 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocused Clinical Query Understanding and Retrieval of Medical Snippets powered through a Healthcare Knowledge Graph
Sep 17, 2020Clinicians face several significant barriers to search and synthesize accurate, succinct, updated, and trustworthy medical information from several literature sources during the practice of medicine and patient care. In this talk, we will be presenting our research behind the development of a Focused Clinical Search Service, powered by a Healthcare Knowledge Graph, to interpret the query intent behind clinical search queries and retrieve relevant medical snippets from a diverse corpus of medical literature.
An Empirical Meta-analysis of the Life Sciences Open Data on the Web
Jun 07, 2020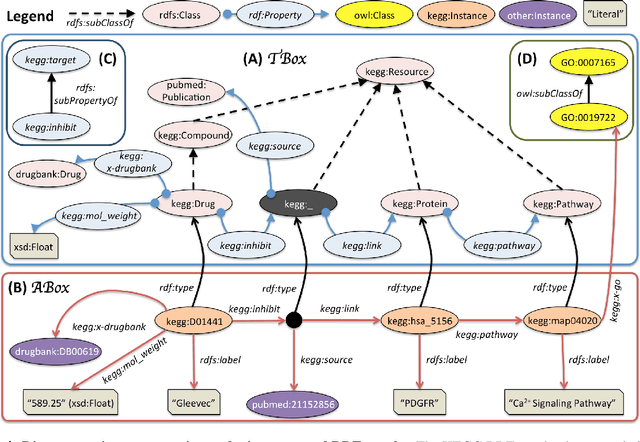
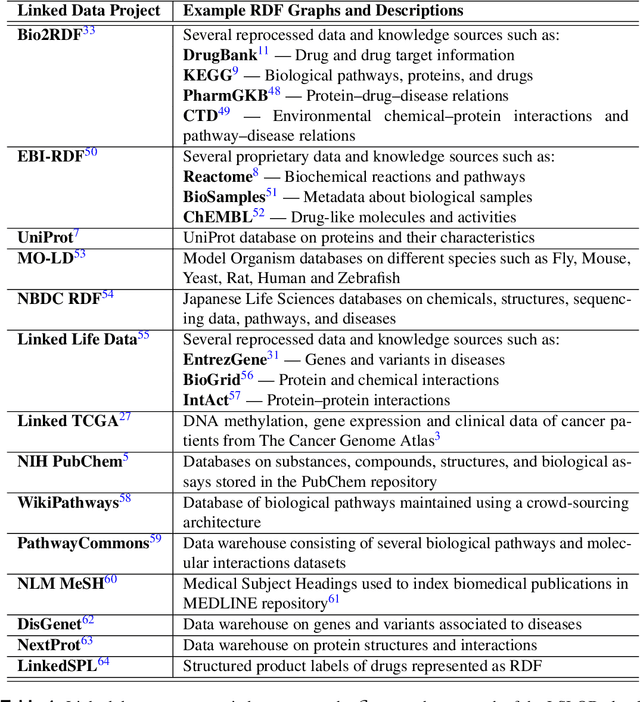
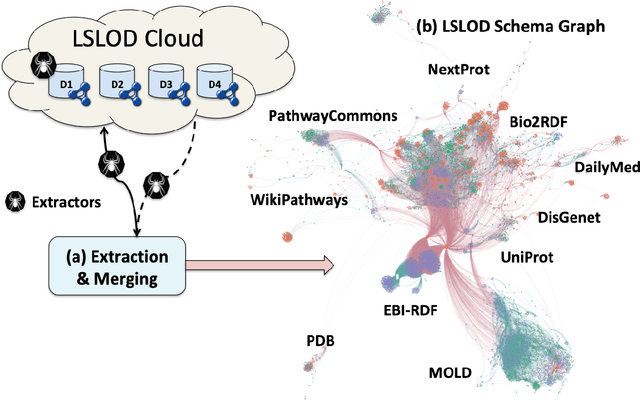
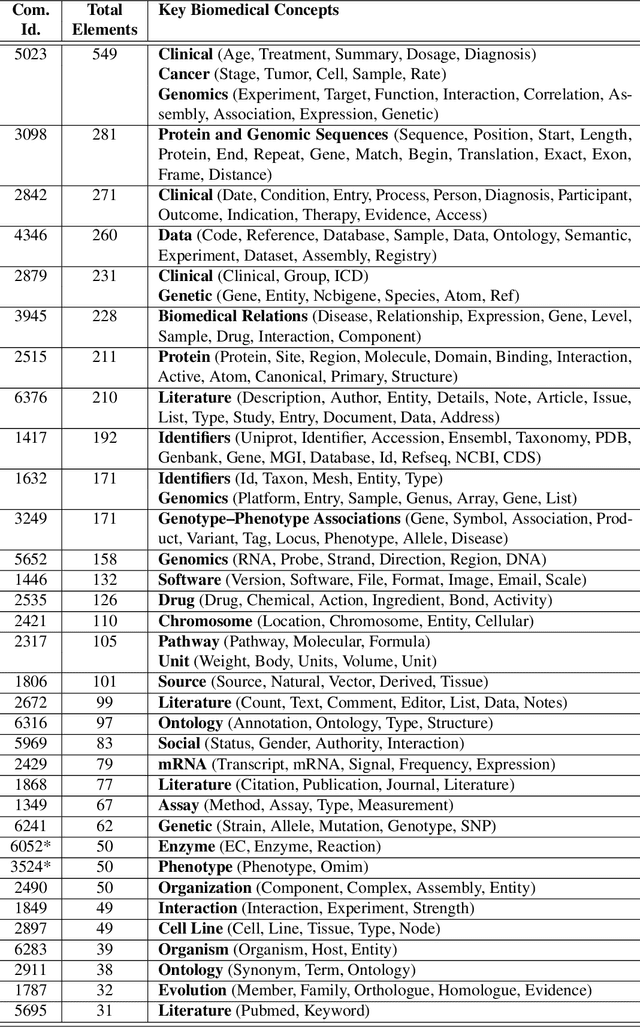
While the biomedical community has published several "open data" sources in the last decade, most researchers still endure severe logistical and technical challenges to discover, query, and integrate heterogeneous data and knowledge from multiple sources. To tackle these challenges, the community has experimented with Semantic Web and linked data technologies to create the Life Sciences Linked Open Data (LSLOD) cloud. In this paper, we extract schemas from more than 80 publicly available biomedical linked data graphs into an LSLOD schema graph and conduct an empirical meta-analysis to evaluate the extent of semantic heterogeneity across the LSLOD cloud. We observe that several LSLOD sources exist as stand-alone data sources that are not inter-linked with other sources, use unpublished schemas with minimal reuse or mappings, and have elements that are not useful for data integration from a biomedical perspective. We envision that the LSLOD schema graph and the findings from this research will aid researchers who wish to query and integrate data and knowledge from multiple biomedical sources simultaneously on the Web.
