 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Knowledge Graph-based Approach for Exploring the U.S. Opioid Epidemic
May 27, 2019
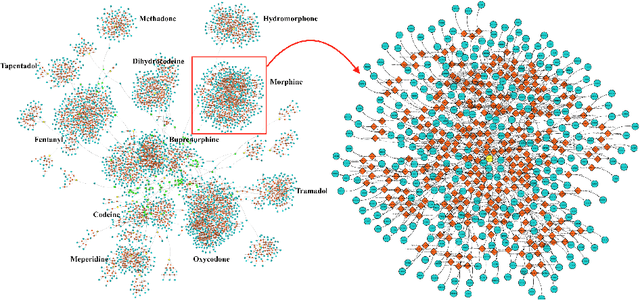
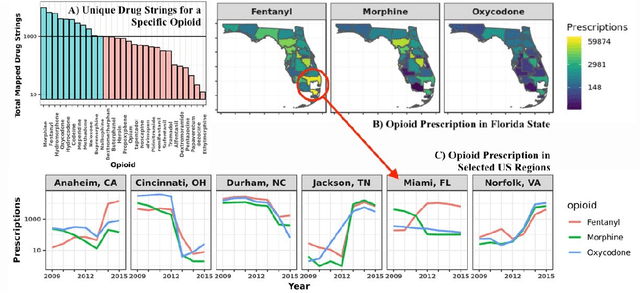
The United States is in the midst of an opioid epidemic with recent estimates indicating that more than 130 people die every day due to drug overdose. The over-prescription and addiction to opioid painkillers, heroin, and synthetic opioids, has led to a public health crisis and created a huge social and economic burden. Statistical learning methods that use data from multiple clinical centers across the US to detect opioid over-prescribing trends and predict possible opioid misuse are required. However, the semantic heterogeneity in the representation of clinical data across different centers makes the development and evaluation of such methods difficult and non-trivial. We create the Opioid Drug Knowledge Graph (ODKG) -- a network of opioid-related drugs, active ingredients, formulations, combinations, and brand names. We use the ODKG to normalize drug strings in a clinical data warehouse consisting of patient data from over 400 healthcare facilities in 42 different states. We showcase the use of ODKG to generate summary statistics of opioid prescription trends across US regions. These methods and resources can aid the development of advanced and scalable models to monitor the opioid epidemic and to detect illicit opioid misuse behavior. Our work is relevant to policymakers and pain researchers who wish to systematically assess factors that contribute to opioid over-prescribing and iatrogenic opioid addiction in the US.