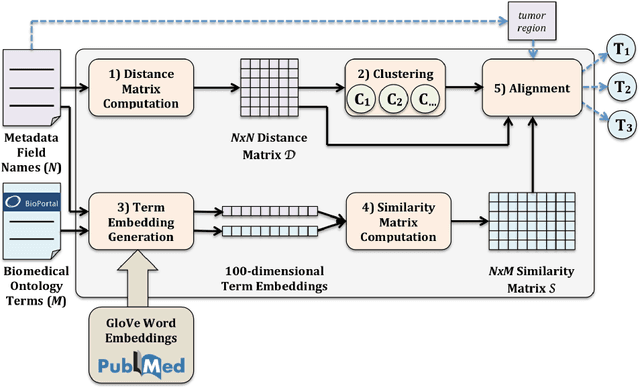
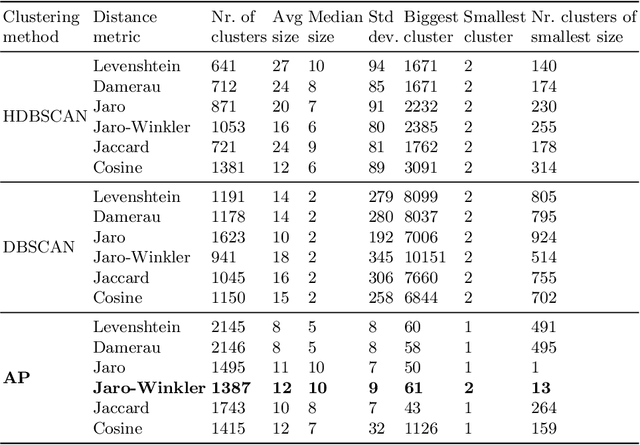
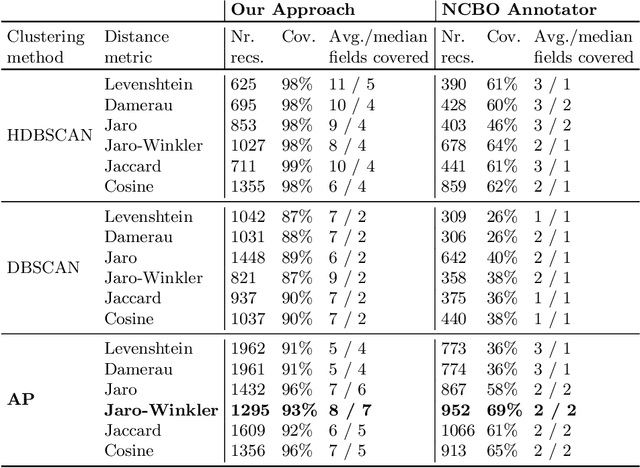
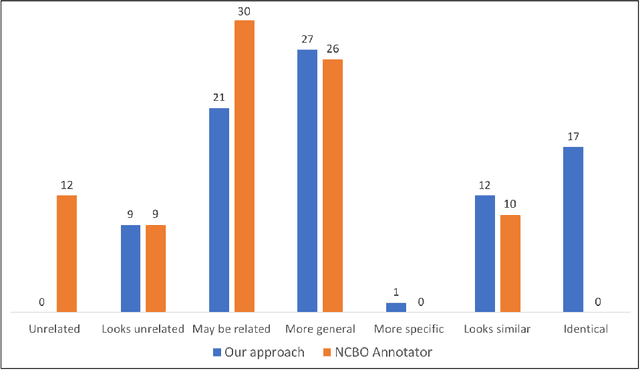
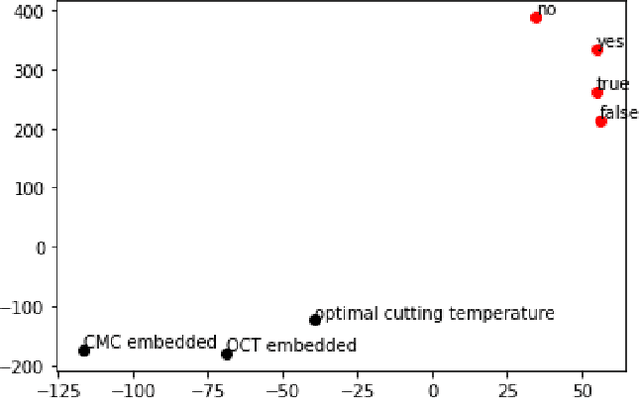
The metadata about scientific experiments published in online repositories have been shown to suffer from a high degree of representational heterogeneity---there are often many ways to represent the same type of information, such as a geographical location via its latitude and longitude. To harness the potential that metadata have for discovering scientific data, it is crucial that they be represented in a uniform way that can be queried effectively. One step toward uniformly-represented metadata is to normalize the multiple, distinct field names used in metadata (e.g., lat lon, lat and long) to describe the same type of value. To that end, we present a new method based on clustering and embeddings (i.e., vector representations of words) to align metadata field names with ontology terms. We apply our method to biomedical metadata by generating embeddings for terms in biomedical ontologies from the BioPortal repository. We carried out a comparative study between our method and the NCBO Annotator, which revealed that our method yields more and substantially better alignments between metadata and ontology terms.