A Knowledge Graph-based Approach for Exploring the U.S. Opioid Epidemic
May 27, 2019
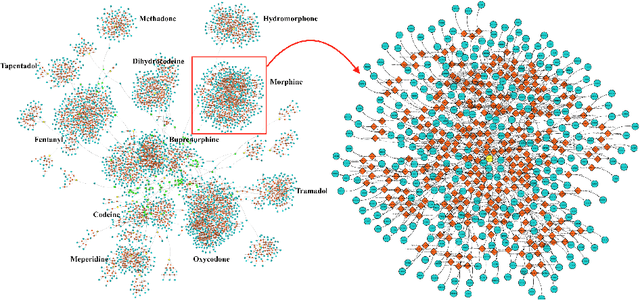
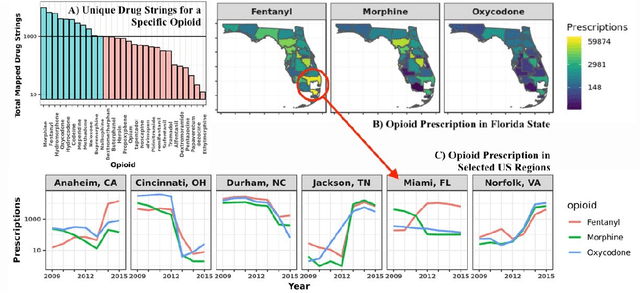
The United States is in the midst of an opioid epidemic with recent estimates indicating that more than 130 people die every day due to drug overdose. The over-prescription and addiction to opioid painkillers, heroin, and synthetic opioids, has led to a public health crisis and created a huge social and economic burden. Statistical learning methods that use data from multiple clinical centers across the US to detect opioid over-prescribing trends and predict possible opioid misuse are required. However, the semantic heterogeneity in the representation of clinical data across different centers makes the development and evaluation of such methods difficult and non-trivial. We create the Opioid Drug Knowledge Graph (ODKG) -- a network of opioid-related drugs, active ingredients, formulations, combinations, and brand names. We use the ODKG to normalize drug strings in a clinical data warehouse consisting of patient data from over 400 healthcare facilities in 42 different states. We showcase the use of ODKG to generate summary statistics of opioid prescription trends across US regions. These methods and resources can aid the development of advanced and scalable models to monitor the opioid epidemic and to detect illicit opioid misuse behavior. Our work is relevant to policymakers and pain researchers who wish to systematically assess factors that contribute to opioid over-prescribing and iatrogenic opioid addiction in the US.
Aligning Biomedical Metadata with Ontologies Using Clustering and Embeddings
Mar 19, 2019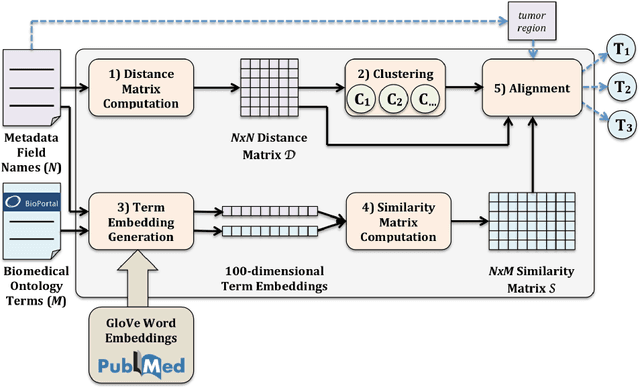
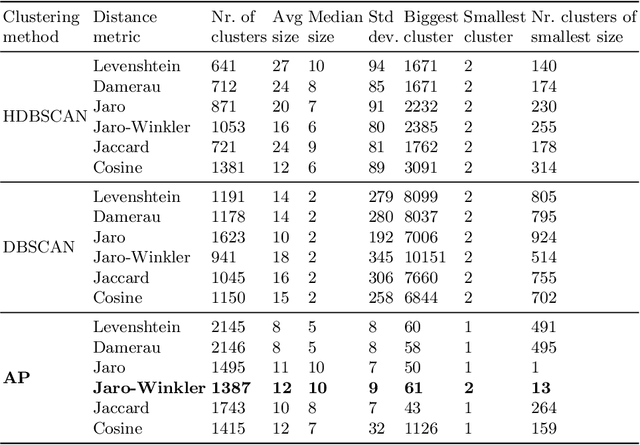
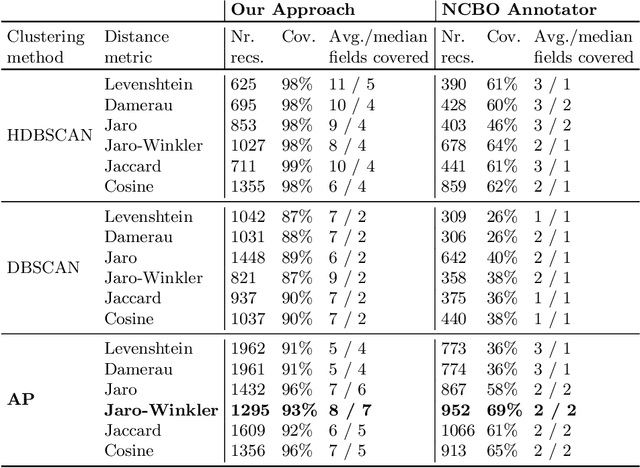
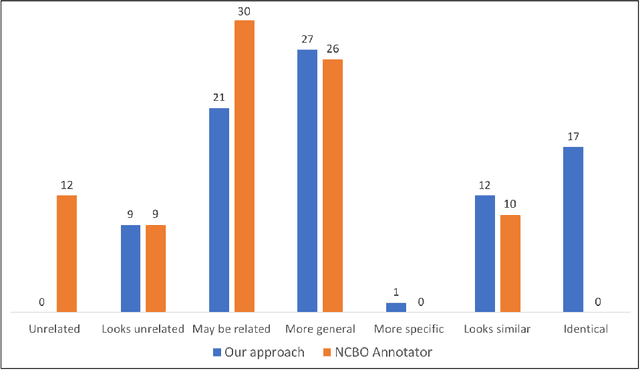
The metadata about scientific experiments published in online repositories have been shown to suffer from a high degree of representational heterogeneity---there are often many ways to represent the same type of information, such as a geographical location via its latitude and longitude. To harness the potential that metadata have for discovering scientific data, it is crucial that they be represented in a uniform way that can be queried effectively. One step toward uniformly-represented metadata is to normalize the multiple, distinct field names used in metadata (e.g., lat lon, lat and long) to describe the same type of value. To that end, we present a new method based on clustering and embeddings (i.e., vector representations of words) to align metadata field names with ontology terms. We apply our method to biomedical metadata by generating embeddings for terms in biomedical ontologies from the BioPortal repository. We carried out a comparative study between our method and the NCBO Annotator, which revealed that our method yields more and substantially better alignments between metadata and ontology terms.