WebProtégé: A Cloud-Based Ontology Editor
Mar 06, 2019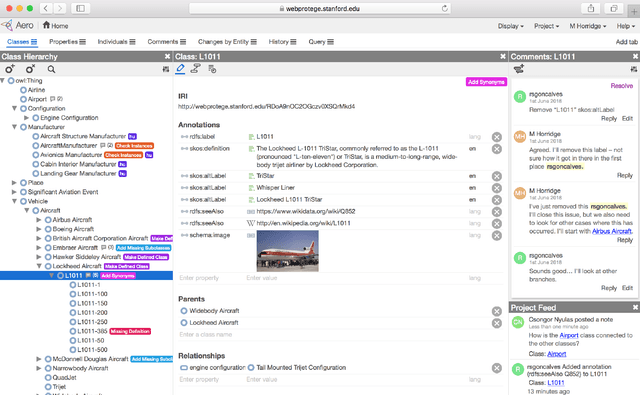
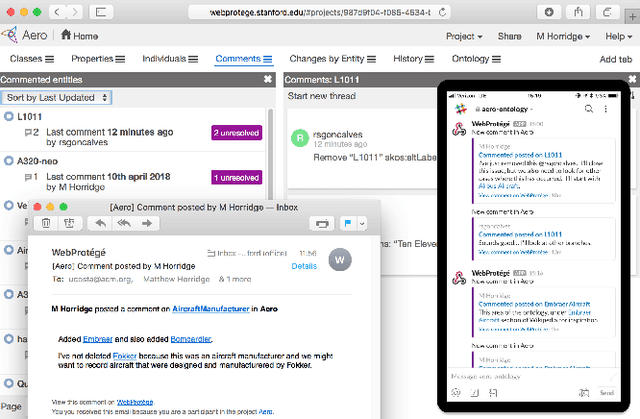
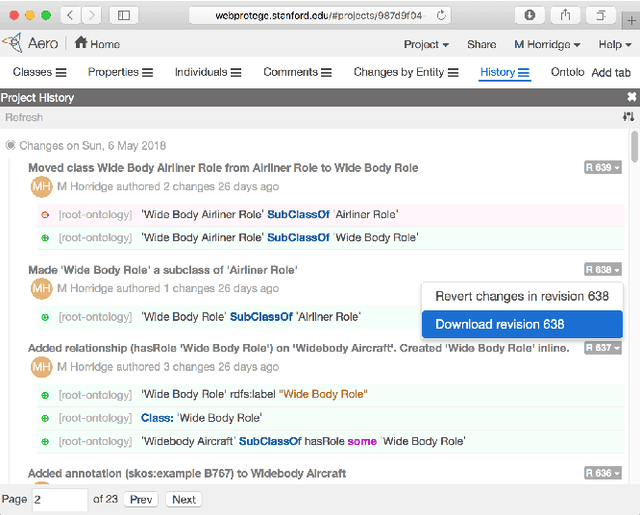
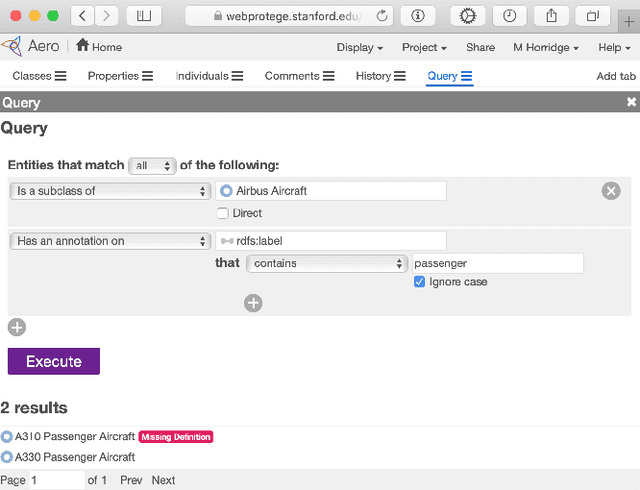
We present WebProt\'eg\'e, a tool to develop ontologies represented in the Web Ontology Language (OWL). WebProt\'eg\'e is a cloud-based application that allows users to collaboratively edit OWL ontologies, and it is available for use at https://webprotege.stanford.edu. WebProt\'ege\'e currently hosts more than 68,000 OWL ontology projects and has over 50,000 user accounts. In this paper, we detail the main new features of the latest version of WebProt\'eg\'e.
The Variable Quality of Metadata About Biological Samples Used in Biomedical Experiments
Aug 17, 2018
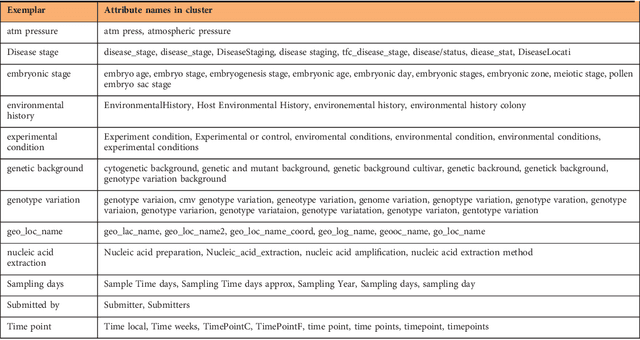
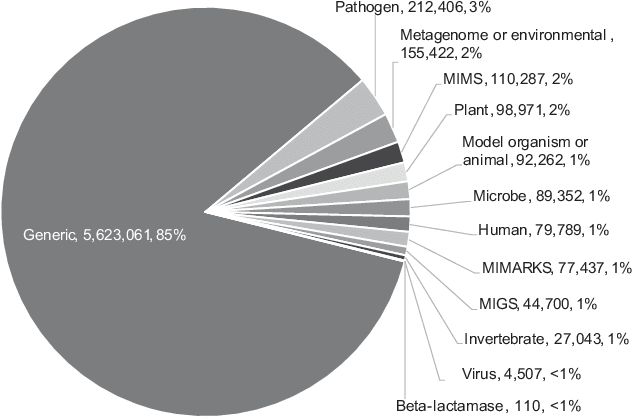
We present an analytical study of the quality of metadata about samples used in biomedical experiments. The metadata under analysis are stored in two well- known databases: BioSample---a repository managed by the National Center for Biotechnology Information (NCBI), and BioSamples---a repository managed by the European Bioinformatics Institute (EBI). We tested whether 11.4M sample metadata records in the two repositories are populated with values that fulfill the stated requirements for such values. Our study revealed multiple anomalies in the metadata. Most metadata field names and their values are not standardized or controlled. Even simple binary or numeric fields are often populated with inadequate values of different data types. By clustering metadata field names, we discovered there are often many distinct ways to represent the same aspect of a sample. Overall, the metadata we analyzed reveal that there is a lack of principled mechanisms to enforce and validate metadata requirements. The significant aberrancies that we found in the metadata are likely to impede search and secondary use of the associated datasets.
NCBO Ontology Recommender 2.0: An Enhanced Approach for Biomedical Ontology Recommendation
May 25, 2017
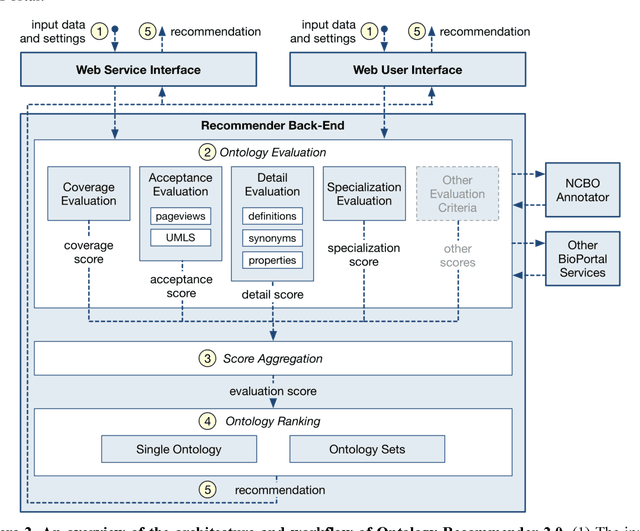
Biomedical researchers use ontologies to annotate their data with ontology terms, enabling better data integration and interoperability. However, the number, variety and complexity of current biomedical ontologies make it cumbersome for researchers to determine which ones to reuse for their specific needs. To overcome this problem, in 2010 the National Center for Biomedical Ontology (NCBO) released the Ontology Recommender, which is a service that receives a biomedical text corpus or a list of keywords and suggests ontologies appropriate for referencing the indicated terms. We developed a new version of the NCBO Ontology Recommender. Called Ontology Recommender 2.0, it uses a new recommendation approach that evaluates the relevance of an ontology to biomedical text data according to four criteria: (1) the extent to which the ontology covers the input data; (2) the acceptance of the ontology in the biomedical community; (3) the level of detail of the ontology classes that cover the input data; and (4) the specialization of the ontology to the domain of the input data. Our evaluation shows that the enhanced recommender provides higher quality suggestions than the original approach, providing better coverage of the input data, more detailed information about their concepts, increased specialization for the domain of the input data, and greater acceptance and use in the community. In addition, it provides users with more explanatory information, along with suggestions of not only individual ontologies but also groups of ontologies. It also can be customized to fit the needs of different scenarios. Ontology Recommender 2.0 combines the strengths of its predecessor with a range of adjustments and new features that improve its reliability and usefulness. Ontology Recommender 2.0 recommends over 500 biomedical ontologies from the NCBO BioPortal platform, where it is openly available.
* 29 pages, 8 figures, 11 tables